In our last blog post we looked at Open Policy Agent (OPA), and how it can be used with Strimzi for Kafka authorization. In this blog post we will look at how you can use Open Policy Agent and its Gatekeeper project to enforce policies when creating custom resources and explain why it might be useful to Strimzi users.
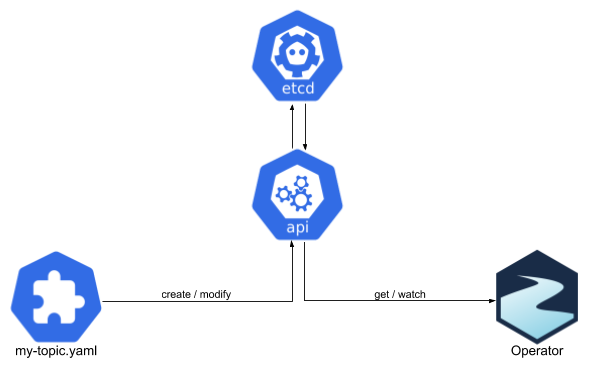
Strimzi uses the operator pattern to make running Apache Kafka on Kubernetes easy. We use Custom Resource Definitions (CRDs) to extend the Kubernetes API. When users want to create a Kafka cluster or Kafka topic, they can create them as custom resources. These custom resources (CRs) will be seen by the Strimzi operator which will react to them and deploy a Kafka cluster or create a Kafka topic.
The challenging part about this is that creating the custom resource and the operator seeing it are two separate steps which are not done synchronously.
When the user creates or modifies the custom resource - for example using kubectl apply - the custom resource is accepted by the Kubernetes API server and stored in its Etcd database.
If this succeeds, the user gets back the message that the resource was successfully created or changed.
But at this point, the Operator still might not know about the resource.
Only after the resource is created or modified, the Kubernetes API server will notify the operator about it and the operator will decide what action to take.
Because this happens asynchronously, the operator has no chance to stop the resource from being created or changed.
The operator will see the resource only once it is created or changed and that is too late to do things likes like validation or applying sophisticated policies.
This applies not only to Strimzi, but to operators in general.
The Custom Resource Definitions can of course include an OpenAPIv3 schema which enables some basic validation of the custom resource. But that validates only the structure of the custom resource. It cannot do more advanced validations such as Does the Kafka cluster where I want to create the topic exist?. Our users are then wondering why did Strimzi let them create a topic for non-existent Kafka cluster. But there is not much an operator can do about that.
Admission Controllers
While operators cannot reject the custom resources as invalid, there are other Kuberneter components which can. They are called Admission Controllers. Admission controllers work as webhooks. You can register an application as admission controller for any kind of resource. And whenever such a resource is created or changed, the webhook will be called to validate it and either approve it and admit it into the cluster or reject it. If needed, the webhooks can even modify the resource, but that goes beyond the scope of this blog post.
Because the admission controllers are called before the request is done and the result is stored in the Etcd database, you can use them to do some advanced validation or apply some policies which need to be enforced. And OPA Gatekeeper gives you a framework to write easily your own admission controllers using the Rego policy language.
Open Policy Agent Gatekeeper
Gatekeeper is a validating admission controller for validating Kubernetes resources.
It is installed into your Kubernetes cluster as an admission controller.
And you can use two special custom resources to configure its behavior:
ConstraintTemplate CRs are used to create a policy template which can be parametrized.
When you create it, Gatekeeper will dynamically create a new CRD based on the template.
And this new CRD can be used to create a constraints - an instance of the policy with defined parameters which will be enforced.
If this sounds confusing, don’t worry, the examples coming next will make it much clearer.
But before we show some examples, we need to install Gatekeeper.
Detailed installation instructions can be found in the Gatekeeper README.md file.
To be able to install it you need to have cluster admin permission.
This is required in order to be able to add new admission controllers and let them validate all the different kind of resources.
Then you just apply the Gatekeeper installation files which will install it into gatekeeper-system namespace:
kubectl apply -f https://raw.githubusercontent.com/open-policy-agent/gatekeeper/master/deploy/gatekeeper.yaml
Once it is installed, you can start creating policies.
Validating labels
When creating KafkaTopic or KafkaUser resources, you need to use the strimzi.io/cluster label to tell Strimzi in which Kafka cluster should the topic or user be created.
Similarly, when using the KafkaConnector resource, you need to use the strimzi.io/cluster label to tell in which Kafka Connect cluster it should be deployed.
When you forget this label, the topic, user or connector will not be created.
So the first thing we can try is to use Gatekeeper to make sure this label is present on these custom resources.
This is also the example included in Gatekeeper, so we can use the same code.
Enforce the Strimzi cluster label
First we will need to create the policy template. That can be done with the following YAML:
apiVersion: templates.gatekeeper.sh/v1beta1
kind: ConstraintTemplate
metadata:
name: k8srequiredlabels
spec:
crd:
spec:
names:
kind: K8sRequiredLabels
listKind: K8sRequiredLabelsList
plural: k8srequiredlabels
singular: k8srequiredlabels
validation:
openAPIV3Schema:
properties:
labels:
type: array
items: string
targets:
- target: admission.k8s.gatekeeper.sh
rego: |
package k8srequiredlabels
violation[{"msg": msg, "details": {"missing_labels": missing}}] {
provided := {label | input.review.object.metadata.labels[label]}
required := {label | label := input.parameters.labels[_]}
missing := required - provided
count(missing) > 0
msg := sprintf("you must provide labels: %v", [missing])
}
Notice several parts of this custom resource:
- The
.spec.crdsection configures the CRD which will be dynamically created. You can configure the kind of the new CRD (the name of theConstraintTemplateresource has to be the same as thekindof the new CRD). And you can also specify the OpenAPI v3 schema which will be used for validation of the constraints - the policy instances. - The
.spec.targetssection lets you specify the Rego policy which will be used to validate the resources. It is using the rule namedviolation. The resource which needs be validated will be passed into the policy asinput.review.object. The parameters will be passed ininput.parameters. In our case, the parameter is list of labels which have to be present on the resource. The policy takes the labels from the reviewed resource and compares them against the required labels from the parameters and decides if the resource is valid.
Since the ConstraintTemplate is just a template, it does not have to know anything about the strimzi.io/cluster label.
We can specify that in the constraint resource.
You can create this ConstraintTemplate just by calling kubectl apply on it.
ConstraintTemplate is a global resource so you do not need to specify any namespace.
Once the template is created, you can do kubectl get crds and should see there a new custom resource definition named k8srequiredlabels.
With the template ready, we have to create the constraint:
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sRequiredLabels
metadata:
name: strimzi-cluster-label
spec:
match:
kinds:
- apiGroups: ["kafka.strimzi.io"]
kinds: ["KafkaTopic"]
- apiGroups: ["kafka.strimzi.io"]
kinds: ["KafkaUser"]
- apiGroups: ["kafka.strimzi.io"]
kinds: ["KafkaConnector"]
parameters:
labels: ["strimzi.io/cluster"]
The constraint has two parts:
- The
.spec.matchsection where we tell Gatekeeper which resources this constraint applies to. In our case, these areKafkaTopic,KafkaUserandKafkaConnector. - The
.spec.parameterssection specifies the parameters of the policy. In our case, we want the labelstrimzi.io/clusterto be present.
Again, the constraint can be created using kubectl apply.
Once it is created, we can see how it works.
Let’s try to create a KafkaTopic resource without the label:
cat <<EOF | kubectl apply -f -
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaTopic
metadata:
name: my-topic
spec:
partitions: 1
replicas: 1
config:
retention.ms: 7200000
segment.bytes: 1073741824
EOF
Error from server ([denied by strimzi-cluster-label] you must provide labels: {"strimzi.io/cluster"}): error when creating "STDIN": admission webhook "validation.gatekeeper.sh" denied the request: [denied by strimzi-cluster-label] you must provide labels: {"strimzi.io/cluster"}
And as you can see, the policy worked well.
The admission controller blocked the resource from being created and gave us a nice error you must provide labels: {"strimzi.io/cluster"}.
Make sure the cluster exists
Thanks to the policy from the previous example, we can now be sure that all our resources will have the right label.
But that is not enough for us.
We want to know that the Kafka or Kafka Connect cluster actually exists.
And for Kafka Connectors also ensure that the Kafka Connect cluster has enabled the use of connector resources.
The Gatekeeper example policy is too simple for that, but we can improve it.
When the KafkaTopic, KafkaUser and KafkaConnector resources are created, we can extract the value of the strimzi.io/cluster label and check if a Kafka or KafkaConnect resource with that name actually exists.
In order to be able check if Kafka or KafkaConnect resources exist, we need to tell Gatekeeper to read them from the Kubernetes API and make these data available in the policies.
To do that we have to create the Config custom resource in the gatekeeper-system namespace:
apiVersion: config.gatekeeper.sh/v1alpha1
kind: Config
metadata:
name: config
namespace: "gatekeeper-system"
spec:
sync:
syncOnly:
- group: "kafka.strimzi.io"
version: "v1beta1"
kind: "Kafka"
- group: "kafka.strimzi.io"
version: "v1beta1"
kind: "KafkaConnect"
The configuration above tells Gatekeeper to read the Kafka and KafkaConnect resources and make them available to our policies in the data.inventory variable.
Once we have them there, we can create a new policy template called StrimziLabels:
apiVersion: templates.gatekeeper.sh/v1beta1
kind: ConstraintTemplate
metadata:
name: strimzilabels
spec:
crd:
spec:
names:
kind: StrimziLabels
listKind: StrimziLabelsList
plural: StrimziLabels
singular: StrimziLabel
targets:
- target: admission.k8s.gatekeeper.sh
rego: |
package strimzilabels
cluster := input.review.object.metadata.labels["strimzi.io/cluster"]
ns := input.review.object.metadata.namespace
violation[{"msg": msg}] {
not valid_topic
not valid_user
not valid_connector
msg := "strimzi.io/cluster label must name one of the existing clusters"
}
valid_topic {
is_topic
data.inventory.namespace[ns]["kafka.strimzi.io/v1beta1"]["Kafka"][cluster]
}
valid_user {
is_user
data.inventory.namespace[ns]["kafka.strimzi.io/v1beta1"]["Kafka"][cluster]
}
valid_connector {
is_connector
data.inventory.namespace[ns]["kafka.strimzi.io/v1beta1"]["KafkaConnect"][cluster]
"true" == data.inventory.namespace[ns]["kafka.strimzi.io/v1beta1"]["KafkaConnect"][cluster]["metadata"]["annotations"]["strimzi.io/use-connector-resources"]
}
is_topic {
input.review.object.kind == "KafkaTopic"
}
is_user {
input.review.object.kind == "KafkaUser"
}
is_connector {
input.review.object.kind == "KafkaConnector"
}
This policy will decide whether the resource being reviewed is a topic, user or connector.
For topic and user, it will check whether the Kafka resource with the same name exists or not.
For connectors, it will check if the KafkaConnect resource exists and whether it is configured to use the connector resources.
Only when the cluster is valid, will the custom resource be created.
As you probably noticed, this policy template doesn’t take any paramaters. But we still need to create the constraint to tell Gatekeeper what kind of resources should be validated:
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: StrimziLabels
metadata:
name: strimzi-labels
spec:
match:
kinds:
- apiGroups: ["kafka.strimzi.io"]
kinds: ["KafkaTopic"]
- apiGroups: ["kafka.strimzi.io"]
kinds: ["KafkaUser"]
- apiGroups: ["kafka.strimzi.io"]
kinds: ["KafkaConnector"]
And then we can see whether the validation works by trying to create a KafkaUser with a cluster name which does not exist:
cat <<EOF | kubectl apply -f -
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaUser
metadata:
name: my-user
labels:
strimzi.io/cluster: i-do-not-exist
spec:
authentication:
type: tls
EOF
Error from server ([denied by strimzi-labels] strimzi.io/cluster label must contain one of the existing clusters): error when creating "STDIN": admission webhook "validation.gatekeeper.sh" denied the request: [denied by strimzi-labels] strimzi.io/cluster label must name one of the existing clusters
As you can see, the resource is rejected with the error strimzi.io/cluster label must name one of the existing clusters.
When we try it with a valid cluster name, it will be created:
cat <<EOF | kubectl apply -f -
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaUser
metadata:
name: my-user
labels:
strimzi.io/cluster: my-cluster
spec:
authentication:
type: tls
EOF
kafkauser.kafka.strimzi.io/my-user created
More advanced validations
You can of course use Gatekeeper for more than just validating labels.
For example we can use it to make sure any created topics have the right number of replicas and have properly configured the min.insync.replicas option.
We can use the following constraint template for it:
apiVersion: templates.gatekeeper.sh/v1beta1
kind: ConstraintTemplate
metadata:
name: strimzireplicas
spec:
crd:
spec:
names:
kind: StrimziReplicas
listKind: StrimziReplicasList
plural: StrimziReplicas
singular: StrimziReplicas
validation:
openAPIV3Schema:
properties:
min-replicas:
type: integer
min-insync-replicas:
type: integer
targets:
- target: admission.k8s.gatekeeper.sh
rego: |
package strimzireplicas
violation[{"msg": msg}] {
not has_enough
msg := sprintf("Topic must have at least %v replicas and %v min.insync.replicas", [input.parameters["min-replicas"], input.parameters["min-insync-replicas"]])
}
has_enough {
has_enough_replicas
has_enough_insync_replicas
}
has_enough_replicas {
input.review.object.spec["replicas"] >= input.parameters["min-replicas"]
}
has_enough_insync_replicas {
input.review.object.spec.config["min.insync.replicas"] >= input.parameters["min-insync-replicas"]
}
This policy has two parameters:
- The minimal allowed number of replicas
- The minimal allowed number of in-sync replicas
And we can use these to create different constraints for different environments.
For example, for a test environment, it might be OK to have only 2 replicas and min.insync.replicas set to 1.
While in production, you need to use at least 3 replicas and at least 2 min.insync.replicas:
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: StrimziReplicas
metadata:
name: strimzi-replicas
spec:
match:
kinds:
- apiGroups: ["kafka.strimzi.io"]
kinds: ["KafkaTopic"]
parameters:
min-replicas: 3
min-insync-replicas: 2
When someone now tries to create a topic not matching the criteria, it will not be allowed:
cat <<EOF | kubectl apply -f -
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaTopic
metadata:
name: my-topic
labels:
strimzi.io/cluster: my-cluster
spec:
partitions: 1
replicas: 1
config:
retention.ms: 7200000
segment.bytes: 1073741824
EOF
Error from server ([denied by strimzi-replicas] Topic must have at least 3 replicas and 2 min.insync.replicas): error when creating "STDIN": admission webhook "validation.gatekeeper.sh" denied the request: [denied by strimzi-replicas] Topic must have at least 3 replicas and 2 min.insync.replicas
Note: Gatekeeper only controls the topics created in Kubernetes using the KafkaTopic custom resource.
It does not validate topics created directly inside Kafka using Kafka APIs.
In the same way, you can write many policies to enforce different aspects of your Kafka based infrastructure. Some ideas as examples:
* Minimal number of Zookeeper, Kafka or Kafka Connect nodes
- Storage type
- Authentication type or authorization rules for users
Conclusion
Gatekeeper gives you a very simple way to write powerful admission controllers. The examples in this blog post covered just some of its aspects. To understand all the options which Gatekeeper gives you, you should check their GitHub repository. You do not have to write anything in Golang or build your own images. All you need to know is the Rego policy language. It is just up to you to come up with the right policies which you want to be enforced in your cluster. And of course you can use it with any kind of resources - not just with Strimzi.
Share this:
![]()
![]()
![]()
![]()
![]()