The basic architecture of an Apache Kafka cluster with Apache ZooKeeper is pretty straightforward. You have a ZooKeeper cluster with one or more ZooKeeper nodes - typically using an odd number of nodes, most often 3. Then you have the Kafka cluster with one or more Apache Kafka brokers that is bootstrapped using the ZooKeeper cluster. And that’s it. There aren’t really any other options But when we remove ZooKeeper to introduce the KRaft (Kafka Raft metadata) mode, the architectural landscape changes significantly. In this blog post, we will look at the various KRaft architectures and how Strimzi can support them using the Kafka node pools.
This post is part of a series about Kafka node pools. Other posts include:
- Part 1 - Introduction
- Part 2 - Node ID Management
- Part 3 - Storage & Scheduling
- Part 4 - Supporting KRaft (this post)
- Part 5 - What’s next?
KRaft architectures
In the KRaft mode, the Kafka cluster runs without an Apache ZooKeeper cluster as a dependency. The Kafka nodes in the KRaft mode have controller and/or broker roles. The nodes with the controller role are responsible for maintaining the Kafka metadata, handling leader elections, and helping to bootstrap the Kafka cluster. They assume the responsibilities previously handled by the ZooKeeper nodes. The nodes with the broker role have the same responsibilities as the Kafka brokers in the ZooKeeper-based Kafka cluster. They receive the messages from the producers, store them, and pass them to the consumers. One node can also have both roles - a controller and a broker - at the same time. This offers a number of configuration options for your KRaft-based Kafka cluster.
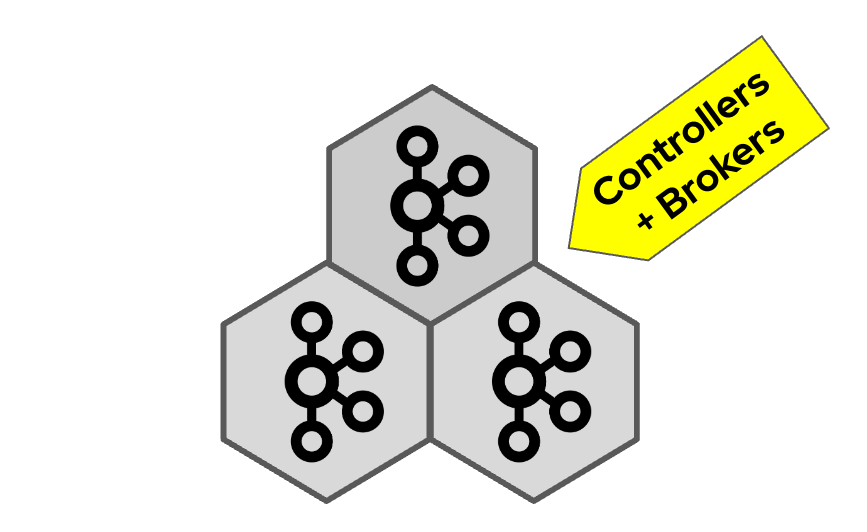
You might start with a small Kafka cluster consisting only of combined nodes that all have controller and broker roles. Typically, it would have three nodes. But if needed you can also run a whole Kafka cluster in a single node. Such a cluster is suitable for example for development and testing. It might be also useful in other resource-constraint environments. For example when running Kafka at the edge.
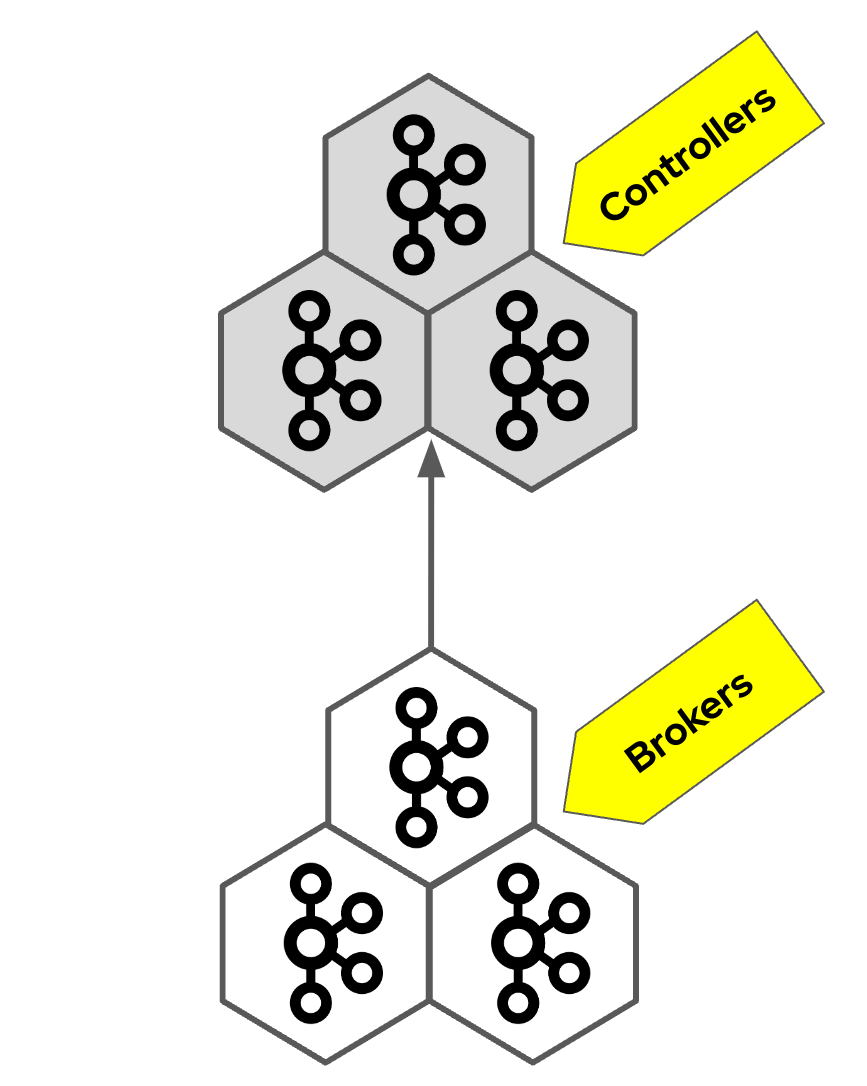
For a production cluster, you would normally use dedicated controller nodes and dedicated broker nodes. You would typically maintain three controller nodes for availability, and add as many broker nodes as you need. This is also the architecture to which you would migrate from a ZooKeeper-based cluster.
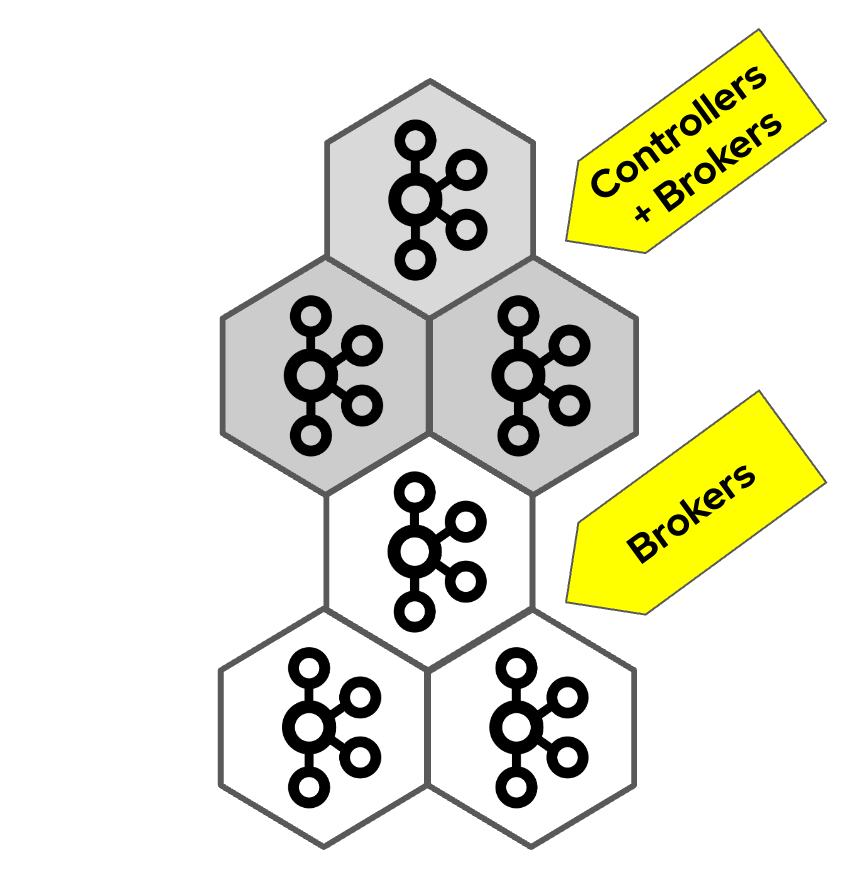
And somewhere in between is an architecture where some nodes have both controller and broker roles and some have only the broker role. It is also an intermediate step when migrating from the combined nodes to the dedicated controller nodes or the other way around.
Our users employ Strimzi for various scenarios, spanning from small development and test clusters to large-scale multi-node production clusters.
So we want to support all of these architectures.
We also want to make it possible to transition between them.
But how do we model the different architectures as Kubernetes resources?
The answer is - using the KafkaNodePool resources.
Configuring node pools to support KRaft architectures
KRaft and its various architectures were one of the main motivations when designing node pools.
Which is why KRaft and its roles are included in the node pool configuration options.
Each KafkaNodePool resource has a mandatory property called roles in its spec configuration.
We mentioned this in the blog post introducing node pools.
The roles property contains a list of roles that the nodes within the node pool adopt.
In ZooKeeper-based clusters, you should only configure the broker role.
In KRaft-based clusters, you can configure controller and/or broker roles.
And Strimzi will configure the Kafka nodes belonging to the given pool accordingly.
For clusters using Kraft mode for cluster management, there always has to be at least one node pool that has the controller role and at least one node pool with the broker role.
It can be the same node pool for both roles or it can be in a different node pool.
But both roles have to be present to have a working Kafka cluster.
And you can use the roles to configure the various architectures.
So for example, to create the KRaft cluster with combined nodes, you can create one KafkaNodePool and configure it to use both roles - controller as well as broker.
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaNodePool
metadata:
name: combined
labels:
strimzi.io/cluster: my-cluster
spec:
replicas: 3
roles:
- controller
- broker
# ...
If you want to have a Kafka cluster with dedicated controller and broker nodes, you can create two KafkaNodePool resources.
One with the controller role.
And another with the broker role.
Of course, if you want, you can use more node pools.
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaNodePool
metadata:
name: controller
labels:
strimzi.io/cluster: my-cluster
spec:
replicas: 3
roles:
- controller
# ...
---
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaNodePool
metadata:
name: broker
labels:
strimzi.io/cluster: my-cluster
spec:
replicas: 6
roles:
- broker
# ...
Finally, if you want to use some combined nodes and some broker-only nodes, you can configure the Kafka cluster that way as well.
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaNodePool
metadata:
name: combined
labels:
strimzi.io/cluster: my-cluster
spec:
replicas: 3
roles:
- controller
- broker
# ...
---
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaNodePool
metadata:
name: broker
labels:
strimzi.io/cluster: my-cluster
spec:
replicas: 6
roles:
- broker
# ...
You can find full examples of the custom resources on our GitHub.
If you want to try it, do not forget that you have to enable the UseKRaft feature gate as well.
Current limitations
While the work on the KRaft support is progressing, it is still not completely ready. At the time of writing (Strimzi 0.36 / Apache Kafka 3.5.1), there are still some important features missing. Right now, you can use Strimzi to deploy a Kafka cluster with all of the architectures mentioned in this post. But Strimzi currently does not support rolling updates of the nodes that have the controller role only. It also does not support the migration from ZooKeeper to KRaft or upgrades of KRaft clusters. A full list of the current Strimzi KRaft limitations can be found in our documentation. There are also still many limitations to KRaft in Apache Kafka itself. For example missing support for JBOD storage or Admin API support for managing the controller nodes.
So, feel free to give the KRaft-based node pool setups a try, but do keep in mind the existing limitations.
Conclusion
KRaft might not be production-ready yet, but it is the future of cluster management in Apache Kafka. As such, Strimzi is dedicated to supporting the various KRaft architectures, with Kafka node pools playing a very important role in this commitment.
In Part 5 we will look to the future and outline the plans we have for node pools.
Share this:
![]()
![]()
![]()
![]()
![]()