The Topic Operator enhances Strimzi’s capabilities by allowing Kafka administrators to manage Apache Kafka topics using Kubernetes custom resources (CRs). You can declare the desired topic configuration, and the Topic Operator will reconcile it with the actual Kafka cluster state.
The first generation of the Topic Operator is based on Kafka Streams library, and uses ZooKeeper to gather topic metadata. We call it the Bidirectional Topic Operator (BTO), as it allows the reconciliation of changes originating from both Kubernetes and Kafka.
With time, this implementation presented a number of issues:
- It requires ZooKeeper for cluster management, so it is not compatible with using Strimzi in KRaft mode.
- It doesn’t scale well as it operates on one topic at a time, and it has to update a persistent store containing topic metadata.
- Due to its internal complexity, there are corner cases which are still not well understood (invalid state store, topic recreation after delete)
To address these issues, we introduced the Unidirectional Topic Operator (UTO). This new implementation maintains full backwards compatibility while streamlining the reconciliation process. The UTO reconciles topic changes in only one direction: from Kubernetes to Kafka.
Introduction
Apache Kafka has emerged as a powerful and versatile platform for handling real-time data streams. It’s used by organizations worldwide to ingest, process, and analyze data in a scalable and fault-tolerant manner.
However, managing Kafka topics efficiently has often been a challenging task for administrators. These challenges might arise when creating topics, adjusting configurations, and ensuring consistency across the cluster, all while handling evolving requirements. Traditionally, these tasks have been performed manually, often leading to errors, inconsistencies, and operational overhead.
This is where the Strimzi Topic Operator comes into play.
It introduces a declarative approach to Kafka topic management, focusing on the “what” rather than the “how”.
In a declarative model, administrators define the desired state of topics, specifying high-level characteristics and requirements using the KafkaTopic custom resource, while leaving the intricate details to the operator itself.
This shift in perspective not only simplifies the management process but also ensures that the desired configuration is maintained consistently across the Kafka cluster.
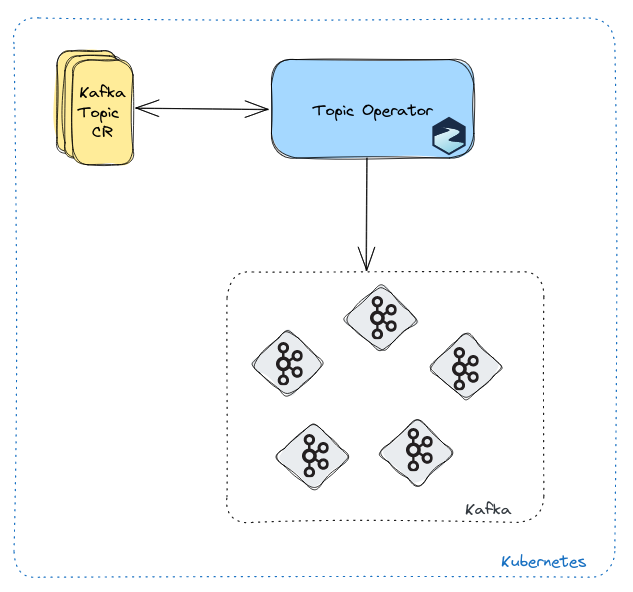
You use KafkaTopic custom resources to declare how you want your Kafka topics to be configured and managed.
Here’s how a Kafka topic is declared using this approach:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: my-topic
labels:
strimzi.io/cluster: my-cluster
spec:
partitions: 3
replicas: 2
config:
retention.ms: 86400000
The requirement here is that a single KafkaTopic custom resource is used to manage a single topic in a single Kafka cluster.
From the example above, you can see that the resource has a label strimzi.io/cluster with the name of the target Kafka cluster.
The operator communicates with this cluster and ensures that the specified topic is created or updated according to the desired configuration.
The Topic Operator can be deployed either as a standalone component or with your Kafka cluster by enabling the operator in the Kafka custom resource.
The BTO reconciles changes coming from both Kubernetes and Kafka using a three-way merge logic. In order to do this, it has to keep a persistent topic store, which is the source-of-truth used to determine the necessary changes for synchronization.
The UTO is fully backwards compatible and improves on scalability, but also provides support for Kafka clusters running in KRaft mode.
As the UTO only reconciles topic events from Kubernetes to Kafka, KafkaTopic custom resources become the single source-of-truth.
If the Kafka-side configuration is changed out-of-band (e.g. by using the Admin client, or Kafka shell scripts), those changes will eventually be reverted.
Topic maintenance
The UTO can detect cases where multiple KafkaTopic resources are attempting to manage a Kafka topic using the same .spec.topicName.
Only the oldest resource is reconciled, while the other resource will fail with a ResourceConflict error.
This operator still does not support decreasing .spec.partitions and changing .spec.replicas.
While the former is not supported by Kafka itself, support for the latter could be added in the future.
In addition to being able to pause reconciliations, the operator also provides a way to unmanage a Kafka topic using annotations.
If the KafkaTopic is paused and we delete it, then it will be also deleted in Kafka.
If the KafkaTopic is unmanaged and we delete it, then only the resource will be garbage collected by Kubernetes, but the topic will still exist in Kafka.
In terms of requirements, the UTO assumes the following access rights:
- Describe all topics
- Describe all topics configs
- Create topics
- Create partitions
- Delete topics
- List partition reassignments
- Describe broker configs
Scalability
The BTO is limited in terms of scalability, as it only operates on one topic at a time, and it has to update a persistent store containing topic metadata. By contrast, the UTO does not store topic metadata and it aims to be scalable in terms of the number of topics that it can operate on.
When running Kafka operations, the UTO makes use of the request batching supported by the Kafka Admin client to get higher throughput for metadata operations.
All KafkaTopic related events (custom resource creations, updates, deletes) are queued when received, and then processed in batches by a number of controller threads (currently, only a single thread is supported).
If more than one event related to a single topic resource is found in the batch building, only the first is reconciled, while the others are put back in the queue to be processed with the next batch.
You can tune the batching mechanism by setting STRIMZI_MAX_QUEUE_SIZE (default: 1024), STRIMZI_MAX_BATCH_SIZE (default: 100), and MAX_BATCH_LINGER_MS (default: 100).
If you exceed the configured max queue size, the UTO will print an error and then shutdown (Kubernetes will take care of restarting the pod).
In that case, you can simply raise the max queues size to avoid periodic operator restarts.
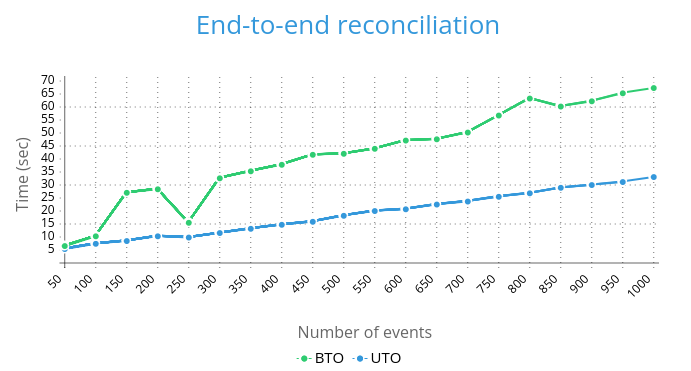
Environment: Strimzi 0.38.0, 3-nodes cluster running on Minikube.
The above line graph shows that the UTO is faster and scales much better than the BTO on a bulk ingestion/batch use case.
The only configuration changes we made were: .spec.entityOperator.topicOperator.reconciliationIntervalSeconds: 10 (both), and MAX_BATCH_LINGER_MS=10 (UTO only).
In a separate test on the same environment, the UTO was able to process 10k topic events in less than 10 minutes.
Race condition
There exists a race condition when the operator and an external application attempt to change a topic configuration concurrently in Kafka.
For instance, a GitOps pipeline might create a topic using a KafkaTopic resource, while an application tries to create the same topic during its startup.
If the external application prevails, the topic is created using the default Kafka cluster configuration. In this case, the UTO tries to reconcile to the desired state, and only fails when an incompatible change is detected (i.e. partition decrease).
The recommendation when using the UTO is to configure the Kafka cluster with auto.create.topics.enable: false in order to reduce the likelihood of hitting this problem.
Unfortunately, disabling auto topic creation doesn’t help with applications that use the Kafka Admin client to create topics directly, such as with Kafka Streams applications.
In this case, the application should be written to wait for a topic to exist, or use an init container to do the same.
Finalizers
Finalizers are used by default to ensure that topic deletion events are not missed when the UTO is not running.
If this happens, you end up with the KafkaTopic resource deleted in Kubernetes by garbage collection, and a Kafka topic still present in Kafka.
It is recommended to delete KafkaTopic resources when the operator is running in order to trigger the required cleanups.
A common pitfall is that an attempt to delete a namespace or Custom Resource Definition becomes stuck in a “terminating” state.
This happens when you try to delete everything at once and the operator does not have time to delete all the KafkaTopic resources.
In such a scenario, you can remove the finalizers from all KafkaTopic resources simultaneously using the following command:
$ kubectl get kt -o yaml | yq 'del(.items[].metadata.finalizers[])' | kubectl apply -f -
kafkatopic.kafka.strimzi.io/topic-1 configured
kafkatopic.kafka.strimzi.io/topic-2 configured
kafkatopic.kafka.strimzi.io/topic-3 configured
In development and test environments, you can disable the use of finalizers with the following configuration:
# from Kafka custom resource
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
entityOperator:
userOperator: {}
topicOperator: {}
template:
topicOperatorContainer:
env:
- name: STRIMZI_USE_FINALIZERS
value: "false"
# from standalone Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: strimzi-topic-operator
spec:
template:
spec:
containers:
- name: STRIMZI_USE_FINALIZERS
value: "false"
Upgrading from BTO to UTO
The UTO has been available as alpha feature since Strimzi 0.36.0, so you need to enable a feature gate in order to use it. Strimzi 0.38.0 enhances the UTO with by adding Prometheus metrics and a pause reconciliation feature.
The plan is to move it to beta in Strimzi 0.39.0, where it will be enabled by default. Preliminary tests show that UTO consumes less CPU and memory than the BTO.
$ kubectl set env deploy strimzi-cluster-operator STRIMZI_FEATURE_GATES="+UnidirectionalTopicOperator"
deployment.apps/strimzi-cluster-operator updated
If you are using the Operator Lifecycle Manager (OLM), then you simply need to patch the Subscription:
$ kubectl -n <namespace> patch sub <subscription-name> --type merge -p '
spec:
config:
env:
- name: STRIMZI_FEATURE_GATES
value: "+UnidirectionalTopicOperator"'
subscription.operators.coreos.com/<subscription-name> patched
At this point the Cluster Operator will restart, and then it will deploy the Entity Operator with the UTO included. You can check the logs to confirm that the UTO is running fine:
$ kubectl logs $(kubectl get po -l strimzi.io/name=my-cluster-entity-operator -o name) -c topic-operator | "Returning from main"
2023-10-23 08:32:25,60913 INFO [main] TopicOperatorMain:148 - Returning from main()
Verify the UTO installation by creating a new test topic and seeing if it is reconciled:
echo -e "apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: uto-test
labels:
strimzi.io/cluster: my-cluster
spec:
partitions: 1
replicas: 1
config:
min.insync.replicas: 1" | kubectl create -f -
kafkatopic.kafka.strimzi.io/uto-test created
$ kubectl get kt uto-test -o jsonpath='{.status}'
{"conditions":[{"lastTransitionTime":"2023-10-23T08:41:53.501883404Z","status":"True","type":"Ready"}],"observedGeneration":1,"topicName":"uto-test"}
$ kubectl exec my-cluster-kafka-0 -- bin/kafka-topics.sh --bootstrap-server my-cluster-kafka-bootstrap:9092 --describe --topic uto-test
Topic: uto-test TopicId: gWrR6uDrSNSSfu_ubGndCg PartitionCount: 1 ReplicationFactor: 1 Configs: min.insync.replicas=1,message.format.version=3.0-IV1
Topic: uto-test Partition: 0 Leader: 1 Replicas: 1 Isr: 1
$ kubectl delete kt uto-test
kafkatopic.kafka.strimzi.io "uto-test" deleted
Optionally, you can delete the internal topics created by the BTO, which are not used anymore:
$ kubectl delete $(kubectl get kt -o name | grep strimzi-store-topic)
kafkatopic.kafka.strimzi.io "strimzi-store-topic---effb8e3e057afce1ecf67c3f5d8e4e3ff177fc55" deleted
$ kubectl delete $(kubectl get kt -o name | grep strimzi-topic-operator)
kafkatopic.kafka.strimzi.io "strimzi-topic-operator-kstreams-topic-store-changelog---b75e702040b99be8a9263134de3507fc0cc4017b" deleted
Finally, you can also choose to unmanage the Kafka internal topics, without deleting them inside the Kafka cluster.
Here I’m just showing the __consumer_offsets topic, but the procedure is the same for the other internal topics:
$ kubectl annotate $(kubectl get kt -o name | grep consumer-offsets) strimzi.io/managed="false"
kafkatopic.kafka.strimzi.io/consumer-offsets---84e7a678d08f4bd226872e5cdd4eb527fadc1c6a annotate
$ kubectl delete $(kubectl get kt -o name | grep consumer-offsets)
kafkatopic.kafka.strimzi.io "consumer-offsets---84e7a678d08f4bd226872e5cdd4eb527fadc1c6a" deleted
$ kubectl exec my-cluster-kafka-0 -- bin/kafka-topics.sh --bootstrap-server my-cluster-kafka-bootstrap:9092 --describe --topic __consumer_offsets
Topic: __consumer_offsets TopicId: AZQjCm_qSYyjSxRYNPsU5A PartitionCount: 50 ReplicationFactor: 3 Configs: compression.type=producer,min.insync.replicas=2,cleanup.policy=compact,segment.bytes=104857600,message.format.version=3.0-IV1
Topic: __consumer_offsets Partition: 0 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: __consumer_offsets Partition: 1 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: __consumer_offsets Partition: 2 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
...
Downgrading from UTO to BTO
Downgrading to BTO is as easy as disabling the feature gate.
Note that it may take some time to rebuild the internal state store if your Kafka cluster hosts many topics. Make sure to have adequate CPU and memory resources for that.
$ kubectl set env deploy strimzi-cluster-operator STRIMZI_FEATURE_GATES="-UnidirectionalTopicOperator"
deployment.apps/strimzi-cluster-operator env updated
At this point the Cluster Operator restarts, and then will deploy the new Entity Operator containing the BTO. You can check the logs to confirm that the BTO is running fine:
$ kubectl logs $(kubectl get po -l strimzi.io/name=my-cluster-entity-operator -o name) -c topic-operator | grep "Session deployed"
2023-10-23 08:59:51,95138 INFO [vert.x-eventloop-thread-1] Main:70 - Session deployed
After that, you should see all your topics, including the auto-created internal topics:
$ kubectl get kt
NAME CLUSTER PARTITIONS REPLICATION FACTOR READY
consumer-offsets---84e7a678d08f4bd226872e5cdd4eb527fadc1c6a my-cluster 50 3 True
my-topic my-cluster 3 3 True
strimzi-store-topic---effb8e3e057afce1ecf67c3f5d8e4e3ff177fc55 my-cluster 1 3 True
strimzi-topic-operator-kstreams-topic-store-changelog---b75e702040b99be8a9263134de3507fc0cc4017b my-cluster 1 3 True
Finally, can get rid of all the finalizers and create a test topic as shown before.
Conclusion
The Unidirectional Topic Operator improves scalability while keeping full backwards compatibility. Now is the perfect time to give it a try and log any issue or improvement before it moves to beta. We would love to hear from you.
Share this:
![]()
![]()
![]()
![]()
![]()