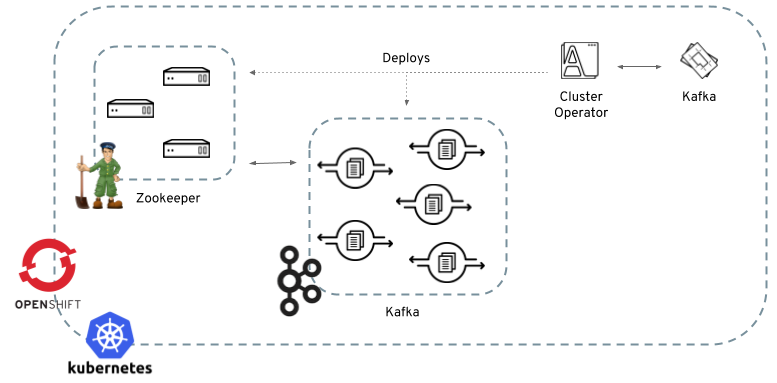
Strimzi provides a way to run an Apache Kafka cluster on OpenShift Origin or Kubernetes in various deployment configurations. This guide describes how to install and use Strimzi.
1. Overview
Apache Kafka is a popular platform for streaming data delivery and processing. For more details about Apache Kafka itself visit Apache Kafka website. The aim of Strimzi is to make it easy to run Apache Kafka on OpenShift or Kubernetes. Strimzi is based on Apache Kafka 1.1.0.
Strimzi consists of two main components:
- Cluster Operator
-
Responsible for deploying and managing Apache Kafka clusters within OpenShift or Kubernetes cluster.
- Topic Operator
-
Responsible for managing Kafka topics within a Kafka cluster running within OpenShift or Kubernetes cluster.
2. Getting started
2.1. Downloading Strimzi
Strimzi releases are available for download from GitHub. The release artifacts contain documentation and example YAML files for deployment on OpenShift or Kubernetes. The example files are used throughout this documentation and can be used to install Strimzi. The Docker images are available on Docker Hub.
2.2. Prerequisites
Strimzi runs on OpenShift or Kubernetes.
Strimzi supports
Kubernetes 1.9 and higher or
OpenShift Origin 3.9 and higher.
Strimzi works on all kinds of clusters - from public and private clouds down to local deployments intended for development.
This guide expects that an OpenShift or Kubernetes cluster is available and the
kubectl or
oc command line tools are installed and configured to connect to the running cluster.
When no existing OpenShift or Kubernetes cluster is available, Minikube or Minishift can be used to create a local
cluster. More details can be found in Installing OpenShift or Kubernetes cluster
In order to execute the commands in this guide, your OpenShift or Kubernetes user needs to have the rights to create and manage RBAC resources (Roles and Role Bindings).
2.3. Cluster Operator
Strimzi uses a component called the Cluster Operator to deploy and manage Kafka (including Zookeeper) and Kafka Connect
clusters.
The Cluster Operator is deployed as a process running inside your OpenShift or Kubernetes cluster.
To deploy a Kafka cluster, a Kafka resource with the cluster configuration has to be created within the OpenShift or Kubernetes cluster.
Based on the information in that Kafka resource,
the Cluster Operator will deploy a corresponding Kafka cluster.
The format of the Kafka resource is described in Format of the Kafka resource.
Strimzi contains example YAML files which make deploying a Cluster Operator easier.
2.3.1. Deploying to Kubernetes
To deploy the Cluster Operator on Kubernetes, you will first need to modify some of of the installation files according to the namespace the Cluster Operator is going to be installed in.
To do this, execute the following command, replacing <my-namespace> with the correct namespace:
sed -i 's/namespace: .*/namespace: <my-namespace>/' examples/install/cluster-operator/*ClusterRoleBinding*.yamlNext, the following commands should be executed:
kubectl create -f examples/install/cluster-operatorTo verify whether the Cluster Operator has been deployed successfully, the Kubernetes Dashboard or the following command can be used:
kubectl describe all2.3.2. Deploying to OpenShift
|
Important
|
To successfully deploy the Cluster Operator on OpenShift a user with cluster-admin role needs to be used (that is, like system:admin).
|
To deploy the Cluster Operator on OpenShift, you will first need to modify some of of the installation files according to the namespace the Cluster Operator is going to be installed in.
To do this, execute the following command, replacing <my-namespace> with the correct namespace:
sed -i 's/namespace: .*/namespace: <my-namespace>/' examples/install/cluster-operator/*ClusterRoleBinding*.yamlNext, the following commands should be executed:
oc create -f examples/install/cluster-operator
oc create -f examples/templates/cluster-operatorTo verify whether the Cluster Operator has been deployed successfully, the OpenShift console or the following command can be used:
oc describe all2.4. Kafka broker
Strimzi uses the StatefulSets feature of OpenShift or Kubernetes to deploy Kafka brokers. With StatefulSets, the pods receive a unique name and network identity and that makes it easier to identify the individual Kafka broker pods and set their identity (broker ID). The deployment uses regular and headless services:
-
regular services can be used as bootstrap servers for Kafka clients
-
headless services are needed to have DNS resolve the pods IP addresses directly
As well as Kafka, Strimzi also installs a Zookeeper cluster and configures the Kafka brokers to connect to it. The Zookeeper cluster also uses StatefulSets.
Strimzi provides two flavors of Kafka broker deployment: ephemeral and persistent.
The ephemeral flavour is suitable only for development and testing purposes and not for production. The
ephemeral flavour uses emptyDir volumes for storing broker information (Zookeeper) and topics/partitions
(Kafka). Using emptyDir volume means that its content is strictly related to the pod life cycle (it is
deleted when the pod goes down). This makes the in-memory deployment well-suited to development and testing because
you do not have to provide persistent volumes.
The persistent flavour uses PersistentVolumes to store Zookeeper and Kafka data. The PersistentVolume is acquired using a PersistentVolumeClaim – that makes it independent of the actual type of the PersistentVolume. For example, it can use HostPath volumes on Minikube or Amazon EBS volumes in Amazon AWS deployments without any changes in the YAML files. The PersistentVolumeClaim can use a StorageClass to trigger automatic volume provisioning.
To deploy a Kafka cluster, a Kafka resource with the cluster configuration has to be created.
Example resources and the details about the Kafka format are in Format of the Kafka resource.
2.4.1. Deploying to Kubernetes
To deploy a Kafka broker on Kubernetes, the corresponding Kafka has to be created.
To create an ephemeral cluster using the provided example Kafka, the following command should be executed:
kubectl apply -f examples/kafka/kafka-ephemeral.yamlAnother example Kafka is provided for a persistent Kafka cluster.
To deploy it, the following command should be run:
kubectl apply -f examples/kafka/kafka-persistent.yaml2.4.2. Deploying to OpenShift
For OpenShift, the Kafka broker is provided in the form of a template. The cluster can be deployed from the template either using the command line or using the OpenShift console. To create the ephemeral cluster, the following command should be executed:
oc new-app strimzi-ephemeralSimilarly, to deploy a persistent Kafka cluster the following command should be run:
oc new-app strimzi-persistent2.5. Kafka Connect
The Cluster Operator can also deploy a Kafka Connect cluster which can be used with either of the Kafka broker deployments described above.
It is implemented as a Deployment with a configurable number of workers.
The default image currently contains only the Connectors distributed with Apache Kafka Connect: FileStreamSinkConnector and FileStreamSourceConnector.
The REST interface for managing the Kafka Connect cluster is exposed internally within the OpenShift or Kubernetes cluster as kafka-connect service on port 8083.
Example KafkaConnect resources and the details about the KafkaConnect format for deploying Kafka Connect can be found in
Kafka Connect.
2.5.1. Deploying to Kubernetes
To deploy Kafka Connect on Kubernetes, the corresponding KafkaConnect resource has to be created.
An example resource can be created using the following command:
kubectl apply -f examples/kafka-connect/kafka-connect.yaml2.5.2. Deploying to OpenShift
On OpenShift, Kafka Connect is provided in the form of a template. It can be deployed from the template either using the command line or using the OpenShift console. To create a Kafka Connect cluster from the command line, the following command should be run:
oc new-app strimzi-connect2.5.3. Using Kafka Connect with additional plugins
Strimzi Docker images for Kafka Connect contain, by default, only the FileStreamSinkConnector and FileStreamSourceConnector connectors which are part of Apache Kafka.
To facilitate deployment with 3rd party connectors, Kafka Connect is configured to automatically load all plugins/connectors which are present in the /opt/kafka/plugins directory during startup.
There are two ways of adding custom plugins into this directory:
-
Using a custom Docker image
-
Using the OpenShift build system with the Strimzi S2I image
Create a new image based on our base image
Strimzi provides its own Docker image for running Kafka Connect which can be found on Docker Hub as
strimzi/kafka-connect:0.5.0.
This image could be used as a base image for building a new custom image with additional plugins.
The following steps describe the process for creating such a custom image:
-
Create a new
Dockerfilewhich usesstrimzi/kafka-connect:0.5.0as the base imageFROM strimzi/kafka-connect:0.5.0 USER root:root COPY ./my-plugin/ /opt/kafka/plugins/ USER kafka:kafka -
Build the Docker image and upload it to the appropriate Docker repository
-
Use the new Docker image in the Kafka Connect deployment:
-
On OpenShift, the template parameters
IMAGE_REPO_NAME,IMAGE_NAMEandIMAGE_TAGcan be changed to point to the new image when the Kafka Connect cluster is being deployed -
On Kubernetes, the KafkaConnect resource has to be modified to use the new image
-
Using OpenShift Build and S2I image
OpenShift supports Builds which can be used together with the Source-to-Image (S2I) framework to create new Docker images.
OpenShift Build takes a builder image with S2I support together with source code and binaries provided by the user and uses them to build a new Docker image.
The newly created Docker Image will be stored in OpenShift’s local Docker repository and can then be used in deployments.
Strimzi provides a Kafka Connect builder image which can be found on Docker Hub as strimzi/kafka-connect-s2i:0.5.0 with such S2I support.
It takes user-provided binaries (with plugins and connectors) and creates a new Kafka Connect image.
This enhanced Kafka Connect image can be used with our Kafka Connect deployment.
The S2I deployment is again provided as an OpenShift template. It can be deployed from the template either using the command line or using the OpenShift console. To create Kafka Connect S2I cluster from the command line, the following command should be run:
oc new-app strimzi-connect-s2iOnce the cluster is deployed, a new Build can be triggered from the command line:
-
A directory with Kafka Connect plugins has to be prepared first. For example:
$ tree ./my-plugins/ ./my-plugins/ ├── debezium-connector-mongodb │ ├── bson-3.4.2.jar │ ├── CHANGELOG.md │ ├── CONTRIBUTE.md │ ├── COPYRIGHT.txt │ ├── debezium-connector-mongodb-0.7.1.jar │ ├── debezium-core-0.7.1.jar │ ├── LICENSE.txt │ ├── mongodb-driver-3.4.2.jar │ ├── mongodb-driver-core-3.4.2.jar │ └── README.md ├── debezium-connector-mysql │ ├── CHANGELOG.md │ ├── CONTRIBUTE.md │ ├── COPYRIGHT.txt │ ├── debezium-connector-mysql-0.7.1.jar │ ├── debezium-core-0.7.1.jar │ ├── LICENSE.txt │ ├── mysql-binlog-connector-java-0.13.0.jar │ ├── mysql-connector-java-5.1.40.jar │ ├── README.md │ └── wkb-1.0.2.jar └── debezium-connector-postgres ├── CHANGELOG.md ├── CONTRIBUTE.md ├── COPYRIGHT.txt ├── debezium-connector-postgres-0.7.1.jar ├── debezium-core-0.7.1.jar ├── LICENSE.txt ├── postgresql-42.0.0.jar ├── protobuf-java-2.6.1.jar └── README.md -
To start a new image build using the prepared directory, the following command has to be run:
oc start-build my-connect-cluster-connect --from-dir ./my-plugins/The name of the build should be changed according to the cluster name of the deployed Kafka Connect cluster.
-
Once the build is finished, the new image will be used automatically by the Kafka Connect deployment.
2.6. Topic Operator
Strimzi uses a component called the Topic Operator to manage topics in the Kafka cluster. The Topic Operator is deployed as a process running inside a OpenShift or Kubernetes cluster. To create a new Kafka topic, a ConfigMap with the related configuration (name, partitions, replication factor, …) has to be created. Based on the information in that ConfigMap, the Topic Operator will create a corresponding Kafka topic in the cluster.
Deleting a topic ConfigMap causes the deletion of the corresponding Kafka topic as well.
The Cluster Operator is able to deploy a Topic Operator, which can be configured in the Kafka resource.
Alternatively, it is possible to deploy a Topic Operator manually, rather than having it deployed
by the Cluster Operator.
2.6.1. Deploying through the Cluster Operator
To deploy the Topic Operator through the Cluster Operator, its configuration needs to be provided in the
Kafka resource in the topicOperator field as a JSON string.
For more information on the JSON configuration format see Topic Operator.
2.6.2. Deploying standalone Topic Operator
If you are not going to deploy the Kafka cluster using the Cluster Operator but you already have a Kafka cluster deployed on OpenShift or Kubernetes, it could be useful to deploy the Topic Operator using the provided YAML files. In that case you can still leverage on the Topic Operator features of managing Kafka topics through related ConfigMaps.
Deploying to Kubernetes
To deploy the Topic Operator on Kubernetes (not through the Cluster Operator), the following command should be executed:
kubectl create -f examples/install/topic-operator.yamlTo verify whether the Topic Operator has been deployed successfully, the Kubernetes Dashboard or the following command can be used:
kubectl describe allDeploying to OpenShift
To deploy the Topic Operator on OpenShift (not through the Cluster Operator), the following command should be executed:
oc create -f examples/install/topic-operatorTo verify whether the Topic Operator has been deployed successfully, the OpenShift console or the following command can be used:
oc describe all2.6.3. Topic ConfigMap
When the Topic Operator is deployed by the Cluster Operator it will be configured to watch for "topic ConfigMaps" which are those with the following labels:
strimzi.io/cluster: <cluster-name>
strimzi.io/kind: topic|
Note
|
When the Topic Operator is deployed manually the strimzi.io/cluster label is not necessary.
|
The topic ConfigMap contains the topic configuration in a specific format. The ConfigMap format is described in Format of the ConfigMap.
2.6.4. Logging
The logging field allows the configuration of loggers. These loggers are listed below.
rootLogger.levelFor information on the logging options and examples of how to set logging, see logging examples for Kafka.
When using external ConfigMap remember to place your custom ConfigMap under log4j2.properties key.
3. Cluster Operator
The Cluster Operator is in charge of deploying a Kafka cluster alongside a Zookeeper ensemble. As part of the Kafka cluster, it can also deploy the topic operator which provides operator-style topic management via ConfigMaps. The Cluster Operator is also able to deploy a Kafka Connect cluster which connects to an existing Kafka cluster. On OpenShift such a cluster can be deployed using the Source2Image feature, providing an easy way of including more connectors.
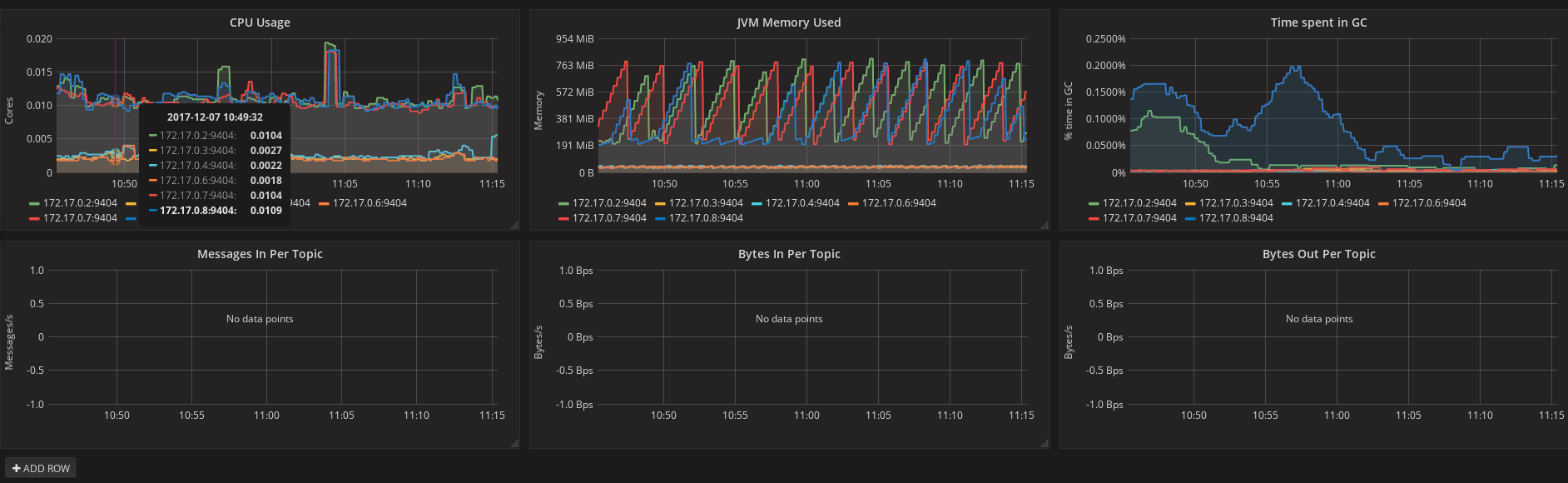
When the Cluster Operator is up, it starts to "watch" for certain OpenShift or Kubernetes resources containing the desired Kafka or Kafka Connect cluster configuration.
A Kafka resource is used for Kafka cluster configuration, and a KafkaConnect resource is used for Kafka Connect cluster configuration.
When a new desired resource (that is, a Kafka or KafkaConnect resource) is created in the OpenShift or Kubernetes cluster, the operator gets the cluster configuration from the desired resource and starts creating a new Kafka or Kafka Connect cluster by creating the necessary other OpenShift or Kubernetes resources, such as StatefulSets, Services, ConfigMaps, and so on.
Every time the desired resource is updated by the user, the operator performs corresponding updates on the OpenShift or Kubernetes resources which make up the Kafka or Kafka Connect cluster. Resources are either patched or deleted and then re-created in order to make the Kafka or Kafka Connect cluster reflect the state of the desired cluster resource. This might cause a rolling update which might lead to service disruption.
Finally, when the desired resource is deleted, the operator starts to un-deploy the cluster deleting all the related OpenShift or Kubernetes resources.
3.1. Reconciliation
Although the operator reacts to all notifications about the desired cluster resources received from the OpenShift or Kubernetes cluster, if the operator is not running, or if a notification is not received for any reason, the desired resources will get out of sync with the state of the running OpenShift or Kubernetes cluster.
In order to handle failovers properly, a periodic reconciliation process is executed by the Cluster Operator so that it can compare the state of the desired resources with the current cluster deployments in order to have a consistent state across all of them.
3.2. Format of the Kafka resource
The full API is described in [kafka_resource_reference].
Whatever other labels are applied to the desired Kafka resource will also be applied to the OpenShift or Kubernetes resources making up the Kafka cluster. This provides a convenient mechanism for those resources to be labelled in whatever way the user requires.
3.2.1. Kafka
In order to configure a Kafka cluster deployment, it is possible to specify the following fields in Kafka resource (a dot is used to denote a nested YAML object):
spec.kafka.replicas-
The number of Kafka broker nodes. Default is 3.
spec.kafka.image-
The Docker image to be used by the Kafka brokers. The default value is determined by the value specified in the
STRIMZI_DEFAULT_KAFKA_IMAGEenvironment variable of the Cluster Operator. spec.kafka.brokerRackInitImage-
The Docker image to be used by the init container which does some initial configuration work (that is, rack support). The default value is determined by the value specified in the
STRIMZI_DEFAULT_KAFKA_INIT_IMAGEenvironment variable of the Cluster Operator. spec.kafka.livenessProbe.initialDelaySeconds-
The initial delay for the liveness probe for each Kafka broker node. Default is 15.
spec.kafka.livenessProbe.timeoutSeconds-
The timeout on the liveness probe for each Kafka broker node. Default is 5.
spec.kafka.readinessProbe.initialDelaySeconds-
The initial delay for the readiness probe for each Kafka broker node. Default is 15.
spec.kafka.readinessProbe.timeoutSeconds-
The timeout on the readiness probe for each Kafka broker node. Default is 5.
spec.kafka.config-
The Kafka broker configuration. See section Kafka Configuration for more details.
spec.kafka.storage-
The storage configuration for the Kafka broker nodes. See section Storage for more details.
spec.kafka.metrics-
The JMX exporter configuration for exposing metrics from Kafka broker nodes. When this field is absent no metrics will be exposed.
spec.kafka.logging-
An object that specifies inline logging levels or the name of external config map that specifies the logging levels. When this field is absent default values are used. List of loggers which can be set:
kafka.root.logger.level
log4j.logger.org.I0Itec.zkclient.ZkClient
log4j.logger.org.apache.zookeeper
log4j.logger.kafka
log4j.logger.org.apache.kafka
log4j.logger.kafka.request.logger
log4j.logger.kafka.network.Processor
log4j.logger.kafka.server.KafkaApis
log4j.logger.kafka.network.RequestChannel$
log4j.logger.kafka.controller
log4j.logger.kafka.log.LogCleaner
log4j.logger.state.change.logger
log4j.logger.kafka.authorizer.loggerspec.kafka.resources-
The resource limits and requests for Kafka broker containers. The accepted format is described in the Resource limits and requests section.
spec.kafka.jvmOptions-
An object allowing the JVM running Kafka to be configured. The accepted format is described in the JVM Options section.
spec.kafka.rack-
An object allowing the Kafka rack feature to be configured and used in rack-aware partition assignment for fault tolerance. For information about the accepted JSON format, see Kafka rack section.
spec.kafka.affinity-
An object allowing control over how the Kafka pods are scheduled to nodes. The format of the corresponding key is the same as the content supported in the Pod
affinityin OpenShift or Kubernetes. See section Node and Pod Affinity for more details. spec.kafka.tlsSidecar.image-
The Docker image to be used by the sidecar container which provides TLS support for Kafka brokers. The default value is determined by the value specified in the
STRIMZI_DEFAULT_TLS_SIDECAR_KAFKA_IMAGEenvironment variable of the Cluster Operator. spec.kafka.tlsSidecar.resources-
An object configuring the resource limits and requests for the sidecar container which provides TLS support for Kafka brokers. For information about the accepted JSON format, see Resource limits and requests.
spec.zookeeper.replicas-
The number of Zookeeper nodes.
spec.zookeeper.image-
The Docker image to be used by the Zookeeper nodes. The default value is determined by the value specified in the
STRIMZI_DEFAULT_ZOOKEEPER_IMAGEenvironment variable of the Cluster Operator. spec.zookeeper.livenessProbe.initialDelaySeconds-
The initial delay for the liveness probe for each Zookeeper node. Default is 15.
spec.zookeeper.livenessProbe.initialDelaySeconds-
The timeout on the liveness probe for each Zookeeper node. Default is 5.
spec.zookeeper.readinessProbe.initialDelaySeconds-
The initial delay for the readiness probe for each Zookeeper node. Default is 15.
spec.zookeeper.readinessProbe.initialDelaySeconds-
The timeout on the readiness probe for each Zookeeper node. Default is 5.
spec.zookeeper.config-
The Zookeeper configuration. See section Zookeeper Configuration for more details.
spec.zookeeper.storage-
The storage configuration for the Zookeeper nodes. See section Storage for more details.
spec.zookeeper.metrics-
The JMX exporter configuration for exposing metrics from Zookeeper nodes. When this field is absent no metrics will be exposed.
spec.zookeeper.logging-
An object that specifies inline logging levels or the name of external config map that specifies the logging levels. When this field is absent default values are used. List of loggers which can be set:
zookeeper.root.loggerspec.zookeeper.resources-
An object configuring the resource limits and requests for Zookeeper broker containers. For information about the accepted JSON format, see Resource limits and requests section.
spec.zookeeper.jvmOptions-
An object allowing the JVM running Zookeeper to be configured. For information about the accepted JSON format, see JVM Options section.
spec.zookeeper.affinity-
An object allowing control over how the Zookeeper pods are scheduled to nodes. The format of the corresponding key is the same as the content supported in the Pod
affinityin OpenShift or Kubernetes. See section Node and Pod Affinity for more details. spec.zookeeper.tlsSidecar.image-
The Docker image to be used by the sidecar container which provides TLS support for Zookeeper nodes. The default value is determined by the value specified in the
STRIMZI_DEFAULT_TLS_SIDECAR_ZOOKEEPER_IMAGEenvironment variable of the Cluster Operator. spec.zookeeper.tlsSidecar.resources-
An object configuring the resource limits and requests for the sidecar container which provides TLS support for Zookeeper nodes. For information about the accepted JSON format, see Resource limits and requests.
spec.topicOperator-
An object representing the topic operator configuration. See the Topic Operator documentation for further details. More info about the topic operator in the related [Topic operator] documentation page.
The following is an example of a Kafka resource.
Kafka resourceapiVersion: kafka.strimzi.io/v1alpha1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
replicas: 3
image: "strimzi/kafka:0.5.0"
kafka-healthcheck-delay: "15"
kafka-healthcheck-timeout: "5"
config:
offsets.topic.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 2
storage:
type: ephemeral
metrics:
{
"lowercaseOutputName": true,
"rules": [
{
"pattern": "kafka.server<type=(.+), name=(.+)PerSec\\w*><>Count",
"name": "kafka_server_$1_$2_total"
},
{
"pattern": "kafka.server<type=(.+), name=(.+)PerSec\\w*, topic=(.+)><>Count",
"name": "kafka_server_$1_$2_total",
"labels":
{
"topic": "$3"
}
}
]
}
logging:
type: external
name: customConfigMap
zookeeper:
replicas: 1
image: strimzi/zookeeper:0.5.0
healthcheck-delay: "15"
healthcheck-timeout: "5"
config:
timeTick: 2000,
initLimit: 5,
syncLimit: 2,
autopurge.purgeInterval: 1
storage:
type: ephemeral
metrics:
{
"lowercaseOutputName": true
}
logging:
type : inline
loggers :
zookeeper.root.logger: INFOThe resources created by the Cluster Operator in the OpenShift or Kubernetes cluster will be the following :
[cluster-name]-zookeeper-
StatefulSet which is in charge of managing the Zookeeper node pods
[cluster-name]-kafka-
StatefulSet which is in charge of managing the Kafka broker pods
[cluster-name]-zookeeper-nodes-
Service needed to have DNS resolve the Zookeeper pods IP addresses directly
[cluster-name]-kafka-brokers-
Service needed to have DNS resolve the Kafka broker pods IP addresses directly
[cluster-name]-zookeeper-client-
Service used by Kafka brokers to connect to Zookeeper nodes as clients
[cluster-name]-kafka-bootstrap-
Service can be used as bootstrap servers for Kafka clients
[cluster-name]-zookeeper-metrics-config-
ConfigMap which contains the Zookeeper metrics configuration and mounted as a volume by the Zookeeper node pods
[cluster-name]-kafka-metrics-config-
ConfigMap which contains the Kafka metrics configuration and mounted as a volume by the Kafka broker pods
[cluster-name]-zookeeper-config-
ConfigMap which contains the Zookeeper ancillary configuration and is mounted as a volume by the Zookeeper node pods
[cluster-name]-kafka-config-
ConfigMap which contains the Kafka ancillary configuration and is mounted as a volume by the Kafka broker pods
Kafka Configuration
The spec.kafka.config object allows detailed configuration of Apache Kafka. This field should contain a JSON object with Kafka
configuration options as keys. The values could be in one of the following JSON types:
-
String
-
Number
-
Boolean
The spec.kafka.config object supports all Kafka configuration options with the exception of options related to:
-
Security (Encryption, Authentication and Authorization)
-
Listener configuration
-
Broker ID configuration
-
Configuration of log data directories
-
Inter-broker communication
-
Zookeeper connectivity
Specifically, all configuration options with keys starting with one of the following strings will be ignored:
-
listeners -
advertised. -
broker. -
listener. -
host.name -
port -
inter.broker.listener.name -
sasl. -
ssl. -
security. -
password. -
principal.builder.class -
log.dir -
zookeeper.connect -
zookeeper.set.acl -
authorizer. -
super.user
All other options will be passed to Kafka.
A list of all the available options can be found on the Kafka website.
An example spec.kafka.config field is provided below.
Kafka resource specifying Kafka configurationapiVersion: {KafkaApiVersion}
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
config:
num.partitions: 1,
num.recovery.threads.per.data.dir: 1,
default.replication.factor: 3,
offsets.topic.replication.factor: 3,
transaction.state.log.replication.factor: 3,
transaction.state.log.min.isr: 1,
log.retention.hours: 168,
log.segment.bytes: 1073741824,
log.retention.check.interval.ms: 300000,
num.network.threads: 3,
num.io.threads: 8,
socket.send.buffer.bytes: 102400,
socket.receive.buffer.bytes: 102400,
socket.request.max.bytes: 104857600,
group.initial.rebalance.delay.ms: 0
# ...- NOTE
-
The Cluster Operator does not validate keys or values in the provided
configobject. When invalid configuration is provided, the Kafka cluster might not start or might become unstable. In such cases, the configuration in thespec.kafka.configobject should be fixed and the cluster operator will roll out the new configuration to all Kafka brokers.
Zookeeper Configuration
The spec.zookeeper.config object allows detailed configuration of Apache Zookeeper. This field should contain a JSON object
with Zookeeper configuration options as keys. The values could be in one of the following JSON types:
-
String
-
Number
-
Boolean
The spec.zookeeper.config object supports all Zookeeper configuration options with the exception of options related to:
-
Security (Encryption, Authentication and Authorization)
-
Listener configuration
-
Configuration of data directories
-
Zookeeper cluster composition
Specifically, all configuration options with keys starting with one of the following strings will be ignored:
-
server. -
dataDir -
dataLogDir -
clientPort -
authProvider -
quorum.auth -
requireClientAuthScheme
All other options will be passed to Zookeeper.
A list of all the available options can be found on the Zookeeper website.
An example spec.zookeeper.config object is provided below.
Kafka resource specifying Zookeeper configurationapiVersion: {KafkaApiVersion}
kind: Kafka
metadata:
name: my-cluster
spec:
zookeeper:
# ...
config:
timeTick: 2000,
initLimit: 5,
syncLimit: 2,
quorumListenOnAllIPs: true,
maxClientCnxns: 0,
autopurge.snapRetainCount: 3,
autopurge.purgeInterval: 1
# ...Selected options have default values:
-
timeTickwith default value2000 -
initLimitwith default value5 -
syncLimitwith default value2 -
autopurge.purgeIntervalwith default value1
These options will be automatically configured in case they are not present in the spec.zookeeper.config object.
- NOTE
-
The Cluster Operator does not validate keys or values in the provided
configobject. When invalid configuration is provided, the Zookeeper cluster might not start or might become unstable. In such cases, the configuration in thespec.zookeeper.configobject should be fixed and the cluster operator will roll out the new configuration to all Zookeeper nodes.
Storage
Both Kafka and Zookeeper save data to files.
Strimzi allows to save such data in an "ephemeral" way (using emptyDir) or in a "persistent-claim" way using persistent volumes.
It is possible to provide the storage configuration in the spec.kafka.storage and spec.zookeeper.storage objects.
|
Important
|
The spec.kafka.storage and spec.zookeeper.storage objects cannot be changed when the cluster is up.
|
The storage object has a mandatory type field for specifying the type of storage to use which must be either "ephemeral" or "persistent-claim".
The "ephemeral" storage is really simple to configure.
Kafka resource using ephemeral storage for Kafka podsapiVersion: {KafkaApiVersion}
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
storage:
type: ephemeral
# ...|
Warning
|
If the Zookeeper cluster is deployed using "ephemeral" storage, the Kafka brokers can have problems dealing with Zookeeper node restarts which could happen via updates in the Kafka resource. |
In case of "persistent-claim" type the following fields can be provided as well:
size(required)-
defines the size of the persistent volume claim, for example, "1Gi".
class(optional)-
the OpenShift or Kubernetes storage class to use for dynamic volume allocation.
selector(optional)-
allows to select a specific persistent volume to use. It contains a
matchLabelsfield which contains key:value pairs representing labels for selecting such a volume. delete-claim(optional)-
boolean value which specifies if the persistent volume claim has to be deleted when the cluster is undeployed. Default is
false.
Kafka resource configuring Kafka with persistent-storage and 1Gi sizeapiVersion: {KafkaApiVersion}
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
storage:
type: persistent-claim
size: 1Gi
# ...The following example demonstrates use of a storage class.
Kafka resource configuring Kafka with persistent-storage using a storage classapiVersion: {KafkaApiVersion}
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
storage:
type: persistent-claim
size: 1Gi
class: my-storage-class
# ...Finally, a selector can be used in order to select a specific labelled persistent volume which provides some needed features (such as an SSD)
Kafka resource configuring Kafka with "match labels" selectorapiVersion: {KafkaApiVersion}
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
storage:
type: persistent-claim
size: 1Gi
selector:
matchLabels:
"hdd-type": "ssd"
deleteClaim: true
# ...When the "persistent-claim" is used, other than the resources already described in the Kafka section, the following resources are generated :
data-[cluster-name]-kafka-[idx]-
Persistent Volume Claim for the volume used for storing data for the Kafka broker pod
[idx]. data-[cluster-name]-zookeeper-[idx]-
Persistent Volume Claim for the volume used for storing data for the Zookeeper node pod
[idx].
See [kafka.strimzi.io-v1alpha1-type-EphemeralStorage] and [kafka.strimzi.io-v1alpha1-type-PersistentClaimStorage] for further details.
Metrics
Strimzi uses the [Prometheus JMX exporter](https://github.com/prometheus/jmx_exporter) in order to expose metrics on each node.
It is possible to configure a metrics object in the kafka and zookeeper objects in Kafka resources, and likewise a metrics object in the spec of KafkaConnect resources.
In all cases the metrics object should be the configuration for the JMX exporter.
You can find more information on how to use it in the corresponding GitHub repo.
For more information about using the metrics with Prometheus and Grafana, see [_metrics]
Logging
The logging field allows the configuration of loggers. These loggers for Zookeeper and Kafka are available in the spec.zookeeper.logging and spec.kafka.logging sections respectively.
The setting can be done in one of two ways. Either by specifying the loggers and their levels directly or by using a custom config map. An example would look like this:
logging:
type: inline
loggers:
logger.name: "INFO"The INFO can be replaced with any log4j logger level. The available logger levels are INFO, ERROR, WARN, TRACE, DEBUG, FATAL or OFF.
The informations about log levels can be found in the log4j manual.
logging:
type: external
name: customConfigMapWhen using external ConfigMap remember to place your custom ConfigMap under log4j.properties key.
The difference between these two options is that the latter is not validated and does not support default values. That means the user can supply any logging configuration, even if it is incorrect. The first option supports default values.
Resource limits and requests
It is possible to configure OpenShift or Kubernetes resource limits and requests on for the kafka, zookeeper and topicOperator objects in the Kafka resource and for for the spec object of the KafkaConnect resource.
The object may have a `requests and a limits property, each having the same schema, consisting of cpu and memory properties.
The OpenShift or Kubernetes syntax is used for the values of cpu and memory.
Kafka resource configuring resource limits and requests for the Kafka podsapiVersion: {KafkaApiVersion}
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
resources:
requests:
cpu: "1"
memory: "2Gi"
limits:
cpu: "1"
memory: "2Gi"
# ...requests.memory-
the memory request for the container, corresponding directly to
spec.containers[].resources.requests.memorysetting. OpenShift or Kubernetes will ensure the containers have at least this much memory by running the pod on a node with at least as much free memory as all the containers require. Optional with no default. requests.cpu-
the cpu request for the container, corresponding directly to
spec.containers[].resources.requests.cpusetting. OpenShift or Kubernetes will ensure the containers have at least this much CPU by running the pod on a node with at least as much uncommitted CPU as all the containers require. Optional with no default. limits.memory-
the memory limit for the container, corresponding directly to
spec.containers[].resources.limits.memorysetting. OpenShift or Kubernetes will limit the containers to this much memory, potentially terminating their pod if they use more. Optional with no default. limits.cpu-
the cpu limit for the container, corresponding directly to
spec.containers[].resources.limits.cpusetting. OpenShift or Kubernetes will cap the containers CPU usage to this limit. Optional with no default.
More details about resource limits and requests can be found on Kubernetes website.
Minimum Resource Requirements
Testing has shown that the Cluster Operator functions adequately with 256Mi of memory and 200m CPU when watching two clusters. It is therefore recommended to use these as a minimum when configuring resource requests and not to run it with lower limits than these. Configuring more generous limits is recommended, especially when it is controlling multiple clusters.
JVM Options
It is possible to configure a subset of available JVM options on Kafka, Zookeeper and Kafka Connect containers.
The object has a property for each JVM (java) option which can be configured:
-Xmx-
The maximum heap size. See the Setting
-Xmxsection for further details. -Xms-
The initial heap size. Setting the same value for initial and maximum (
-Xmx) heap sizes avoids the JVM having to allocate memory after startup, at the cost of possibly allocating more heap than is really needed. For Kafka and Zookeeper pods such allocation could cause unwanted latency. For Kafka Connect avoiding over allocation may be the more important concern, especially in distributed mode where the effects of over-allocation will be multiplied by the number of consumers.
|
Note
|
The units accepted by JVM settings such as -Xmx and -Xms are those accepted by the JDK java
binary in the corresponding image. Accordingly, 1g or 1G means 1,073,741,824 bytes, and Gi is not a valid unit
suffix. This is in contrast to the units used for memory limits and requests, which follow the
OpenShift or Kubernetes convention where 1G means 1,000,000,000 bytes, and 1Gi means 1,073,741,824 bytes
|
Kafka resource configuring jvmOptionsapiVersion: {KafkaApiVersion}
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
jvmOptions:
"-Xmx": "2g"
"-Xms": "2g"
# ...In the above example, the JVM will use 2 GiB (=2,147,483,648 bytes) for its heap. Its total memory usage will be approximately 8GiB.
-server-
Selects the server JVM. This option can be set to true or false. Optional.
-XX-
A JSON Object for configuring advanced runtime options of a JVM. Optional
The -server and -XX options are used to configure the KAFKA_JVM_PERFORMANCE_OPTS option of Apache Kafka.
Kafka resource configuring jvmOptionsapiVersion: {KafkaApiVersion}
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
"-server": true,
"-XX":
"UseG1GC": true,
"MaxGCPauseMillis": 20,
"InitiatingHeapOccupancyPercent": 35,
"ExplicitGCInvokesConcurrent": true,
"UseParNewGC": falseThe example configuration above will result in the following JVM options:
-server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -XX:-UseParNewGCWhen neither of the two options (-server and -XX) is specified, the default Apache Kafka configuration of KAFKA_JVM_PERFORMANCE_OPTS will be used.
Setting -Xmx
The default value used for -Xmx depends on whether there is a memory limit for the container:
-
If there is a memory limit, the JVM’s maximum memory will be limited according to the kind of pod (Kafka, Zookeeper, Topic Operator) to an appropriate value less than the limit.
-
Otherwise, when there is no memory limit, the JVM’s maximum memory will be set according to the kind of pod and the RAM available to the container.
|
Important
|
Setting
|
When setting -Xmx explicitly, it is recommended to:
-
set the memory request and the memory limit to the same value,
-
use a memory request that is at least 4.5 × the
-Xmx, -
consider setting
-Xmsto the same value as-Xms.
Furthermore, containers doing lots of disk I/O (such as Kafka broker containers) will need to leave some memory available for use as operating system page cache. On such containers, the request memory should be substantially more than the memory used by the JVM.
Kafka rack
It is possible to enable Kafka rack-awareness (more information can be found on the Kafka racks documentation)
by specifying the rack object in the spec.kafka object of the Kafka resource.
The rack object has one mandatory field named topologyKey.
This key needs to match one of the labels assigned to the OpenShift or Kubernetes cluster nodes.
The label is used by OpenShift or Kubernetes when scheduling Kafka broker pods to nodes.
If the OpenShift or Kubernetes cluster is running on a cloud provider platform, that label should represent the availability zone where the node is running.
Usually, the nodes are labeled with failure-domain.beta.kubernetes.io/zone that can be easily used as topologyKey value.
This will have the effect of spreading the broker pods across zones, and also setting the brokers broker.rack configuration parameter.
Kafka resource configuring the rackapiVersion: {KafkaApiVersion}
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
rack:
topologyKey: failure-domain.beta.kubernetes.io/zone
# ...In the above example, the failure-domain.beta.kubernetes.io/zone node label will be used for scheduling Kafka broker Pods.
Node and Pod Affinity
Node and Pod Affinity provide a flexible mechanism to guide the scheduling of pods to nodes by OpenShift or Kubernetes. Node affinity can be used so that broker pods are preferentially scheduled to nodes with fast disks, for example. Similarly, pod affinity could be used to try to schedule Kafka clients on the same nodes as Kafka brokers. More information can be found on the Kubernetes node and pod affinity documentation.
The format of the corresponding key is the same as the content supported in the Pod affinity in OpenShift or Kubernetes, that is: nodeAffinity, podAffinity and podAntiAffinity.
Kafka resource configured with nodeAffinityapiVersion: {KafkaApiVersion}
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/e2e-az-name
operator: In
values:
- e2e-az1
- e2e-az2
# ...|
Note
|
When using both affinity and rack be aware that rack uses a pod anti-affinity.
This is necessary so that broker pods are scheduled in different failure domains, as specified via the topologyKey.
This anti-affinity will not be present in the Kafka resource’s affinity, but is still present on the StatefulSet and thus will still be considered by the scheduler.
|
Topic Operator
Alongside the Kafka cluster and the Zookeeper ensemble, the Cluster Operator can also deploy the topic operator.
In order to do that, a spec.topicOperator object has to be included in the Kafka resource.
This object contains the topic operator configuration.
Without this object, the Cluster Operator does not deploy the topic operator.
It is still possible to deploy the topic operator by creating appropriate OpenShift or Kubernetes resources.
The YAML representation of the 'topicOperator` has no mandatory fields and if the value is an empty object (just "{ }"), the Cluster Operator will deploy the topic operator with a default configuration.
The configurable fields are the following :
image-
The Docker image to be used by the Topic Operator. The default value is determined by the value specified in the
STRIMZI_DEFAULT_TOPIC_operator_IMAGEenvironment variable of the Cluster Operator. watchedNamespace-
The OpenShift or Kubernetes namespace in which the topic operator watches for topic ConfigMaps. Default is the namespace where the topic operator is running.
reconciliationIntervalMs-
The interval between periodic reconciliations in milliseconds. Default is 900000 (15 minutes).
zookeeperSessionTimeoutMs-
The Zookeeper session timeout in milliseconds. Default is 20000 milliseconds (20 seconds).
topicMetadataMaxAttempts-
The number of attempts for getting topics metadata from Kafka. The time between each attempt is defined as an exponential back-off. You might want to increase this value when topic creation could take more time due to its larger size (i.e. many partitions / replicas). Default is
6. resources-
An object configuring the resource limits and requests for the topic operator container. The accepted JSON format is described in the Resource limits and requests section.
affinity-
Node and Pod affinity for the Topic Operator, as described in the Node and Pod Affinity section. The format of the corresponding key is the same as the content supported in the Pod
affinityin OpenShift or Kubernetes. tlsSidecar.image-
The Docker image to be used by the sidecar container which provides TLS support for Topic Operator. The default value is determined by the value specified in the
STRIMZI_DEFAULT_TLS_SIDECAR_TOPIC_OPERATOR_IMAGEenvironment variable of the Cluster Operator. tlsSidecar.resources-
An object configuring the resource limits and requests for the sidecar container which provides TLS support for the Topic Operator. For information about the accepted JSON format, see Resource limits and requests.
{ "reconciliationIntervalMs": "900000", "zookeeperSessionTimeoutMs": "20000" }More information about these configuration parameters in the related Topic Operator documentation page.
3.2.2. Kafka Connect
The operator watches for KafkaConnect resource in order to find and get configuration for a Kafka Connect cluster to deploy.
The KafkaConnectS2I resource provides configuration for a Kafka Connect cluster deployment using Build and Source2Image features (works only with OpenShift)
Whatever other labels are applied to the KafkaConnect or KafkaConnectS2I resources will also be applied to the OpenShift or Kubernetes resources making up the Kafka Connect cluster.
This provides a convenient mechanism for those resource to be labelled
in whatever way the user requires.
The KafkaConnect resource supports the following within its spec:
nodes-
Number of Kafka Connect worker nodes. Default is 1.
image-
The Docker image to be used by the Kafka Connect workers. The default value is determined by the value specified in the
STRIMZI_DEFAULT_KAFKA_CONNECT_IMAGEenvironment variable of the Cluster Operator. If S2I is used (only on OpenShift), then it should be the related S2I image. healthcheck-delay-
The initial delay for the liveness and readiness probes for each Kafka Connect worker node. Default is 60.
healthcheck-timeout-
The timeout on the liveness and readiness probes for each Kafka Connect worker node. Default is 5.
connect-config-
A JSON string with Kafka Connect configuration. See section Kafka Connect configuration for more details.
metrics-config-
A JSON string representing the JMX exporter configuration for exposing metrics from Kafka Connect nodes. When this field is absent no metrics will be exposed.
resources-
A JSON string configuring the resource limits and requests for Kafka Connect containers. For information about the accepted JSON format, see Resource limits and requests section.
jvmOptions-
A JSON string allowing the JVM running Kafka Connect to be configured. For information about the accepted JSON format, see JVM Options section.
affinity-
Node and Pod affinity for the Kafka Connect pods, as described in the Node and Pod Affinity section. The format of the corresponding key is the same as the content supported in the Pod
affinityin OpenShift or Kubernetes.
The following is an example of a KafkaConnect resource.
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaConnect
metadata:
name: my-connect-cluster
spec:
nodes: 1
image: strimzi/kafka-connect:0.5.0
readinessProbe:
initialDelaySeconds: 60
timeoutSeconds: 5
livenessProbe:
initialDelaySeconds: 60
timeoutSeconds: 5
config:
bootstrap.servers: my-cluster-kafka-bootstrap:9092The resources created by the Cluster Operator into the OpenShift or Kubernetes cluster will be the following :
- [connect-cluster-name]-connect
-
Deployment which is in charge to create the Kafka Connect worker node pods.
- [connect-cluster-name]-connect-api
-
Service which exposes the REST interface for managing the Kafka Connect cluster.
- [connect-cluster-name]-metrics-config
-
ConfigMap which contains the Kafka Connect metrics configuration and is mounted as a volume by the Kafka Connect pods.
Kafka Connect configuration
The spec.config object of the KafkaConnect and KafkaConnectS2I resources allows detailed configuration of Apache Kafka Connect.
This object should contain the Kafka Connect configuration options as keys. The values could be in one of the following JSON types:
-
String
-
Number
-
Boolean
The config object supports all Kafka Connect configuration options with the exception of options related to:
-
Security (Encryption, Authentication and Authorization)
-
Listener / REST interface configuration
-
Plugin path configuration
Specifically, all configuration options with keys starting with one of the following strings will be ignored:
-
ssl. -
sasl. -
security. -
listeners -
plugin.path -
rest.
All other options will be passed to Kafka Connect. A list of all the available options can be found on the
Kafka website. An example config field is provided
below.
apiVersion: {KafkaConnectApiVersion}
kind: KafkaConnect
metadata:
name: my-connect-cluster
spec:
config:
bootstrap.servers: my-cluster-kafka:9092
group.id: my-connect-cluster
offset.storage.topic: my-connect-cluster-offsets
config.storage.topic: my-connect-cluster-configs
status.storage.topic: my-connect-cluster-status
key.converter: org.apache.kafka.connect.json.JsonConverter
value.converter: org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable: true
value.converter.schemas.enable: true
internal.key.converter: org.apache.kafka.connect.json.JsonConverter
internal.value.converter: org.apache.kafka.connect.json.JsonConverter
internal.key.converter.schemas.enable: false
internal.value.converter.schemas.enable: false
config.storage.replication.factor: 3
offset.storage.replication.factor: 3
status.storage.replication.factor: 3
}Selected options have default values:
-
group.idwith default valueconnect-cluster -
offset.storage.topicwith default valueconnect-cluster-offsets -
config.storage.topicwith default valueconnect-cluster-configs -
status.storage.topicwith default valueconnect-cluster-status -
key.converterwith default valueorg.apache.kafka.connect.json.JsonConverter -
value.converterwith default valueorg.apache.kafka.connect.json.JsonConverter -
internal.key.converterwith default valueorg.apache.kafka.connect.json.JsonConverter -
internal.value.converterwith default valueorg.apache.kafka.connect.json.JsonConverter -
internal.key.converter.schemas.enablewith default valuefalse -
internal.value.converter.schemas.enablewith default valuefalse
These options will be automatically configured in case they are not present in the config object.
- INFO
-
The Cluster Operator does not validate the provided configuration. When invalid configuration is provided, the Kafka Connect cluster might not start or might become unstable. In such cases, the configuration in the
configobject should be fixed and the Cluster Operator will roll out the new configuration to all Kafka Connect instances.
Logging
The logging field allows the configuration of loggers. These loggers are:
log4j.rootLogger
connect.root.logger.level
log4j.logger.org.apache.zookeeper
log4j.logger.org.I0Itec.zkclient
log4j.logger.org.reflectionsFor information on the logging options and examples of how to set logging, see logging examples for Kafka.
Kafka Connect S2I deployment
When using Strimzi together with an OpenShift cluster, a user can deploy Kafka Connect with support for OpenShift Builds and Source-to-Image (S2I).
To activate the S2I deployment a KafkaConnectS2I resource should be used instead of a KafkaConnect resource.
The following is a full example of KafkaConnectS2I resource.
KafkaConnectS2I resourceapiVersion: {KafkaConnectS2I}
kind: KafkaConnectS2I
metadata:
name: my-connect-cluster
spec:
nodes: 1
image: strimzi/kafka-connect-s2i:0.5.0
readinessProbe:
initialDelaySeconds: 60
timeoutSeconds: 5
livenessProbe:
initialDelaySeconds: 60
timeoutSeconds: 5
config:
bootstrap.servers: my-cluster-kafka:9092The S2I deployment is very similar to the regular Kafka Connect deployment (as represented by the KafkaConnect resource).
Compared to the regular deployment, the Cluster Operator will create the following additional resources:
- [connect-cluster-name]-connect-source
-
ImageStream which is used as the base image for the newly-built Docker images.
- [connect-cluster-name]-connect
-
BuildConfig which is responsible for building the new Kafka Connect Docker images.
- [connect-cluster-name]-connect
-
ImageStream where the newly built Docker images will be pushed.
- [connect-cluster-name]-connect
-
DeploymentConfig which is in charge of creating the Kafka Connect worker node pods.
- [connect-cluster-name]-connect
-
Service which exposes the REST interface for managing the Kafka Connect cluster.
The Kafka Connect S2I deployment supports the same options as the regular Kafka Connect deployment.
A list of supported options can be found in the Kafka Connect section.
The image option specifies the Docker image which will be used as the source image - the base image for the newly built Docker image.
The default value of the image option is determined by the value of the STRIMZI_DEFAULT_KAFKA_CONNECT_S2I_IMAGE environment variable of the Cluster Operator.
All other options have the same meaning as for the regular KafkaConnect deployment.
Once the Kafka Connect S2I cluster is deployed, new plugins can be added by starting a new OpenShift build. Before starting the build, a directory with all the KafkaConnect plugins which should be added has to be created. The plugins and all their dependencies can be in a single directory or can be split into multiple subdirectories. For example:
$ tree ./s2i-plugins/
./s2i-plugins/
├── debezium-connector-mysql
│ ├── CHANGELOG.md
│ ├── CONTRIBUTE.md
│ ├── COPYRIGHT.txt
│ ├── debezium-connector-mysql-0.7.1.jar
│ ├── debezium-core-0.7.1.jar
│ ├── LICENSE.txt
│ ├── mysql-binlog-connector-java-0.13.0.jar
│ ├── mysql-connector-java-5.1.40.jar
│ ├── README.md
│ └── wkb-1.0.2.jar
└── debezium-connector-postgres
├── CHANGELOG.md
├── CONTRIBUTE.md
├── COPYRIGHT.txt
├── debezium-connector-postgres-0.7.1.jar
├── debezium-core-0.7.1.jar
├── LICENSE.txt
├── postgresql-42.0.0.jar
├── protobuf-java-2.6.1.jar
└── README.mdA new build can be started using the following command:
oc start-build my-connect-cluster-connect --from-dir ./s2i-plugins/This command will upload the whole directory into the OpenShift cluster and start a new build.
The build will take the base Docker image from the source ImageStream (named [connect-cluster-name]-connect-source) and add the directory and all the files it contains into this image and push the resulting image into the target ImageStream (named [connect-cluster-name]-connect).
When the new image is pushed to the target ImageStream, a rolling update of the Kafka Connect S2I deployment will be started and will roll out the new version of the image with the added plugins.
By default, the oc start-build command will trigger the build and complete.
The progress of the build can be observed in the OpenShift console.
Alternatively, the option --follow can be used to follow the build from the command line:
oc start-build my-connect-cluster-connect --from-dir ./s2i-plugins/ --follow
Uploading directory "s2i-plugins" as binary input for the build ...
build "my-connect-cluster-connect-3" started
Receiving source from STDIN as archive ...
Assembling plugins into custom plugin directory /tmp/kafka-plugins
Moving plugins to /tmp/kafka-plugins
Pushing image 172.30.1.1:5000/myproject/my-connect-cluster-connect:latest ...
Pushed 6/10 layers, 60% complete
Pushed 7/10 layers, 70% complete
Pushed 8/10 layers, 80% complete
Pushed 9/10 layers, 90% complete
Pushed 10/10 layers, 100% complete
Push successful|
Note
|
The S2I build will always add the additional Kafka Connect plugins to the original source image. They will not be added to the Docker image from a previous build. To add multiple plugins to the deployment, they all have to be added within the same build. |
3.3. Provisioning Role-Based Access Control (RBAC) for the Cluster Operator
For the Cluster Operator to function it needs permission within the OpenShift or Kubernetes cluster to interact with the resources it manages and interacts with.
These include the desired resources, such as Kafka, Kafka Connect, and so on, as well as the managed resources, such as ConfigMaps, Pods, Deployments, StatefulSets, Services, and so on.
Such permission is described in terms of OpenShift or Kubernetes role-based access control (RBAC) resources:
-
ServiceAccount, -
RoleandClusterRole, -
RoleBindingandClusterRoleBinding.
In addition to running under its own ServiceAccount with a ClusterRoleBinding, the Cluster Operator manages some RBAC resources because some of the components need access to OpenShift or Kubernetes resources.
OpenShift or Kubernetes also includes privilege escalation protections that prevent components operating under one ServiceAccount from granting other ServiceAccounts privileges that the granting ServiceAccount does not have.
Because the Cluster Operator must be able to create the ClusterRoleBindings and RoleBindings needed by resources it manages, the Cluster Operator must also have those same privileges.
3.3.1. Delegated privileges
When the Cluster Operator deploys resources for a desired Kafka resource it also creates ServiceAccounts, RoleBindings and ClusterRoleBindings, as follows:
-
The Kafka broker pods use a
ServiceAccountcalled<cluster-name>-kafka(where<cluster-name>is a placeholder for the name of theKafkaresource)-
When the rack feature is used, the
strimzi-<cluster-name>-kafka-initClusterRoleBindingis used to grant thisServiceAccountaccess to the nodes within the cluster via aClusterRolecalledstrimzi-kafka-broker -
When the rack feature is not used no binding is created.
-
-
The Zookeeper pods use the default
ServiceAccountas they have no need to access OpenShift or Kubernetes resources -
The Topic Operator pod uses a
ServiceAccountcalled<cluster-name>-topic-operator(where<cluster-name>is a placeholder for the name of theKafkaresource)-
The Topic Operator produces OpenShift or Kubernetes events with status information, so the
ServiceAccountis bound to aClusterRolecalledstrimzi-topic-operatorwhich grants this access via thestrimzi-topic-operator-role-bindingRoleBinding.
-
The pods for KafkaConnect and KafkaConnectS2I resources use the default ServiceAccount, since they require no access to OpenShift or Kubernetes resources.
3.3.2. Using a ServiceAccount
The Cluster Operator is best run using a ServiceAccount:
ServiceAccount for the Cluster OperatorapiVersion: v1
kind: ServiceAccount
metadata:
name: strimzi-cluster-operator
labels:
app: strimziThe Deployment of the operator then needs to specify this in its spec.template.spec.serviceAccountName:
Deployment for the Cluster OperatorapiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: strimzi-cluster-operator
spec:
replicas: 1
template:
metadata:
labels:
name: strimzi-cluster-operator
spec:
serviceAccountName: strimzi-cluster-operator
containers:
# ...Note line 12, where the the strimzi-cluster-operator ServiceAccount is specified as the serviceAccountName.
3.3.3. Defining ClusterRoles
The Cluster Operator needs to operate using ClusterRoles that give it access to the necessary resources.
Depending on the OpenShift or Kubernetes cluster setup, a cluster administrator might be needed to create the ClusterRoles.
|
Note
|
Cluster administrator rights are only needed for the creation of the ClusterRoles.
The Cluster Operator will not run under the cluster admin account.
|
The ClusterRoles follow the "principle of least privilege" and contain only those privileges needed by the Cluster Operator to operate Kafka, Kafka Connect, and Zookeeper clusters. The first set of assigned privileges allow the Cluster Operator to manage OpenShift or Kubernetes resources such as StatefulSets, Deployments, Pods, and ConfigMaps.
Role for the Cluster OperatorapiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: strimzi-cluster-operator
labels:
app: strimzi
rules:
- apiGroups:
- ""
resources:
- serviceaccounts
verbs:
- get
- create
- delete
- patch
- update
- apiGroups:
- "rbac.authorization.k8s.io"
resources:
- clusterrolebindings
- rolebindings
verbs:
- get
- create
- delete
- patch
- update
- apiGroups:
- ""
resources:
- configmaps
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
- "kafka.strimzi.io"
resources:
- kafkas
- kafkaconnects
- kafkaconnects2is
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- list
- watch
- delete
- apiGroups:
- ""
resources:
- services
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
- ""
resources:
- endpoints
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
resources:
- deployments
- deployments/scale
- replicasets
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
- "apps"
resources:
- deployments
- deployments/scale
- deployments/status
- statefulsets
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
- ""
resources:
- events
verbs:
- create
# OpenShift S2I requirements
- apiGroups:
- "extensions"
resources:
- replicationcontrollers
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
- apps.openshift.io
resources:
- deploymentconfigs
- deploymentconfigs/scale
- deploymentconfigs/status
- deploymentconfigs/finalizers
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
- build.openshift.io
resources:
- buildconfigs
- builds
verbs:
- create
- delete
- get
- list
- patch
- watch
- update
- apiGroups:
- image.openshift.io
resources:
- imagestreams
- imagestreams/status
verbs:
- create
- delete
- get
- list
- watch
- patch
- update
- apiGroups:
- ""
resources:
- replicationcontrollers
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
- ""
resources:
- secrets
verbs:
- get
- list
- create
- delete
- patch
- updateThe strimzi-kafka-broker ClusterRole represents the access needed by the init container in Kafka pods that is used for the rack feature. As described in the Delegated privileges section, this role is also needed by the Cluster Operator in order to be able to delegate this access.
ClusterRole for the Cluster Operator allowing it to delegate access to OpenShift or Kubernetes nodes to the Kafka broker pods# These are the privileges needed by the init container
# in Kafka broker pods.
# The Cluster Operator also needs these privileges since
# it binds the Kafka pods' ServiceAccount to this
# role.
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: strimzi-kafka-broker
labels:
app: strimzi
rules:
- apiGroups:
- ""
resources:
- nodes
verbs:
- getThe strimzi-topic-operator ClusterRole represents the access needed by the Topic Operator. As described in the Delegated privileges section, this role is also needed by the Cluster Operator in order to be able to delegate this access.
ClusterRole for the Cluster Operator allowing it to delegate access to events to the Topic Operator# These are the privileges needed by the Topic Operator.
# The Cluster Operator also needs these privileges since
# it binds the Topic Operator's ServiceAccount to this
# role.
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: strimzi-topic-operator
labels:
app: strimzi
rules:
- apiGroups:
- ""
resources:
- configmaps
verbs:
- get
- list
- watch
- create
- patch
- update
- delete
- apiGroups:
- ""
resources:
- events
verbs:
- create3.3.4. Defining ClusterRoleBindings
The operator needs a ClusterRoleBinding which associates its ClusterRole with its ServiceAccount:
RoleBinding for the Cluster OperatorapiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: strimzi-cluster-operator
labels:
app: strimzi
subjects:
- kind: ServiceAccount
name: strimzi-cluster-operator
namespace: myproject
roleRef:
kind: ClusterRole
name: strimzi-cluster-operator
apiGroup: rbac.authorization.k8s.ioClusterRoleBindings are also needed for the ClusterRoles needed for delegation:
RoleBinding for the Cluster Operator---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: strimzi-cluster-operator-kafka-broker-delegation
labels:
app: strimzi
subjects:
- kind: ServiceAccount
name: strimzi-cluster-operator
namespace: myproject
roleRef:
kind: ClusterRole
name: strimzi-kafka-broker
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: strimzi-cluster-operator-topic-operator-delegation
labels:
app: strimzi
subjects:
- kind: ServiceAccount
name: strimzi-cluster-operator
namespace: myproject
roleRef:
kind: ClusterRole
name: strimzi-topic-operator
apiGroup: rbac.authorization.k8s.io
---3.4. Operator configuration
The operator itself can be configured through the following environment variables.
-
STRIMZI_NAMESPACE -
Required. A comma-separated list of namespaces that the operator should operate in. The Cluster Operator deployment might use the Kubernetes Downward API to set this automatically to the namespace the Cluster Operator is deployed in. See the example below:
env: - name: STRIMZI_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace -
STRIMZI_FULL_RECONCILIATION_INTERVAL_MS -
Optional, default: 120000 ms. The interval between periodic reconciliations, in milliseconds.
-
STRIMZI_OPERATION_TIMEOUT_MS -
Optional, default: 300000 ms. The timeout for internal operations, in milliseconds. This value should be increased when using Strimzi on clusters where regular OpenShift or Kubernetes operations take longer than usual (because of slow downloading of Docker images, for example).
-
STRIMZI_DEFAULT_KAFKA_IMAGE -
Optional, default
strimzi/kafka:latest. The image name to use as a default when deploying Kafka, if no image is specified as thekafka-imagein the Kafka cluster ConfigMap. -
STRIMZI_DEFAULT_KAFKA_INIT_IMAGE -
Optional, default
strimzi/kafka-init:latest. The image name to use as default for the init container started before the broker for doing initial configuration work (that is, rack support), if no image is specified as thekafka-init-imagein the Kafka cluster ConfigMap. -
STRIMZI_DEFAULT_TLS_SIDECAR_KAFKA_IMAGE -
Optional, default
strimzi/kafka-stunnel:latest. The image name to be used as a default when deploying the sidecar container which provides TLS support for Kafka if no image is specified as thespec.kafka.tlsSidecar.imagein the Kafka cluster ConfigMap. -
STRIMZI_DEFAULT_KAFKA_CONNECT_IMAGE -
Optional, default
strimzi/kafka-connect:latest. The image name to use as a default when deploying Kafka Connect, if no image is specified as theimagein the Kafka Connect cluster ConfigMap. -
STRIMZI_DEFAULT_KAFKA_CONNECT_S2I_IMAGE -
Optional, default
strimzi/kafka-connect-s2i:latest. The image name to use as a default when deploying Kafka Connect S2I, if no image is specified as theimagein the cluster ConfigMap. -
STRIMZI_DEFAULT_TOPIC_OPERATOR_IMAGE -
Optional, default
strimzi/topic-operator:latest. The image name to use as a default when deploying the topic operator, if no image is specified as theimagein the topic operator config of the Kafka cluster ConfigMap. -
STRIMZI_DEFAULT_ZOOKEEPER_IMAGE -
Optional, default
strimzi/zookeeper:latest. The image name to use as a default when deploying Zookeeper, if no image is specified as thezookeeper-imagein the Kafka cluster ConfigMap. -
STRIMZI_DEFAULT_TLS_SIDECAR_ZOOKEEPER_IMAGE -
Optional, default
strimzi/zookeeper-stunnel:latest. The image name to use as a default when deploying the sidecar container which provides TLS support for Zookeeper, if no image is specified as thespec.zookeeper.tlsSidecar.imagein the Kafka cluster ConfigMap. -
STRIMZI_LOG_LEVEL -
Optional, default
INFO. The level for printing logging messages. The value can be set to:ERROR,WARNING,INFO,DEBUGandTRACE. -
STRIMZI_DEFAULT_TLS_SIDECAR_TOPIC_OPERATOR_IMAGE -
Optional, default
strimzi/topic-operator-stunnel:latest. The image name to use as a default when deploying the sidecar container which provides TLS support for the Topic Operator, if no image is specified as thespec.topicOperator.tlsSidecar.imagein the Kafka cluster ConfigMap.
3.4.1. Watching multiple namespaces
The STRIMZI_NAMESPACE environment variable can be used to configure a single operator instance
to operate in multiple namespaces. For each namespace given, the operator will watch for cluster ConfigMaps
and perform periodic reconciliation. To be able to do this, the operator’s ServiceAccount needs
access to the necessary resources in those other namespaces. This can be done by creating an additional
RoleBinding in each of those namespaces, associating the operator’s ServiceAccount
(strimzi-cluster-operator in the examples) with the operator’s
Role (strimzi-operator-role in the examples).
Suppose, for example, that a operator deployed in namespace foo needs to operate in namespace bar.
The following RoleBinding would grant the necessary permissions:
barapiVersion: v1
kind: RoleBinding
metadata:
name: strimzi-cluster-operator-binding-bar
namespace: bar
labels:
app: strimzi
subjects:
- kind: ServiceAccount
name: strimzi-cluster-operator
namespace: foo
roleRef:
kind: Role
name: strimzi-cluster-operator-role
apiGroup: v14. Topic Operator
The Topic Operator is in charge of managing topics in a Kafka cluster. The Topic Operator is deployed as a process running inside a OpenShift or Kubernetes cluster. It can be deployed through the Cluster Operator or "manually" through provided YAML files.
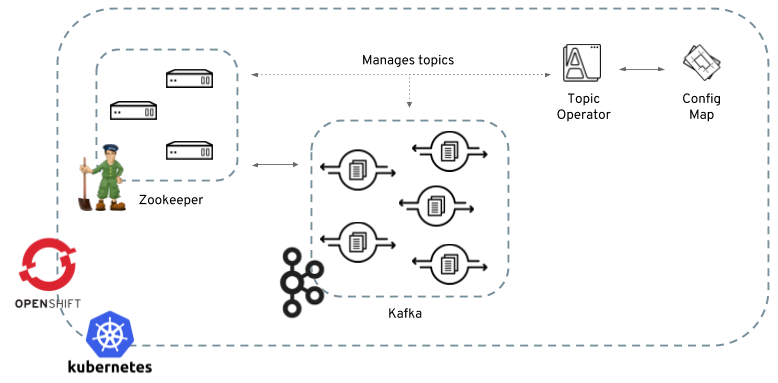
The role of the Topic Operator is to keep a set of OpenShift or Kubernetes ConfigMaps describing Kafka topics in-sync with corresponding Kafka topics.
Specifically:
-
if a ConfigMap is created, the operator will create the topic it describes
-
if a ConfigMap is deleted, the operator will delete the topic it describes
-
if a ConfigMap is changed, the operator will update the topic it describes
And also, in the other direction:
-
if a topic is created, the operator will create a ConfigMap describing it
-
if a topic is deleted, the operator will create the ConfigMap describing it
-
if a topic is changed, the operator will update the ConfigMap describing it
This is beneficial to a OpenShift or Kubernetes centric style of deploying applications, because it allows you to declare a ConfigMap as part of your applications deployment and the operator will take care of creating the topic for you, so your application just needs to deal with producing and/or consuming from the necessary topics.
Should the topic be reconfigured, reassigned to different Kafka nodes and so on, the ConfigMap will always be up to date.
4.1. Reconciliation
A fundamental problem that the operator has to solve is that there is no single source of truth: Both the ConfigMap and the topic can be modified independently of the operator. Complicating this, the Topic Operator might not always be able to observe changes at each end in real time (for example, the operator might be down).
To resolve this, the operator maintains its own private copy of the information about each topic. When a change happens either in the Kafka cluster, or in OpenShift or Kubernetes, it looks at both the state of the other system, and at its private copy in order to determine what needs to change to keep everything in sync. The same thing happens whenever the operator starts, and periodically while its running.
For example, suppose the Topic Operator is not running, and a ConfigMap "my-topic" gets created. When the operator starts it will lack a private copy of "my-topic", so it can infer that the ConfigMap has been created since it was last running. The operator will create the topic corresponding to "my-topic" and also store a private copy of the metadata for "my-topic".
The private copy allows the operator to cope with scenarios where the topic config gets changed both in Kafka and in OpenShift or Kubernetes, so long as the changes are not incompatible (for example, both changing the same topic config key, but to different values). In the case of incompatible changes, the Kafka configuration wins, and the ConfigMap will be updated to reflect that. Defaulting to the Kafka configuration ensures that, in the worst case, data won’t be lost.
The private copy is held in the same ZooKeeper ensemble used by Kafka itself. This mitigates availability concerns, because if ZooKeeper is not running then Kafka itself cannot run, so the operator will be no less available than it would even if it was stateless.
4.2. Usage Recommendations
-
Try to either always operate on ConfigMaps or always operate directly on topics.
-
When creating a ConfigMap:
-
Remember that the name cannot be easily changed later.
-
Choose a name for the ConfigMap that reflects the name of the topic it describes.
-
Ideally the ConfigMap’s
metadata.nameshould be the same as itsdata.name. To do this, the topic name will have to be a valid Kubernetes resource name.
-
-
When creating a topic:
-
Remember that the name cannot be easily changed later.
-
It is best to use a name that is a valid Kubernetes resource name, otherwise the operator will have to sanitize the name when creating the corresponding ConfigMap.
-
4.3. Format of the ConfigMap
By default, the operator only considers ConfigMaps having the label strimzi.io/kind=topic,
but this is configurable via the STRIMZI_CONFIGMAP_LABELS environment variable.
The data of such ConfigMaps supports the following keys:
name-
The name of the topic. Optional; if this is absent the name of the ConfigMap itself is used.
partitions-
The number of partitions of the Kafka topic. This can be increased, but not decreased. Required.
replicas-
The number of replicas of the Kafka topic. This cannot be larger than the number of nodes in the Kafka cluster. Required.
config-
A string in JSON format representing the topic configuration. Optional, defaulting to the empty set.
4.4. Example
This example shows how to create a topic called "orders" with 10 partitions and 2 replicas.
4.4.1. On Kubernetes
-
The ConfigMap has to be prepared:
Topic declaration ConfigMapapiVersion: v1 kind: ConfigMap metadata: name: orders labels: strimzi.io/kind: topic strimzi.io/cluster: my-cluster data: name: orders partitions: "10" replicas: "2"Because the
configkey is omitted from thedatathe topic’s config will be empty, and thus default to the Kafka broker default. -
The ConfigMap should be created in Kubernetes:
kubectl create -f orders-topic.yaml -
In case the topic should be later changed to retention time to 4 days, the
orders-topic.yamlfile can be updated:Topic declaration ConfigMap with "config" updateapiVersion: v1 kind: ConfigMap metadata: name: orders labels: strimzi.io/kind: topic strimzi.io/cluster: my-cluster data: name: orders partitions: "10" replicas: "2" config: '{ "retention.ms":"345600000" }' -
The changes in the file have to be applied on Kubernetes using
kubectl update -f.
|
Note
|
When the Topic Operator is deployed manually the strimzi.io/cluster label is not necessary.
|
4.4.2. On OpenShift
-
The ConfigMap has to be prepared:
Topic declaration ConfigMapapiVersion: v1 kind: ConfigMap metadata: name: orders labels: strimzi.io/kind: topic strimzi.io/cluster: my-cluster data: name: orders partitions: "10" replicas: "2"Because the
configkey is omitted from thedatathe topic’s config will be empty, and thus default to the Kafka broker default. -
The ConfigMap should be created in OpenShift:
oc create -f orders-topic.yaml -
In case the topic should be later changed to retention time to 4 days, the
orders-topic.yamlfile can be updated:Topic declaration ConfigMap with "config" updateapiVersion: v1 kind: ConfigMap metadata: name: orders labels: strimzi.io/kind: topic strimzi.io/cluster: my-cluster data: name: orders partitions: "10" replicas: "2" config: '{ "retention.ms":"345600000" }' -
The changes in the file have to be updated on OpenShift using
oc update -f.
|
Note
|
When the Topic Operator is deployed manually the strimzi.io/cluster label is not necessary.
|
4.5. Unsupported operations
-
The
data.namecannot be changed key in a ConfigMap, because Kafka does not support changing topic names. -
The
data.partitionscannot be decreased, because Kafka does not support this. -
Increasing
data.partitionsfor topics with keys should be exercised with caution, as it will change how records are partitioned.
4.6. Operator environment
The operator is configured from environment variables:
-
STRIMZI_CONFIGMAP_LABELS– The label selector used to identify ConfigMaps to be managed by the operator. Default:strimzi.io/kind=topic. -
STRIMZI_ZOOKEEPER_SESSION_TIMEOUT_MS– The Zookeeper session timeout, in milliseconds. For example10000. Default:20000(20 seconds). -
STRIMZI_KAFKA_BOOTSTRAP_SERVERS– The list of Kafka bootstrap servers. This variable is mandatory. -
STRIMZI_ZOOKEEPER_CONNECT– The Zookeeper connection information. This variable is mandatory. -
STRIMZI_FULL_RECONCILIATION_INTERVAL_MS– The interval between periodic reconciliations, in milliseconds. -
STRIMZI_TOPIC_METADATA_MAX_ATTEMPTS– The number of attempts for getting topics metadata from Kafka. The time between each attempt is defined as an exponential back-off. You might want to increase this value when topic creation could take more time due to its larger size (that is, many partitions/replicas). Default6. -
STRIMZI_LOG_LEVEL– The level for printing logging messages. The value can be set to:ERROR,WARNING,INFO,DEBUGandTRACE. DefaultINFO. -
STRIMZI_TLS_ENABLED– For enabling the TLS support so encrypting the communication with Kafka brokers. Defaulttrue -
STRIMZI_TRUSTSTORE_LOCATION– The path to the truststore containing certificates for enabling TLS based communication. This variable is mandatory only if TLS is enabled throughSTRIMZI_TLS_ENABLED. -
STRIMZI_TRUSTSTORE_PASSWORD– The password for accessing the truststore defined bySTRIMZI_TRUSTSTORE_LOCATION. This variable is mandatory only if TLS is enabled throughSTRIMZI_TLS_ENABLED. -
STRIMZI_KEYSTORE_LOCATION– The path to the keystore containing private keys for enabling TLS based communication. This variable is mandatory only if TLS is enabled throughSTRIMZI_TLS_ENABLED. -
STRIMZI_KEYSTORE_PASSWORD– The password for accessing the keystore defined bySTRIMZI_KEYSTORE_LOCATION. This variable is mandatory only if TLS is enabled throughSTRIMZI_TLS_ENABLED.
If the operator configuration needs to be changed the process must be killed and restarted. Since the operator is intended to execute within OpenShift or Kubernetes, this can be achieved by deleting the pod.
4.7. Resource limits and requests
The Topic Operator can run with resource limits:
-
When it is deployed by the Cluster Operator these can be specified in the
resourceskey of thetopic-operator-config. -
When it is not deployed by the Cluster Operator these can be specified on the Deployment in the usual way.
4.7.1. Minimum Resource Requirements
Testing has shown that the topic operator functions adequately with 96Mi of memory and 100m CPU when watching two topics. It is therefore recommended to use these as a minimum when configuring resource requests and not to run it with lower limits than these. If the Kafka cluster has more than a handful of topics more generous requests and limits will be necessary.
5. Security
The Strimzi project supports data encryption of communication between the different Kafka and Strimzi components (Kafka brokers, Zookeeper nodes, Kafka Connect and Strimzi Topic Operator) by means of the SSL/TLS protocol. This makes it possible to encrypt data transferred between Kafka brokers (interbroker communication), between Zookeeper nodes (internodal communication), and between clients and Kafka brokers. For the Kafka and Strimzi components, TLS certificates are also used for authentication.
The Cluster Operator sets up the SSL/TLS certificates to provide this encryption and authentication.
5.1. Certificates
Each component needs its own private and public keys in order to support encryption. The public key has to be signed by a certificate authority (CA) in order to have a related X.509 certificate for providing server authentication and encrypting the communication channel with the client (which could be another broker as well). All component certificates are signed by a Certification Authority (CA) called cluster CA. Another CA is used for authentication of Kafka clients connecting to Kafka brokers. This CA is called clients CA. The CAs themselves use self-signed certificates.
All of the generated certificates are saved as Secrets in the OpenShift or Kubernetes cluster, named as follows:
<cluster-name>-cluster-ca-
Contains the private and public keys of the cluster CA which is used for signing server certificates for the Kafka and Strimzi components (Kafka brokers, Zookeeper nodes, and so on).
<cluster-name>-cluster-ca-cert-
Contains only the public key of the cluster CA. The public key used by Kafka clients to verify the identity of the Kafka brokers they are connecting to (TLS server authentication).
<cluster-name>-clients-ca-
Contains the private and public keys of the clients CA. The clients CA is used for TLS client authentication of Kafka clients when connecting to Kafka brokers.
<cluster-name>-clients-ca-cert-
Contains only the public key of the client CA. The public key is used by the Kafka brokers to verify the identity of Kafka clients when TLS client authentication is used.
<cluster-name>-kafka-brokers-
Contains all the Kafka broker private and public keys (certificates signed with the cluster CA).
<cluster-name>-zookeeper-nodes-
Contains all the Zookeeper node private and public keys (certificates signed with the cluster CA).
<cluster-name>-topic-operator-certs-
Contains the private and public keys (certificates signed with the cluster CA) used for encrypting communication between the Topic Operator and Kafka or Zookeeper.
All the keys are 2048 bits in size and are valid for 365 days from initial generation.
|
Note
|
"certificates rotation" for generating new ones on their expiration will be supported in future releases. |
5.2. Interbroker Kafka Communication
Communication between brokers is done through the REPLICATION listener on port 9091, which is encrypted by default.
5.3. Zookeeper Communication
By deploying an stunnel sidecar within every Zookeeper pod, the Cluster Operator is able to provide data encryption and authentication between Zookeeper nodes in a cluster.
The stunnel sidecar proxies all Zookeeper traffic, TLS decrypting data upon entry into a Zookeeper pod and TLS encrypting data upon departure from a Zookeeper pod.
This TLS encrypting stunnel proxy is instantiated from the spec.zookeeper.stunnelImage specified in the Kafka resource.
5.4. Kafka Client connections via TLS
Encrypted communication between Kafka brokers and clients is provided through the CLIENTTLS listener on port 9093.
|
Note
|
You can use the CLIENT listener on port 9092 for unencrypted communication with brokers.
|
If a Kafka client wants to connect to the encrypted listener (CLIENTTLS) on port 9093, it needs to trust the cluster CA certificate in order to verify the broker certificate received during the SSL/TLS handshake.
The cluster CA certificate can be extracted from the generated <cluster-name>-cluster-ca-cert Secret.
On Kubernetes, the certificate can be extracted with the following command:
kubectl get secret <cluster-name>-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crtOn OpenShift, the certificate can be extracted with the following command:
oc get secret <cluster-name>-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crtThe Kafka client has to be configured to trust certificates signed by this CA. For the Java-based Kafka Producer, Consumer and Streams APIs, you can do this by importing the CA certificate into the JVM’s truststore using the following keytool command:
keytool -keystore client.truststore.jks -alias CARoot -import -file ca.crtFinally, in order to configure the Kafka client, following properties should be specified:
-
security.protocol: SSL is the value for using encryption. -
ssl.truststore.location: the truststore location where the certificates were imported. -
ssl.truststore.password: password for accessing the truststore. This property can be omitted if it is not needed by the truststore.
The current implementation does not support Subject Alternative Names (SAN) so the hostname verification should be disabled on the client side.
For doing so the ssl.endpoint.identification.algorithm property needs to be set as empty.
Appendix A: Frequently Asked Questions
A.1. Cluster Operator
A.1.1. Log contains warnings about failing to acquire lock
For each cluster, the Cluster Operator always executes only one operation at a time. The Cluster Operator uses locks to make sure that there are never two parallel operations running for the same cluster. In case an operation requires more time to complete, other operations will wait until it is completed and the lock is released.
- INFO
-
Examples of cluster operations are cluster creation, rolling update, scale down or scale up and so on.
If the wait for the lock takes too long, the operation times out and the following warning message will be printed to the log:
2018-03-04 17:09:24 WARNING AbstractClusterOperations:290 - Failed to acquire lock for kafka cluster lock::kafka::myproject::my-clusterDepending on the exact configuration of STRIMZI_FULL_RECONCILIATION_INTERVAL_MS and STRIMZI_OPERATION_TIMEOUT_MS, this
warning message may appear regularly without indicating any problems. The operations which time out will be picked up by
the next periodic reconciliation. It will try to acquire the lock again and execute.
Should this message appear periodically even in situations when there should be no other operations running for a given cluster, it might indicate that due to some error the lock was not properly released. In such cases it is recommended to restart the cluster operator.
Appendix B: Installing OpenShift or Kubernetes cluster
The easiest way to get started with OpenShift or Kubernetes is using the Minikube, Minishift or oc cluster up
utilities. This section provides basic guidance on how to use them. More details are provided on the websites of
the tools themselves.
B.1. Kubernetes
In order to interact with a Kubernetes cluster the kubectl
utility needs to be installed.
The easiest way to get a running Kubernetes cluster is using Minikube. Minikube can be downloaded and installed
from the Kubernetes website. Depending on the number of brokers
you want to deploy inside the cluster and if you need Kafka Connect running as well, it could be worth running Minikube
at least with 4 GB of RAM instead of the default 2 GB.
Once installed, it can be started using:
minikube start --memory 4096B.2. OpenShift
In order to interact with an OpenShift cluster, the oc utility is needed.
An OpenShift cluster can be started in two different ways. The oc utility can start a cluster locally using the
command:
oc cluster upThis command requires Docker to be installed. More information about this way can be found here.
Another option is to use Minishift. Minishift is an OpenShift installation within a VM. It can be downloaded and
installed from the Minishift website. Depending on the number of brokers
you want to deploy inside the cluster and if you need Kafka Connect running as well, it could be worth running Minishift
at least with 4 GB of RAM instead of the default 2 GB.
Once installed, Minishift can be started using the following command:
minishift start --memory 4GBAppendix C: Custom Resource API Reference
C.1. Kafka kind v1alpha1 kafka.strimzi.io
| Field | Description |
|---|---|
spec |
|
additionalProperties |
|
map |
C.2. KafkaAssemblySpec type v1alpha1 kafka.strimzi.io
Used in: KafkaAssembly
| Field | Description |
|---|---|
kafka |
Configuration of the Kafka cluster |
zookeeper |
Configuration of the Zookeeper cluster |
topicOperator |
Configuration of the Topic Operator |
additionalProperties |
|
map |
C.3. Kafka type v1alpha1 kafka.strimzi.io
Used in: KafkaAssemblySpec
| Field | Description |
|---|---|
replicas |
The number of pods in the cluster. |
integer |
|
image |
The docker image for the pods. |
string |
|
storage |
Storage configuration (disk). Cannot be updated. The type depends on the value of the |
brokerRackInitImage |
The image of the init container used for initializing the |
string |
|
livenessProbe |
Pod liveness checking. |
readinessProbe |
Pod readiness checking. |
jvmOptions |
JVM Options for pods |
affinity |
Pod affinity rules.See external documentation of core/v1 affinity |
metrics |
The Prometheus JMX Exporter configuration. See https://github.com/prometheus/jmx_exporter for details of the structure of this configuration. |
map |
|
tlsSidecar |
TLS sidecar configuration |
additionalProperties |
|
map |
|
config |
The kafka broker config. Properties with the following prefixes cannot be set: listeners, advertised., broker., listener.name.replication., listener.name.clienttls.ssl.truststore, listener.name.clienttls.ssl.keystore, host.name, port, inter.broker.listener.name, sasl., ssl., security., password., principal.builder.class, log.dir, zookeeper.connect, zookeeper.set.acl, super.user |
map |
|
logging |
Logging configuration for Kafka The type depends on the value of the |
rack |
Configuration of the |
resources |
Resource constraints (limits and requests). |
tolerations |
Pod’s tolerations.See external documentation of core/v1 tolerations |
Toleration array |
C.4. EphemeralStorage type v1alpha1 kafka.strimzi.io
The type property is a discriminator that distinguishes the use of the type EphemeralStorage from PersistentClaimStorage.
It must have the value ephemeral for the type EphemeralStorage.
| Field | Description |
|---|---|
additionalProperties |
|
map |
|
type |
Must be |
string |
C.5. PersistentClaimStorage type v1alpha1 kafka.strimzi.io
The type property is a discriminator that distinguishes the use of the type PersistentClaimStorage from EphemeralStorage.
It must have the value persistent-claim for the type PersistentClaimStorage.
| Field | Description |
|---|---|
additionalProperties |
|
map |
|
class |
The storage class to use for dynamic volume allocation. |
string |
|
deleteClaim |
Specifies if the persistent volume claim has to be deleted when the cluster is un-deployed. |
boolean |
|
selector |
Specifies a specific persistent volume to use. It contains a matchLabels field which defines an inner JSON object with key:value representing labels for selecting such a volume. |
map |
|
size |
When type=persistent-claim, defines the size of the persistent volume claim (i.e 1Gi). Mandatory when type=persistent-claim. |
string |
|
type |
Must be |
string |
C.6. Probe type v1alpha1 kafka.strimzi.io
| Field | Description |
|---|---|
additionalProperties |
|
map |
|
initialDelaySeconds |
The initial delay before first the health is first checked. |
integer |
|
timeoutSeconds |
The timeout for each attempted health check. |
integer |
C.7. JvmOptions type v1alpha1 kafka.strimzi.io
| Field | Description |
|---|---|
-XX |
A map of -XX options to the JVM |
map |
|
-Xms |
-Xms option to to the JVM |
string |
|
-Xmx |
-Xmx option to to the JVM |
string |
|
-server |
-server option to to the JVM |
boolean |
C.8. Sidecar type v1alpha1 kafka.strimzi.io
Used in: Kafka, TopicOperator, Zookeeper
| Field | Description |
|---|---|
image |
The docker image for the container |
string |
|
resources |
Resource constraints (limits and requests). |
C.9. Resources type v1alpha1 kafka.strimzi.io
Used in: Kafka, KafkaConnectAssemblySpec, KafkaConnectS2IAssemblySpec, Sidecar, TopicOperator, Zookeeper
| Field | Description |
|---|---|
additionalProperties |
|
map |
|
limits |
Resource limits applied at runtime. |
requests |
Resource requests applied during pod scheduling. |
C.10. CpuMemory type v1alpha1 kafka.strimzi.io
Used in: Resources
| Field | Description |
|---|---|
additionalProperties |
|
map |
|
cpu |
CPU |
string |
|
memory |
Memory |
string |
C.11. InlineLogging type v1alpha1 kafka.strimzi.io
The type property is a discriminator that distinguishes the use of the type InlineLogging from ExternalLogging.
It must have the value inline for the type InlineLogging.
| Field | Description |
|---|---|
loggers |
|
map |
|
type |
|
string |
C.12. ExternalLogging type v1alpha1 kafka.strimzi.io
The type property is a discriminator that distinguishes the use of the type ExternalLogging from InlineLogging.
It must have the value external for the type ExternalLogging.
| Field | Description |
|---|---|
name |
|
string |
|
type |
|
string |
C.13. Rack type v1alpha1 kafka.strimzi.io
Used in: Kafka
| Field | Description |
|---|---|
additionalProperties |
|
map |
|
topologyKey |
A key that matches labels assigned to the OpenShift or Kubernetes cluster nodes. The value of the label is used to set the broker’s |
string |
C.14. Zookeeper type v1alpha1 kafka.strimzi.io
Used in: KafkaAssemblySpec
| Field | Description |
|---|---|
replicas |
The number of pods in the cluster. |
integer |
|
image |
The docker image for the pods. |
string |
|
storage |
Storage configuration (disk). Cannot be updated. The type depends on the value of the |
livenessProbe |
Pod liveness checking. |
readinessProbe |
Pod readiness checking. |
jvmOptions |
JVM Options for pods |
affinity |
Pod affinity rules.See external documentation of core/v1 affinity |
metrics |
The Prometheus JMX Exporter configuration. See https://github.com/prometheus/jmx_exporter for details of the structure of this configuration. |
map |
|
tlsSidecar |
TLS sidecar configuration |
additionalProperties |
|
map |
|
config |
The zookeeper broker config. Properties with the following prefixes cannot be set: server., dataDir, dataLogDir, clientPort, authProvider, quorum.auth, requireClientAuthScheme |
map |
|
logging |
Logging configuration for Zookeeper The type depends on the value of the |
resources |
Resource constraints (limits and requests). |
tolerations |
Pod’s tolerations.See external documentation of core/v1 tolerations |
Toleration array |
C.15. TopicOperator type v1alpha1 kafka.strimzi.io
Used in: KafkaAssemblySpec
| Field | Description |
|---|---|
watchedNamespace |
The namespace the Topic Operator should watch. |
string |
|
image |
The image to use for the topic operator |
string |
|
reconciliationIntervalSeconds |
Interval between periodic reconciliations. |
integer |
|
zookeeperSessionTimeoutSeconds |
Timeout for the Zookeeper session |
integer |
|
affinity |
Pod affinity rules.See external documentation of core/v1 affinity |
resources |
|
topicMetadataMaxAttempts |
The number of attempts at getting topic metadata |
integer |
|
tlsSidecar |
TLS sidecar configuration |
additionalProperties |
|
map |
|
logging |
Logging configuration The type depends on the value of the |
C.16. KafkaConnect kind v1alpha1 kafka.strimzi.io
| Field | Description |
|---|---|
spec |
|
additionalProperties |
|
map |
C.17. KafkaConnectAssemblySpec type v1alpha1 kafka.strimzi.io
Used in: KafkaConnectAssembly
| Field | Description |
|---|---|
replicas |
|
integer |
|
image |
The docker image for the pods. |
string |
|
livenessProbe |
Pod liveness checking. |
readinessProbe |
Pod readiness checking. |
jvmOptions |
JVM Options for pods |
affinity |
Pod affinity rules.See external documentation of core/v1 affinity |
metrics |
The Prometheus JMX Exporter configuration. See https://github.com/prometheus/jmx_exporter for details of the structure of this configuration. |
map |
|
additionalProperties |
|
map |
|
config |
The Kafka Connect configuration. Properties with the following prefixes cannot be set: ssl., sasl., security., listeners, plugin.path, rest. |
map |
|
logging |
Logging configuration for Kafka Connect The type depends on the value of the |
resources |
Resource constraints (limits and requests). |
tolerations |
Pod’s tolerations.See external documentation of core/v1 tolerations |
Toleration array |
C.18. KafkaConnectS2I kind v1alpha1 kafka.strimzi.io
| Field | Description |
|---|---|
spec |
|
additionalProperties |
|
map |
C.19. KafkaConnectS2IAssemblySpec type v1alpha1 kafka.strimzi.io
Used in: KafkaConnectS2IAssembly
| Field | Description |
|---|---|
replicas |
|
integer |
|
image |
The docker image for the pods. |
string |
|
livenessProbe |
Pod liveness checking. |
readinessProbe |
Pod readiness checking. |
jvmOptions |
JVM Options for pods |
affinity |
Pod affinity rules.See external documentation of core/v1 affinity |
metrics |
The Prometheus JMX Exporter configuration. See https://github.com/prometheus/jmx_exporter for details of the structure of this configuration. |
map |
|
additionalProperties |
|
map |
|
config |
The Kafka Connect configuration. Properties with the following prefixes cannot be set: ssl., sasl., security., listeners, plugin.path, rest. |
map |
|
insecureSourceRepository |
|
boolean |
|
logging |
Logging configuration for Kafka Connect The type depends on the value of the |
resources |
Resource constraints (limits and requests). |
tolerations |
Pod’s tolerations.See external documentation of core/v1 tolerations |
Toleration array |
Appendix D: Metrics
This section describes how to deploy a Prometheus server for scraping metrics from the Kafka cluster and showing them using a Grafana dashboard. The resources provided are examples to show how Kafka metrics can be stored in Prometheus: They are not a recommended configuration, and further support should be available from the Prometheus and Grafana communities.
When adding Prometheus and Grafana servers to an Apache Kafka deployment using minikube or minishift, the memory available to the virtual machine should be increased (to 4 GB of RAM, for example, instead of the default 2 GB). Information on how to increase the default amount of memory can be found in the following section Installing OpenShift or Kubernetes cluster.
D.1. Deploying on OpenShift
D.1.1. Prometheus
The Prometheus server configuration uses a service discovery feature in order to discover the pods in the cluster from which it gets metrics.
In order to have this feature working, it is necessary for the service account used for running the Prometheus service pod to have access to the API server to get the pod list. By default the service account prometheus-server is used.
export NAMESPACE=[namespace]
oc login -u system:admin
oc create sa prometheus-server
oc adm policy add-cluster-role-to-user cluster-reader system:serviceaccount:${NAMESPACE}:prometheus-server
oc login -u developerwhere [namespace] is the namespace/project where the Apache Kafka cluster was deployed.
Finally, create the Prometheus service by running
oc create -f https://raw.githubusercontent.com/strimzi/strimzi-kafka-operator/master/metrics/examples/prometheus/kubernetes.yamlD.1.2. Grafana
A Grafana server is necessary only to get a visualisation of the Prometheus metrics.
To deploy Grafana on OpenShift, the following commands should be executed:
oc create -f https://raw.githubusercontent.com/strimzi/strimzi-kafka-operator/master/metrics/examples/grafana/kubernetes.yamlD.2. Deploying on Kubernetes
D.2.1. Prometheus
The Prometheus server configuration uses a service discovery feature in order to discover the pods in the cluster from which it gets metrics.
If the RBAC is enabled in your Kubernetes deployment then in order to have this feature working, it is necessary for the service account used for running the Prometheus service pod to have access to the API server to get the pod list. By default the service account prometheus-server is used.
export NAMESPACE=[namespace]
kubectl create sa prometheus-server
kubectl create -f https://raw.githubusercontent.com/strimzi/strimzi-kafka-operator/master/metrics/examples/prometheus/cluster-reader.yaml
kubectl create clusterrolebinding read-pods-binding --clusterrole=cluster-reader --serviceaccount=${NAMESPACE}:prometheus-serverwhere [namespace] is the namespace/project where the Apache Kafka cluster was deployed.
Finally, create the Prometheus service by running
kubectl apply -f https://raw.githubusercontent.com/strimzi/strimzi-kafka-operator/master/metrics/examples/prometheus/kubernetes.yamlD.2.2. Grafana
A Grafana server is necessary only to get a visualisation of Prometheus metrics.
To deploy Grafana on Kubernetes, the following commands should be executed:
kubectl apply -f https://raw.githubusercontent.com/strimzi/strimzi-kafka-operator/master/metrics/examples/grafana/kubernetes.yamlD.3. Grafana dashboard
As an example, and in order to visualize the exported metrics in Grafana, the simple dashboard kafka-dashboard.json file is provided.
The Prometheus data source, and the above dashboard, can be set up in Grafana by following these steps.
|
Note
|
For accessing the dashboard, you can use the port-forward command for forwarding traffic from the Grafana pod to the host. For example, you can access the Grafana UI by running oc port-forward grafana-1-fbl7s 3000:3000 (or using kubectl instead of oc) and then pointing a browser to http://localhost:3000.
|
-
Access to the Grafana UI using
admin/admincredentials.
-
Click on the "Add data source" button from the Grafana home in order to add Prometheus as data source.
-
Fill in the information about the Prometheus data source, specifying a name and "Prometheus" as type. In the URL field, the connection string to the Prometheus server (that is,
http://prometheus:9090) should be specified. After "Add" is clicked, Grafana will test the connection to the data source.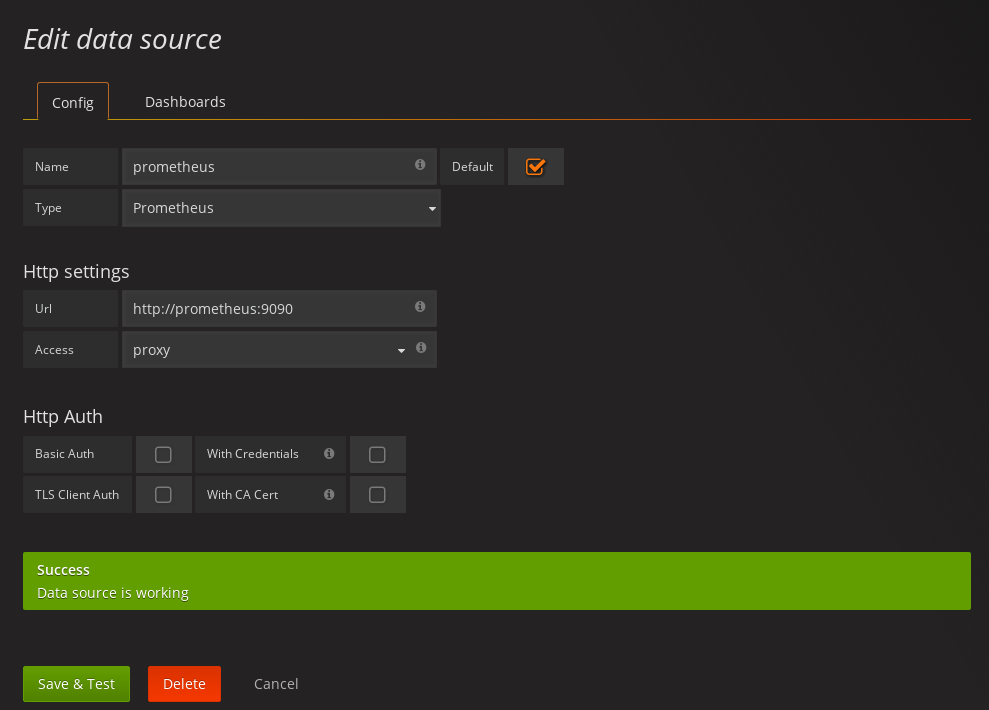
-
From the top left menu, click on "Dashboards" and then "Import" to open the "Import Dashboard" window where the provided
kafka-dashboard.jsonfile can be imported or its content pasted.
-
After importing the dashboard, the Grafana home should show with some initial metrics about CPU and JVM memory usage. When the Kafka cluster is used (creating topics and exchanging messages) the other metrics, like messages in and bytes in/out per topic, will be shown.