Apache Kafka MirrorMaker replicates data across two Kafka clusters, within or across data centers. MirrorMaker takes messages from a source Kafka cluster and writes them to a target Kafka cluster, which makes it a very useful tool for those wanting to ensure the availability and consistency of their enterprise data. And who doesn’t? Typical scenarios where you might consider MirrorMaker are for disaster recovery and data aggregation.
With the release of Strimzi 0.17, things become a little more interesting with the introduction of support for MirrorMaker 2.0. MirrorMaker 2.0 represents a significant shift in the way you synchronize data between replicated Kafka clusters, promising a more dynamic and automated approach to topic replication between clusters.
MirrorMaker 2.0 - the Kafka Connect(ion)
Before we get into some of the implementation detail, there’s something you’ll be keen to know about Mirror Maker 2.0. Is the sequel better than the original? Well, how does bidirectional replication sound? And what about topic configuration synchronization and offset tracking? Pretty good, right?
This is MirrorMaker ready to fulfill the potential we always knew it had.
The previous version of MirrorMaker relies on configuration of a source consumer and target producer pair to synchronize Kafka clusters.
MirrorMaker 2.0 is instead based on Kafka Connect, which is a bit of a game changer. For a start, there is no longer a need to configure producers and consumers to make your connection.
Using MirrorMaker 2.0, you just need to identify your source and target clusters. You then configure and deploy MirrorMaker 2.0 to make the connection between those clusters.
This image shows a single source cluster, but you can have multiple source clusters, which is something that was not possible with old MirrorMaker.
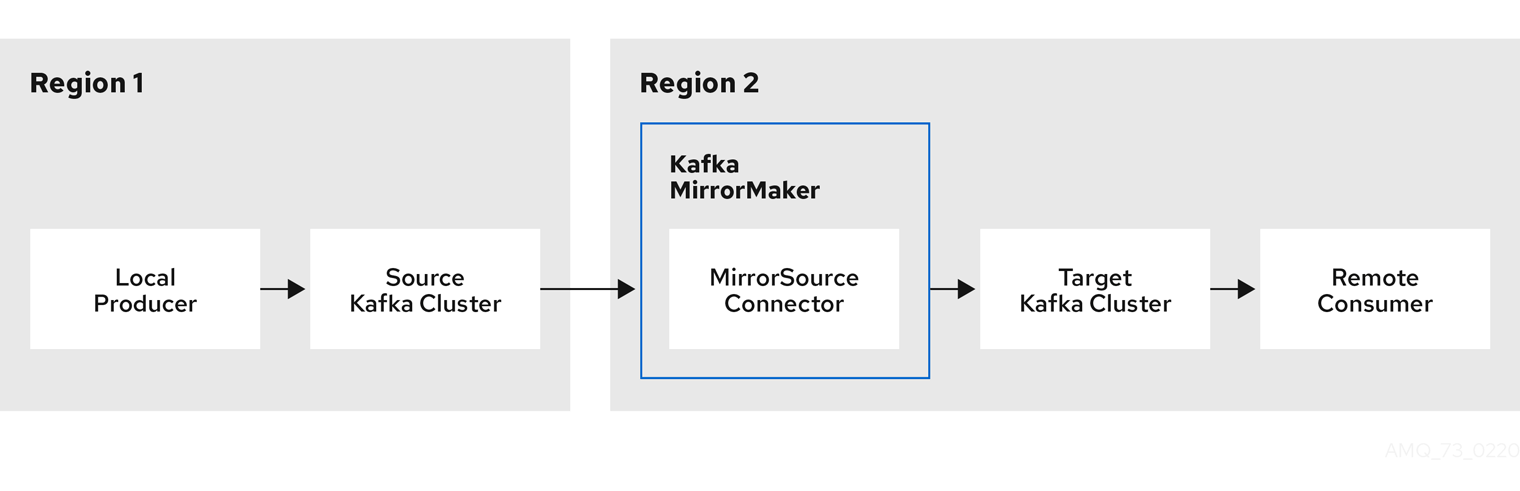
MirrorMaker 2.0 connectors – remember, we’re based on Kafka Connect now – and related internal topics (offset sync, checkpoint and heartbeat) help manage the transfer and synchronization of data between the clusters.
Using Strimzi, you configure a KafkaMirrorMaker2 resource to define the Kafka Connect deployment, including the connection details of the source and target clusters, and start running a set of MirrorMaker 2.0 connectors to make the connection.
Different to the previous version of MirrorMaker, radically different, but different doesn’t mean more complicated here. In fact, once you know the essentials, setting up is rather straightforward.
Bidirectional opportunities
In the previous version of MirrorMaker, the topic name in the source cluster is automatically created in the downstream cluster. Fine, to a point. But there is no distinction between Topic-1.Partition-1 in the source cluster and Topic-1.Partition-1 in the target cluster. Essentially, you are limited to active/passive synchronization, because active/active replication would cause an infinite loop. MirrorMaker 2.0 solves this by introducing the concept of remote topics.
Remote topics are created from the originating cluster by the MirrorSourceConnector.
They are distinguished by automatic renaming that prepends the name of cluster to the name of the topic.
Our Topic-1.Partition-1 from the source cluster becomes the never-to-be-confused Cluster-1-Topic-1.Partition-1 in the target cluster.
A consumer in the target cluster can consume Topic-1.Partition-1 and Cluster-1-Topic-1.Partition-1 and maintain unambiguous consumer offsets.
As you can see here, remote topics can be easily identified, so there’s no possibility of messages being sent back and forth in a loop.
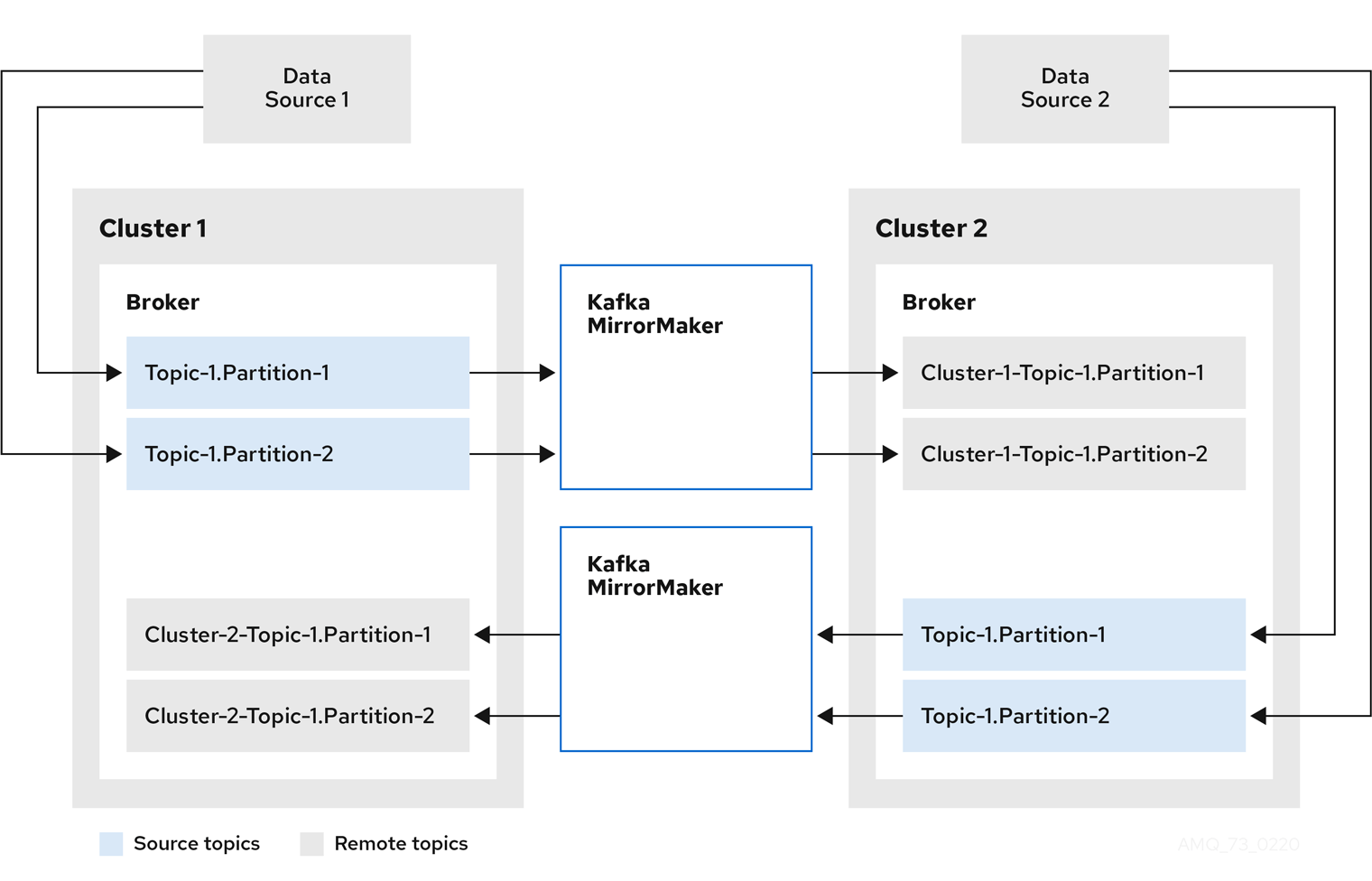
Why remote topic and not just source topic? Because each source cluster can also be a target cluster in a bidirectional configuration. This feature also means that it is no longer necessary to aggregate data in a separate cluster.
A rose might be a rose by any other name, but when it comes to replicating topics in MirrorMaker 2.0 we can’t afford such ambiguity. Particularly if we want to create a bidirectional configuration.
The approach to topic renaming opens up a world of bidirectional opportunities. You can now have an active/active cluster configuration that feeds data to and from each cluster. For this, you need a MirrorMaker 2.0 cluster at each destination, as shown in the previous image.
Self-regulating topic replication
Topic replication is defined using regular expression patterns to whitelist or blacklist topics:
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaMirrorMaker2
metadata:
name: my-mirror-maker2
spec:
# ...
mirrors:
- sourceCluster: "my-cluster-source"
targetCluster: "my-cluster-target"
topicsPattern: ".*"
# ...
You use topicsBlacklistPattern if you want to use blacklists.
This is pretty similar to MirrorMaker, but previously topic configuration was not replicated.
The target cluster had to be manually maintained to match topic configuration changes in the source cluster. Something easily overlooked, and typically requiring users to build their own automation to achieve at scale.
With MirrorMaker 2.0, the topic configuration is automatically synchronized between source and target clusters according to the topics defined in the MirrorMaker2 custom resource.
Configuration changes are propagated to remote topics so that new topics and partitions are detected and created.
By keeping topic properties synchronized, the need for consumer rebalancing due to topic changes is greatly reduced.
Offset tracking and mapping
In the previous version of MirrorMaker, the consumer offset of the source topic in the target cluster begins when the replication begins.
The __consumer_offsets topic is not mirrored.
So offsets of the source topic and its replicated equivalent can have two entirely different positions.
This was often problematic in a failover situation.
How to find the offset in the target cluster?
Strategies such as using timestamps can be adopted, but it adds complexity.
These issues entirely disappear with MirrorMaker 2.0.
Instead, we get simplicity and sophistication through the MirrorCheckpointConnector.
MirrorCheckpointConnector tracks and maps offsets for specified consumer groups using an offset sync topic and checkpoint topic.
The offset sync topic maps the source and target offsets for replicated topic partitions from record metadata.
A checkpoint is emitted from each source cluster and replicated in the target cluster through the checkpoint topic.
The checkpoint topic maps the last committed offset in the source and target cluster for replicated topic partitions in each consumer group.
If you want automatic failover, you can use Kafka’s new RemoteClusterUtils.java utility class by adding connect-mirror-client as a dependency to your consumers.
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>connect-mirror-client</artifactId>
<version>2.4.0</version>
</dependency>
The class translates the consumer group offset from the source cluster to the corresponding offset for the target cluster.
The consumer groups tracked by MirrorCheckpointConnector are dependent on those defined in a whitelist or blacklist:
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaMirrorMaker2
metadata:
name: my-mirror-maker2
spec:
# ...
mirrors:
- sourceCluster: "my-cluster-source"
targetCluster: "my-cluster-target"
groupsPattern: "group1|group2|group3"
# ...
You use groupsBlacklistPattern if you want to use blacklists.
Checking the connection
The old way of checking that MirrorMaker was working, on Kubernetes at least, was by using standard Kubernetes healthcheck probes to know when MirrorMaker can accept traffic and when it needs a restart.
MirrorMaker 2.0 periodically checks on the connection through its dedicated MirrorHeartbeatConnector.
MirrorHeartbeatConnector periodically checks connectivity between clusters.
A heartbeat is produced every second by the MirrorHeartbeatConnector into a heartbeat topic that is created on the local cluster.
If you have MirrorMaker 2.0 at both the remote and local locations, the heartbeat emitted at the remote location by the MirrorHeartbeatConnector is treated like any remote topic and mirrored by the MirrorSourceConnector at the local cluster.
The heartbeat topic makes it easy to check that the remote cluster is available and the clusters are connected.
If things go wrong, the heartbeat topic offset positions and time stamps can help with recovery and diagnosis.
Unleashing MirrorMaker 2.0
Okay, so let’s look at how you might approach the configuration of a MirrorMaker 2.0 deployment with the KafkaMirrorMaker2 resource.
When you define your MirrorMaker 2.0 configuration to set up a connection, you specify the sourceCluster and targetCluster, and the bootstrapServers for connection.
If you’re sticking with defaults, you don’t need to specify much more. Here’s a minimum configuration for MirrorMaker 2.0:
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaMirrorMaker2
metadata:
name: my-mirror-maker2
spec:
version: 2.4.0
connectCluster: "my-cluster-target"
clusters:
- alias: "my-cluster-source"
bootstrapServers: my-cluster-source-kafka-bootstrap:9092
- alias: "my-cluster-target"
bootstrapServers: my-cluster-target-kafka-bootstrap:9092
mirrors:
- sourceCluster: "my-cluster-source"
targetCluster: "my-cluster-target"
sourceConnector: {}
Note that the spec includes the Kafka Connect version and cluster alias with the connectCluster value,
as we’re using a Kafka Connect framework to make our connection.
The clusters properties define the Kafka clusters being synchronized, and the mirrors properties define the MirrorMaker 2.0 connectors.
You can build a more elaborate configuration. For example, you can add configuration to include replica nodes, which is the number of replica nodes in the Kafka Connect group, and TLS or SASL authentication for the source and target cluster too. Typical and sensible choices.
Here we create 3 replica nodes and use TLS authentication.
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaMirrorMaker2
metadata:
name: my-mirror-maker2
spec:
version: {DefaultKafkaVersion}
replicas: 3
connectCluster: "my-cluster-target"
clusters:
- alias: "my-cluster-source"
authentication:
certificateAndKey:
certificate: source.crt
key: source.key
secretName: my-user-source
type: tls
bootstrapServers: my-cluster-source-kafka-bootstrap:9092
tls:
trustedCertificates:
- certificate: ca.crt
secretName: my-cluster-source-cluster-ca-cert
- alias: "my-cluster-target"
authentication:
certificateAndKey:
certificate: target.crt
key: target.key
secretName: my-user-target
type: tls
bootstrapServers: my-cluster-target-kafka-bootstrap:9092
config:
config.storage.replication.factor: 1
offset.storage.replication.factor: 1
status.storage.replication.factor: 1
tls:
trustedCertificates:
- certificate: ca.crt
secretName: my-cluster-target-cluster-ca-cert
People can be confused by the idea of replicas and replication through MirrorMaker,
that’s why you’ll see replication between clusters often referred to as mirroring so that it’s not confused with
the replicas that represent the nodes replicated in a deployment.
If you don’t want to leave the defaults, you can also include configuration for the MirrorMaker 2.0 connectors and related internal topics.
The config overrides the default configuration options, so here we alter the replication factors for the internal topics:
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaMirrorMaker2
metadata:
name: my-mirror-maker2
spec:
# ...
mirrors:
# ...
sourceConnector:
config:
replication.factor: 1
offset-syncs.topic.replication.factor: 1
heartbeatConnector:
config:
heartbeats.topic.replication.factor: 1
checkpointConnector:
config:
checkpoints.topic.replication.factor: 1
You can see the full spec options in the KafkaMirrorMaker2 schema reference.
If, at this point, you’re wondering what happens if you’re using the old version of MirrorMaker, it’s still supported. And there are also plans to have a legacy mode in MirrorMaker 2.0 that creates topics without the cluster prefix, and doesn’t do the topic configuration mirroring. Basically, turning off the main differences between the original and the new version of MirrorMaker.
Embrace change
The Apache Kafka community understood that MirrorMaker was due an overhaul [KIP-382: MirrorMaker 2.0]. Key issues with using the original MirrorMaker were identified – manual topic configuration, the lack of support for active/active replication, and the inability to track offsets – and eradicated with MirrorMaker 2.0. The changes are bold, particularly moving to a Kafka Connect foundation. But the new design works so much better, particularly for backup and disaster recovery.
I hope this post has persuaded you of the benefits of MirrorMaker 2.0. With the release of Strimzi 0.17, you get example files to be able to try it. Tell us what you think.
Share this:
![]()
![]()
![]()
![]()
![]()