One of the promises of Kubernetes is zero downtime upgrades. If your service is highly available, meaning it has more than one replica running on different nodes or availability zones, then it should be possible to do a rolling update without any service disruption.
An event that may affect your service availability is the Kubernetes upgrade, where all cluster nodes are drained one by one, until they are all running on a new version. Node draining is also used for maintenance. When a node is drained, it is cordoned first to prevent scheduling of new Pods and then the old Pods are evicted. This process works well with stateless applications, but can cause problems with stateful and replicated applications like Kafka.
The node draining problem
A common use case is a producer application sending records to a topic with replicas=3 and min.insync.replica=2,
which is required to configure for resiliency against a single node failure. We want such a producer to be able to
continue uninterrupted during a Kubernetes upgrade, where each node is drained right after the previous one has been
fully evacuated.
The problem is that node draining does not account for the actual internal state of the Kafka cluster, as it works using
the Readiness state, which indicates if the container is ready to start accepting traffic, but does not necessarily
correspond to the replicas being in sync. For that reason, there is no guarantee that the next node draining will start
after the previous evacuated Kafka Pod is fully synced, so you might end up with under-replicated partitions for some
time, causing the producer’s rate to drop to zero. This can affect the entire data pipeline, so also consumers will
likely be affected.
Leveraging admission webhooks
The Drain Cleaner is a lightweight application that leverages admission
webhooks to help move Kafka Pods from Kubernetes nodes which are being drained. This is useful if you want the
Cluster Operator to move Pods instead of Kubernetes itself. The advantage of this approach is that the Cluster Operator
makes sure that no partition becomes under-replicated during node draining, by waiting for the synchronization of topics
with multiple replicas and the value of min.insync.replicas less than replicas.
As you can see from the following image, when a new Kubernetes request arrives at the API server endpoint, a ValidatingAdmissionWebhook controller is invoked after the schema validation phase and it calls every registered webhook, to implement some logic. This can be useful to enforce custom policies or simply be notified about specific events.
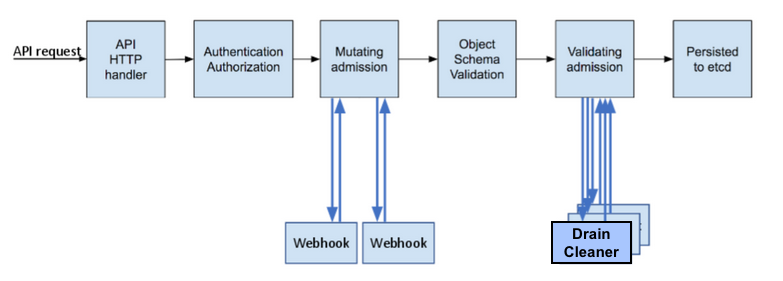
Some admission controllers are actually built-in (i.e. LimitRange, NamespaceLifecycle). ValidatingAdmissionWebhooks are safe, as they cannot change the incoming request and they always see the final version that would be persisted to etcd.
Note: ValidatingAdmissionWebhooks may be disabled in your Kubernetes cluster for security reasons, so this is the first thing to verify.
In our case, we want the Drain Cleaner to be notified of all Pod eviction requests. The application will then filter out
all Pods that are not part of our StatefulSets. In order to let the combined work of Drain Cleaner and the Cluster
Operator handle node draining, we also need to block automatic Pod draining by setting maxUnavailable: 0 in Kafka and
ZooKeeper PodDisruptionBudgets, as shown below.
This additional configuration does not require a rolling update.
spec:
kafka:
template:
podDisruptionBudget:
maxUnavailable: 0
zookeeper:
template:
podDisruptionBudget:
maxUnavailable: 0
Validating webhook configuration
To register the Drain Cleaner’s endpoint at the Kubernetes control-plane level, you need to create a
ValidatingWebhookConfiguration resource. This is a simple REST endpoint, exposed under the /drainer URL path. When an
incoming API request matches one of the specified operations, groups, versions, resources, and scope for any of defined
rules, the request is sent to that endpoint.
rules:
- apiGroups: [""]
apiVersions: ["v1"]
operations: ["CREATE"]
resources: ["Pods/eviction"]
scope: "Namespaced"
clientConfig:
service:
namespace: "strimzi-drain-cleaner"
name: "strimzi-drain-cleaner"
path: /drainer
port: 443
caBundle: <CA_BUNDLE>
Here I used a placeholder for the PEM-encoded CA bundle, which is required to validate the webhook’s certificate. You can use a self-signed CA certificate, but the Drain Cleaner’s end-entity certificate, signed by that CA, must have a common name (CN) that matches the application’s service name.
Let’s see what that CA bundle looks like for a self-signed certificate deployed on a test namespace. CertManager or OpenShift can help with this, by automatically generating and injecting the certificates.
# Self-signed CA certificate
Certificate:
Signature Algorithm: sha256WithRSAEncryption
Issuer: C=IT, ST=Rome, O=Test, CN=drain-cleaner-ca.example.com
Subject: C=IT, ST=Rome, O=Test, CN=drain-cleaner-ca.example.com
X509v3 extensions:
X509v3 Basic Constraints: critical
CA:TRUE, pathlen:0
# Drain Cleaner's end-entity certificate
Certificate:
Signature Algorithm: sha1WithRSAEncryption
Issuer: C=IT, ST=Rome, O=Test, CN=drain-cleaner-ca.example.com
Subject: C=IT, ST=Rome, O=Test, CN=drain-cleaner-webhook.example.com
X509v3 extensions:
X509v3 Basic Constraints: critical
CA:FALSE
X509v3 Key Usage:
Digital Signature, Key Encipherment
X509v3 Extended Key Usage:
TLS Web Server Authentication, TLS Web Client Authentication
X509v3 Subject Alternative Name:
DNS:strimzi-drain-cleaner,
DNS:strimzi-drain-cleaner.test,
DNS:strimzi-drain-cleaner.test.svc,
DNS:strimzi-drain-cleaner.test.svc.cluster.local
Let the magic happen
The Drain Cleaner must be deployed by a user with permissions to create all required resources, such as ServiceAccount, ClusterRole and ClusterRoleBinding. A single Drain Cleaner instance handles all Kafka instances hosted on that Kubernetes cluster.
With the ValidatingWebhookConfiguration in place, the Drain Cleaner is notified as soon as something tries to evict Kafka
or ZooKeeper Pods and it annotates them with strimzi.io/manual-rolling-update. This tells the Cluster Operator that
they need to be restarted in the next reconciliation phase, making sure the Kafka cluster is always available. Restart
annotation is not created if already present (idempotency) or the eviction request is running in dry-run mode. Pod
restart will be delayed if that would cause one or more partitions to be under-replicated.
Note: The rolling update annotation is supported since the Strimzi 0.21.0 release.
Once you have a Kafka cluster and the Drain Cleaner up and running, you can test it by draining the node hosting the Kafka Pod, Zookeeper Pod, or both Pods with the following command:
kubectl drain <NODE_NAME> --delete-emptydir-data --ignore-daemonsets --timeout=6000s --force
Looking at the Drain Cleaner’s logs, you will see the eviction events being notified for all Pods on that node. Only Kafka and Zookeeper Pods are actually annotated for restart. All the rest are filtered out.
2021-08-03 08:07:00,218 INFO [io.str.ValidatingWebhook] (executor-thread-17) Received eviction webhook for Pod my-cluster-zookeeper-2 in namespace test
2021-08-03 08:07:00,218 INFO [io.str.ValidatingWebhook] (executor-thread-17) Pod my-cluster-zookeeper-2 in namespace test will be annotated for restart
2021-08-03 08:07:00,301 INFO [io.str.ValidatingWebhook] (executor-thread-17) Pod my-cluster-zookeeper-2 in namespace test found and annotated for restart
2021-08-03 08:07:01,508 INFO [io.str.ValidatingWebhook] (executor-thread-17) Received eviction webhook for Pod my-cluster-kafka-0 in namespace test
2021-08-03 08:07:01,508 INFO [io.str.ValidatingWebhook] (executor-thread-17) Pod my-cluster-kafka-0 in namespace test will be annotated for restart
2021-08-03 08:07:01,540 INFO [io.str.ValidatingWebhook] (executor-thread-17) Pod my-cluster-kafka-0 in namespace test found and annotated for restart
Given that the node being evacuated is cordoned (unschedulable), Pods restart will actually move them away from that node.
2021-08-03 08:07:13 INFO PodOperator:68 - Reconciliation #13(timer) Kafka(test/my-cluster): Rolling Pod my-cluster-zookeeper-2
2021-08-03 08:08:06 INFO PodOperator:68 - Reconciliation #13(timer) Kafka(test/my-cluster): Rolling Pod my-cluster-kafka-0
2021-08-03 08:08:53 INFO AbstractOperator:500 - Reconciliation #13(timer) Kafka(test/my-cluster): reconciled
In case you were just trying it out and not doing a real node upgrade, don’t forget to uncordon it:
kubectl uncordon <NODE_NAME>
Conclusion
The Drain Cleaner is a lightweight application that runs as a single service on your Kubernetes cluster. With a small overhead, you can guarantee high availability for all your Kafka clusters. This is especially important when you have service level agreements (SLA) in place that you want to fulfill.
Any feedback and contribution are welcome, as always :)
Share this:
![]()
![]()
![]()
![]()
![]()