When deploying new Kafka cluster, one of the first decisions you have to make is the type of storage you want to use. Even before deciding on such storage aspects such as the type of filesystem which should be used, you have to decide a more basic question: should you run Kafka with local storage or with network attached storage?
Local versus network storage
For a lot of stateful applications, Network Attached Storage (NAS) is often seen as the prefered choice. It often promises higher reliability and great performance. It is also easy to reattach to another machine when needed (for example because the original machine died). But Network Attached Storage has also some drawbacks. For example, to achive good and reliable performance it requires a very good network.
But Kafka doesn’t really need network attached storage. In fact, a lot of people would tell you that they prefer to use Kafka with local storage. Topic replication can be used to achieve high availablity and data durability without expensive storage. All Kafka records will be shared between several nodes and when one of them crashes or dies, another can take over. This can be done easily even with the (often much cheaper) local storage.
Kubernetes storage
When running Kafka on bare metal or on virtual machines, both local as well as network attached storage are quite easy to use. In fact, whatever storage is supported by your operating system will work. But what if you are running Kafka on Kubernetes or on OpenShift platforms? You need to use the storage as supported by your platform.
Kubernetes for a long time supported two kinds of storage:
- Persistent network attached storage
- Local ephemeral storage
Each behaves a bit differently when your Pods with kafka brokers are rescheduled or when the node they are running on fails. The persistent network attached storage is not tied to any particular node. So when the node where your Kafka broker is running suddenly crashes, Kubernetes will be able to reallocate your broker to a different node in your cluster. This usually takes between several seconds and several minutes, depending on your cloud provider and storage implementation. The persistent volume with the data used by the given broker will be reattached to the new node as well. So when the broker starts, it will find the same data which it used before. It will need to resync the partitions which it hosts, but it doesn’t need to start from scratch. It has to resync only the records which it missed during the failover.
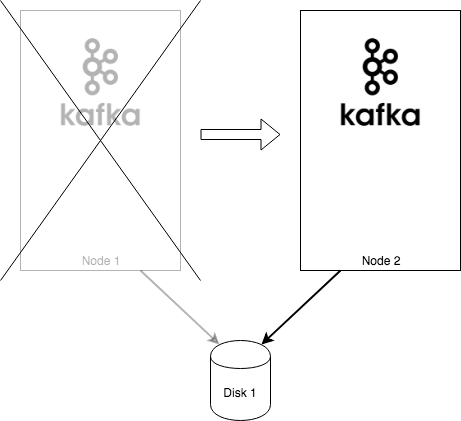
The ephemeral storage behaves differently. An ephemeral volume is usually just a directory somewhere in the host operating system of your node. It behaves very similarly to a temporary directory. When your Kafka broker is scheduled to a node, it can use the ephemeral volume and store data in it. But when the node crashes or the Pod is rescheduled, it will receive a new ephemeral disk which will not contain the previously stored data. It will start with an empty volume. It will therefore need to resync all its messages from one of the other replicas. Depending on the size of your partitions, this could take a very long time. Even if the original node was just restarted, the data stored in ephemeral volume usually do not survive the restart. The Pod with your broker will also usually not wait for the node to come back online and it will be started on another node.
The choice between persistent network attached storage and ephemeral local storage is hard. But often - especially with large brokers storing terabytes of data - the persistent network attached storage can be seen as the better option. But in the last versions, Kubernetes added support for the Local storage type. How good match is Local storage for Kafka?
Local persistent storage
Local storage offers persistent volumes which are tied to a particular host. It is currently in a beta version. Features in beta release usually tend to be fairly stable and work very well. But there is no guarantee that they will not change before graduating from beta. If you want to find out more about the Local storage type and how to use it, this post might be a good way to get started.
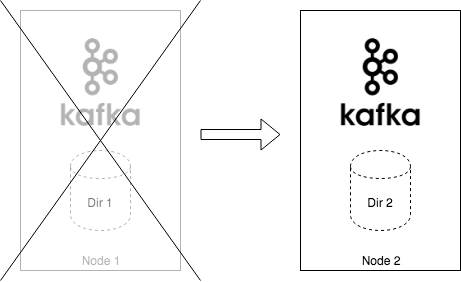
Local storage, to some extent, combines the best of both worlds. It is using storage which is locally attached to the node but it is persistent. So when the node restarts, the data which were stored on it survive. Additionally, since the Local volume is tied to a particular node, it will make sure that the Pod with your Kafka broker will not be rescheduled to another host. Kubernetes will wait until your node is back online and only then schedule the Kafka broker on it. When the broker is started, it will find the volume in the same state as it was left. It has to resync only the records which it missed during the failover - this is exactly the same as when you use persistent network attached storage.
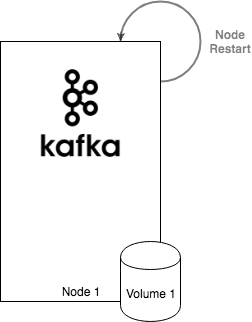
Now … what if your node is gone and will never return? In that case, you will need to make sure that the broker is scheduled on another node. Since the persistent volume was only local, it will be lost together with the node. Therefore the broker has to start from scratch and resync all data from another replica. This is the same as the local ephemeral storage case.
Local storage support in Strimzi
Strimzi is able to provision the storage for Kafka brokers in two forms:
- Ephemeral storage using the
emptyDirvolumes - Persistent storage using Persistent Volume Claims
Persistent Volume Claims use Storage Classes to dynamically create or assign persistent volumes and bind them to the Persistent Volume Claim.
This mechanism is today used to provision networked attached storage and use them with Kafka.
But the Local storage type is also using the Storage Class to do the binding.
Strimzi allows you to specify which Storage Class should be used to provision the storage.
So by specifying the right Storage Class you can use Local type volumes in Strimzi already today.
The example below shows the kafka-storage configuration using the Local persistent volumes in my Kubernetes cluster:
kafka-storage: |-
{
"type": "persistent-claim",
"size": "1000Gi",
"class": "local-storage"
}
When should Local storage be used
Local storage is definitely an important improvement to Kubernetes. But is it really a good idea to use it for Kafka?
When you are running your Kafka cluster on one of the three major public clouds providers, it might not be interesting. Regardless of whether you use Amazon AWS, Microsoft Azure or Google Cloud Platform, their network attached storage is able to deliver very good performance and their virtual machines are optimized for using it. On the other hand, machines with fast and large local storage are not that common and are not always cheaper than using network attached storage. Also the nodes of your Kubernetes cluster tend to be treated differently in public cloud. Instead of doing regular maintenance and restarting the nodes, it is often easier to just spin a new fresh node and kill the old one. And as explained in previous chapters, this approach works perfectly with the network attached storage. But doesn’t fit well with the Local storage, which will be lost during such operations.
On the other hand, when you run Kafka on Kubernetes or OpenShift installed on-premise in your own datacenter, the Local storage might be a real gamechanger. You will not need to invest in high performance storage network. You just attach the storage locally and use it. If you run Kubernetes or OpenShift on bare-metal, your cluster nodes will be also treated as personal resource. They will be regularly restarted for maintenance reasons, but will usually get back online after the maintenance is finished. But the node will disappear only when it really dies or when it needs to be replaced due to age. And the Local storage volumes which are tightly coupled with the node fit this approach very well.
Share this:
![]()
![]()
![]()
![]()
![]()