In this article we would like to focus on the most common challenges to migrate Apache Kafka clusters between different OpenShift platforms, and how to overcome them by using Apache MirrorMaker and Strimzi Operators.
NOTE: The article and the examples describe and implement the process for OpenShift, the enterprise version of Kubernetes from Red Hat. However the content applies perfectly for a Kubernetes platform.
Nowadays, many modern architectures are deployed on top of container management platforms. OpenShift is one of the most standard of those platforms. These modern architectures are based in many patterns (Event-Driven Architectures, Capture Data Change, Reactive Systems) using data streaming platforms as backbone to glue everything in a fashion way. Apache Kafka is the most extended component to implement that backbone.
OpenShift and Apache Kafka are evolving so fast, and organizations are evolving their Cloud platforms where they face some of the following migration use cases:
- Upgrading the Cloud platform to latest versions
- Migrating on-prem cloud platforms to public or hybrid cloud platforms
Migration Scenario
The most typical migration scenario includes an existing OpenShift platform where there is already an Apache Kafka cluster running successfully and a set of producer and consumer applications. The Apache Kafka cluster then must be moved to a new target OpenShift platform (this decision could be driven by different topics that are out of scope of this article), but the migration must cover the following requirements:
- No data loss between clusters, so both must be synchronized.
- Transition period to migrate applications step-by-step and avoid a Big Bang migration.
- Optionally upgrading the Apache Kafka cluster to newest versions.
The first two requirements are the most important and common in any migration project, because it is very complex to coordinate all the actors at the same time. The migration process must be robust to avoid any data loss but at the same time should be smooth and easy to allow migrations of the workloads when they are ready to go. However the latest requirement is aligned with a modernization that is usually done before or after the migration. Introducing new changes during the migration could add complexity to the process and impact troubleshooting when something was wrong. We will cover the upgrade process only to describe some capabilities of the migration but it is something that you should consider when you migrate your Apache Kafka clusters.
This solution requires an Active-Passive topology of the Apache Kafka clusters. The active Apache Kafka cluster is the current online deployed in the source OpenShift platform, and the passive Apache Kafka cluster is the new one deployed in the target OpenShift platform. However, at the end of the migration the passive Apache Kafka cluster became active as soon as the latest application was connected to it. At that moment we could stop and remove the original one.
Migration Process Overview
This migration process follow the Consumer First approach (it means basically start moving the consumers before the producers) and it could be summarized as:
- Exposing externally the source Apache Kafka cluster to external clients of OpenShift, if it is not already exposed. More info here.
- Define an user to migrate data from the source Apache Kafka cluster. This
user must have the right grants to consume data from topics and create
topics. It could be a good recommendation to define as a super-user. More
info here.
- Get or extract certificates and migration user credentials, they are needed later.
- Deploy new Apache Kafka cluster in target OpenShift platform. This
new cluster should have the same topology as the original
one (# brokers, resources, …) to have an 1-1 scenario.
- Optionally we could deploy a higher version of Kafka. Applications migrated must be aligned to the Kafka API declared, otherwise Apache Kafka brokers will have to perform down-conversion continuously (not desirable as it will impact in the performance)
- Deploy MirrorMaker in the target OpenShift platform.
- Verify topics and data are created in the target Apache Kafka cluster.
- Move consumers from the source Apache Kafka cluster to the target Apache Kafka cluster. (Remember Consumer First approach)
- Verify data consumption is working successfully.
- Move producers from the source Apache Kafka cluster to the target Apache Kafka cluster.
- Verify data production is working successfully.
The migration process could add many different required or optional tasks aligned with the details or specific activities, but in general the process will be very similar to this one.
Now, let’s see how we could execute it.
MirrorMaker, the migration tool
The Apache Kafka ecosystem provides a tool to replicate data between different Apache Kafka clusters: Apache MirrorMaker.
NOTE: There are other approaches to migrate Apache Kafka workloads based on other tools and processes, but all of them are out of the scope. We think that the Apache Kafka ecosystem provides the right tools to help in this scenario.
This tool helps to define data flows that cross the boundaries of an Apache Kafka cluster to extend to others, allowing to cover different uses cases and scenarios such as:
- Geo-replication
- Disaster recovery
- Feeding edge cluster into a central, aggregate cluster
- Cloud migration or hybrid cloud deployments (we are here)
- Legal, technical, or compliance requirements
MirrorMaker provides currently two different implementations:
- MirrorMaker 1: The first implementation with basic functionality to consume and produce data from the source to the target. It is very limited and it could help you to replicate only data payloads.
- MirrorMaker 2: Improved implementation based on KafkaConnect framework allowing replication of more things (topics and its configuration, consumer groups offsets, ACLs), and more features (detects new topics/partitions, metrics, fault-tolerant and HA).
This article is based on MirrorMaker2 because it will include a set of features needed to cover our requirements. The most important features are:
- Topic topology replication, as we need to have the same structure of the topic and partitions in the target Kafka cluster.
- Consumer group offset synchronization, as we need to consume the data from the target Kafka cluster at the same point the consumers stopped in the source Kafka cluster. This feature tries to avoid consuming duplicated messages in the target cluster.
- Dynamic detection of configuration changes in source Kafka cluster and replicate in target Kafka cluster. Every change must be replicated in the target Kafka cluster.
- Replication ACL rules that manage access to source brokers and topics apply to target topics. If we are not using the User Operator of Strimzi, in that case we should recreate the KafkaUsers in the target cluster. More info here.
The synchronization processes are managed by a set of properties to set up intervals and checkpoints. It is important to review and check these properties and the applications movements to avoid or reduce the duplication process of some data.
MirrorMaker2 could rename the topics in the target Kafka cluster (remote topics) with some patterns and conventions. During a migration process this kind of changes are not a good idea, it is a best practice to maintain a 1-1 relationship between the source and kafka cluster.
MirrorMaker2 Connectors
MirrorMaker2 deploys a KafkaConnect cluster with a set of different Kafka Connectors to execute the migration and synchronization between clusters.
- MirrorSourceConnector is responsible for topics, data replication based on a replication policy, and other synchronization tasks such as ACL rules, renaming topics, …
- MirrorCheckpointConnector is responsible for track offset for consumer groups and synchronizing into the target Kafka cluster.
- MirrorHeartbeatConnector is responsible for checking the connectivity between clusters using a set of heartbeats and checks.
The action combinated of all of them, using a set of internal topics, executes this complex process of migrating and synchronizing both Kafka clusters.
Strimzi Operators make migrations happier
Operating an Apache Kafka system with all these components in an OpenShift environment sounds like a huge and complex activity, however the reality is that is very easy thanks to the powerful Kubernetes Operators provided by the great community of Strimzi.
Strimzi provides a full list of operators to help streamline the installation, configuration, and maintenance operations for OpenShift platforms. Thanks to these operators we could manage this complex migration scenario with a small few resources to achieve our goals.
More information and details about these operators, review the Quick Start Guide.
Migration Deployment Topology
We could draw our migration process and topology as:
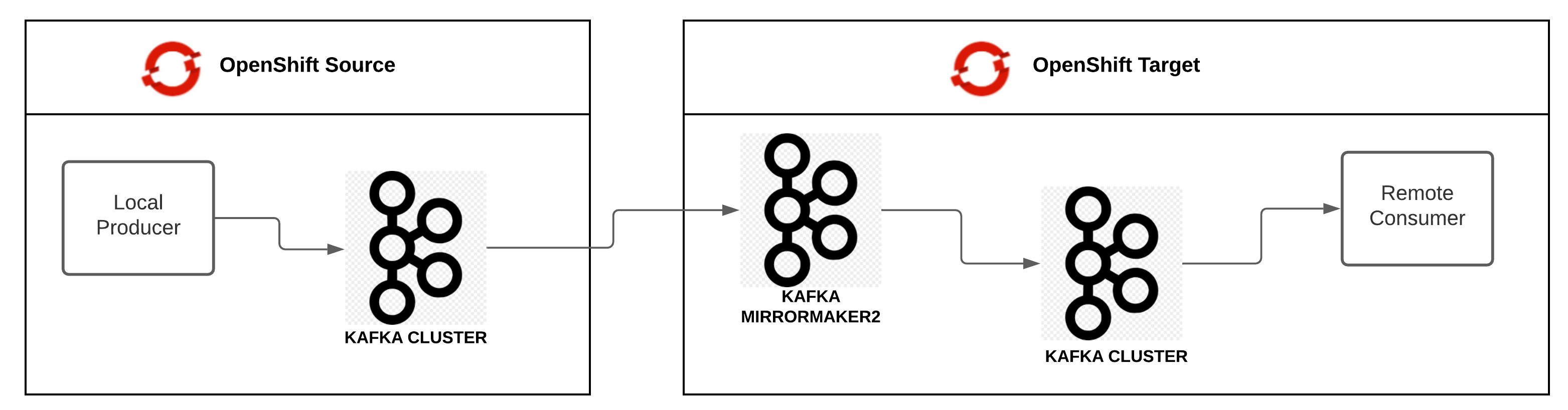
Easy, right?
Show me the code
Before to move to the code, and the technical details, keep in mind the following points:
- The Apache Kafka ecosystem provides great tools to migrate data, but they are not enough.
- It is important to have a holistic plan to coordinate all the actors: producers, consumers, brokers, security, …
- The plan must include a rollback path, and backups before to start (the things could go wrong …)
- Follow the plan, check and test every step. Coordination is key to success.
- Don’t include changes in your topology, if you could do it … adding new things during a migration could be a nightmare for debugging or testing.
Sounds good, right? But, Does it work? Could you show me the code?
Of course, we developed this use case in a GitHub repository, with a set of instructions, commands and manifests for your testing and verification. The repo demonstrates how the different components could work together and resolve the main requirements of the use case. You could find it here:
https://github.com/rmarting/strimzi-migration-demo
We are open to get feedback, comments and improvements of this use case.
Share this:
![]()
![]()
![]()
![]()
![]()