The Apache Kafka project has been using Apache ZooKeeper to store metadata since its inception. ZooKeeper stores essential data for running a Kafka cluster, such as registered brokers, the current controller, and topic configuration. Using a dedicated and centralized system for maintaining cluster metadata and offload leader election was the right approach at that time, because ZooKeeper was battle tested and it is purpose built for providing distributed coordination. But taking care of an additional component alongside your Kafka cluster is not that simple. Furthermore, ZooKeeper has become a bottleneck that limits the amount of partitions that a single broker can handle. For these and other reasons, the Kafka community opened the “famous” KIP-500 in late 2019 and started to work toward ZooKeeper removal. Through this blog post we are going to describe the main differences between using ZooKeeper and KRaft to store the cluster metadata and how the migration from the former to the latter works.
What is “wrong” with ZooKeeper?
Kafka has relied on ZooKeeper for managing its metadata for various tasks, including:
- Cluster membership: Each broker, joining the Kafka cluster, registers itself with an ephemeral znode on ZooKeeper.
- Controller election: When a broker starts, it tries to take the “controller” role by creating the ephemeral
/controllerznode on ZooKeeper. If that znode already exists, it indicates which broker is the current controller. - Topics configuration: All topic configuration properties, such as the number of partitions and the current broker assignments for the replicas, are stored in ZooKeeper.
- Access Control Lists (ACLs): When a client connects to the cluster, it can be authenticated and authorized to read or write on several topics based on the ACLs stored in ZooKeeper by the built-in Authorizer.
- Quotas: Brokers can limit resources used by clients in terms of network bandwidth and CPU utilization via quotas stored in ZooKeeper by the built-in Quotas provider.
Assuming to have a ZooKeeper-based Kafka cluster my-cluster deployed with Strimzi on Kubernetes in the kafka namespace, you can use the zookeeper-shell tool on one of the ZooKeeper pods and see all the znodes.
kubectl exec -it my-cluster-zookeeper-0 -n kafka -- bin/zookeeper-shell.sh localhost:12181
The brokers within the cluster are listed under the /brokers znode, where information about their endpoints is provided for each of them.
ls /brokers/ids
[0, 1, 2]
get /brokers/ids/0
{"features":{},"listener_security_protocol_map":{"CONTROLPLANE-9090":"SSL","REPLICATION-9091":"SSL","PLAIN-9092":"PLAINTEXT","TLS-9093":"SSL"},"endpoints":["CONTROLPLANE-9090://my-cluster-kafka-0.my-cluster-kafka-brokers.kafka.svc:9090","REPLICATION-9091://my-cluster-kafka-0.my-cluster-kafka-brokers.kafka.svc:9091","PLAIN-9092://my-cluster-kafka-0.my-cluster-kafka-brokers.kafka.svc:9092","TLS-9093://my-cluster-kafka-0.my-cluster-kafka-brokers.kafka.svc:9093"],"jmx_port":-1,"port":9092,"host":"my-cluster-kafka-0.my-cluster-kafka-brokers.kafka.svc","version":5,"timestamp":"1710691902130"}
As mentioned, the controller election happens when the first broker creates the ephemeral /controller node storing the broker ID.
get /controller
{"version":2,"brokerid":0,"timestamp":"1710691902625","kraftControllerEpoch":-1}
Finally, the /config/topics znode lists all the topics in the cluster with the corresponding configuration.
get /config/topics/my-topic
{"version":1,"config":{"retention.ms":"100000"}} // all the other configuration parameters are omitted because using default values
ZooKeeper data is replicated across a number of nodes which form an ensemble. ZooKeeper uses the ZooKeeper Atomic Broadcast (ZAB) protocol to replicate data to all nodes in the ZooKeeper ensemble. This protocol keeps all nodes in sync and ensures reliability on messages delivery.
But having ZooKeeper means operating a totally different distributed system to Kafka, which also needs to be deployed, managed and troubleshot. ZooKeeper also represents a bottleneck for scalability and puts a limit on the number of topics and the corresponding partitions supported within a Kafka cluster. It has a performance impact when, for example, there is a controller failover and the newly elected controller has to fetch metadata from ZooKeeper, including all the topics information. Also, any metadata update needs to be propagated to the other brokers. The problem is that the metadata changes propagations, by using RPCs, grow with the number of partitions involved so it takes longer and the system gets slower.
Welcome to KRaft!
In order to overcome the limitations related to the ZooKeeper usage, the Kafka community came up with the idea of using Kafka itself to store metadata and use an event-driven pattern to make updates across the nodes. The work started with KIP-500 in late 2019 with the introduction of a built-in consensus protocol based on Raft. That was named Kafka Raft … KRaft for friends!
KRaft is an event-based implementation of the Raft protocol with a quorum controller maintaining an event log and a single-partition topic named __cluster_metadata to store the metadata.
Unlike the other topics, this is special because records are written to disk synchronously, which is required by the Raft algorithm for correctness.
It works in a leader-follower mode, where the leader writes events into the metadata topic which is then replicated to the follower controllers by using the KRaft replication algorithm.
The leader of that single-partition topic is actually the controller node of the Kafka cluster.
The metadata changes propagation has the benefit of being event-driven via replication instead of using RPCs.
The metadata management is part of Kafka with the usage of a new quorum controller service which uses an event-sources storage model.
The KRaft protocol is used to ensure that metadata are fully replicated across the quorum.
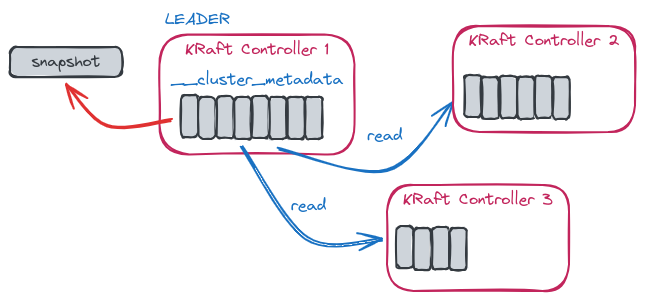
By using the kafka-dump-log.sh tool together with the --cluster-metadata-decoder option, you are able to dump the content of the __cluster_metadata segments and see how several events are generated in relation to metadata changes.
Assuming to have a KRaft-based Kafka cluster my-cluster deployed with Strimzi on Kubernetes in the kafka namespace, you can run the following command on the KRaft active controller node (that is my-cluster-controller-0).
kubectl exec -it my-cluster-controller-0 -n kafka -- bin/kafka-dump-log.sh --cluster-metadata-decoder --files /var/lib/kafka/data-0/kafka-log0/__cluster_metadata-0/00000000000000000000.log
Dumping /var/lib/kafka/data-0/kafka-log0/__cluster_metadata-0/00000000000000000000.log
For example, you could see a REGISTER_BROKER_RECORD event related to cluster membership, when a new broker joins the cluster.
| offset: 53 CreateTime: 1710772983743 keySize: -1 valueSize: 308 sequence: -1 headerKeys: [] payload: {"type":"REGISTER_BROKER_RECORD","version":3,"data":{"brokerId":3,"isMigratingZkBroker":false,"incarnationId":"5TICkSDlQOGOHY-sn-TtDw","brokerEpoch":53,"endPoints":[{"name":"REPLICATION-9091","host":"my-cluster-broker-3.my-cluster-kafka-brokers.kafka.svc","port":9091,"securityProtocol":1},{"name":"PLAIN-9092","host":"my-cluster-broker-3.my-cluster-kafka-brokers.kafka.svc","port":9092,"securityProtocol":0},{"name":"TLS-9093","host":"my-cluster-broker-3.my-cluster-kafka-brokers.kafka.svc","port":9093,"securityProtocol":1}],"features":[{"name":"metadata.version","minSupportedVersion":1,"maxSupportedVersion":19}],"rack":null,"fenced":true,"inControlledShutdown":false,"logDirs":["uHY7hO6-42Q7O4k0zLMmtg"]}}
When a topic is created, a TOPIC_RECORD event followed by a CONFIG_RECORD event together with multiple PARTITION_RECORD events are generated.
These records describe topic creation, the corresponding custom configuration and how the partitions are distributed across the brokers.
| offset: 3004 CreateTime: 1710774451597 keySize: -1 valueSize: 29 sequence: -1 headerKeys: [] payload: {"type":"TOPIC_RECORD","version":0,"data":{"name":"my-topic","topicId":"xOxBrcYuSRWgtFuZIBiXIA"}}
| offset: 3005 CreateTime: 1710774451597 keySize: -1 valueSize: 34 sequence: -1 headerKeys: [] payload: {"type":"CONFIG_RECORD","version":0,"data":{"resourceType":2,"resourceName":"my-topic","name":"retention.ms","value":"100000"}}
| offset: 3006 CreateTime: 1710774451597 keySize: -1 valueSize: 113 sequence: -1 headerKeys: [] payload: {"type":"PARTITION_RECORD","version":1,"data":{"partitionId":0,"topicId":"xOxBrcYuSRWgtFuZIBiXIA","replicas":[5,3,4],"isr":[5,3,4],"removingReplicas":[],"addingReplicas":[],"leader":5,"leaderEpoch":0,"partitionEpoch":0,"directories":["SaZDxfHKu3NMZ7OnFP7YnA","uHY7hO6-42Q7O4k0zLMmtg","p2UpbSD99eygD2ZToiSMzg"]}}
| offset: 3007 CreateTime: 1710774451597 keySize: -1 valueSize: 113 sequence: -1 headerKeys: [] payload: {"type":"PARTITION_RECORD","version":1,"data":{"partitionId":1,"topicId":"xOxBrcYuSRWgtFuZIBiXIA","replicas":[3,4,5],"isr":[3,4,5],"removingReplicas":[],"addingReplicas":[],"leader":3,"leaderEpoch":0,"partitionEpoch":0,"directories":["uHY7hO6-42Q7O4k0zLMmtg","p2UpbSD99eygD2ZToiSMzg","SaZDxfHKu3NMZ7OnFP7YnA"]}}
| offset: 3008 CreateTime: 1710774451597 keySize: -1 valueSize: 113 sequence: -1 headerKeys: [] payload: {"type":"PARTITION_RECORD","version":1,"data":{"partitionId":2,"topicId":"xOxBrcYuSRWgtFuZIBiXIA","replicas":[4,5,3],"isr":[4,5,3],"removingReplicas":[],"addingReplicas":[],"leader":4,"leaderEpoch":0,"partitionEpoch":0,"directories":["p2UpbSD99eygD2ZToiSMzg","SaZDxfHKu3NMZ7OnFP7YnA","uHY7hO6-42Q7O4k0zLMmtg"]}}
All the possible metadata changes are encoded as specific event records in the metadata log topic in Apache Kafka. They are all described using metadata JSON files, which are then used to automatically build the corresponding Java classes.
Removing an external system like ZooKeeper simplifies the overall architecture and removes the burden of operating an additional component. The scalability is also improved by reducing the load on the metadata store by using snapshots to avoid unbounded growth (like compacted topic). When there is a leadership change in the controller quorum, the new leader already has all the committed metadata records so the recovery is pretty fast.
Another interesting aspect of using the KRaft mode is about the role that a single node can have within the cluster itself.
By using the new process.roles configuration parameter, a Kafka node can act as a broker, a controller or perform both roles in “combined” mode
A broker node is responsible for handing requests, including reads and writes on topics, from Kafka clients.
A controller node takes part in the controller quorum and replicates the metadata log. At any time, one of the controller nodes is the quorum leader and the others are followers that can take over in case the current leader resigns, for example, if it’s restarted or fails.
Effectively, broker and controller are two different services running on the node within the JVM.
When in “combined” mode, a node performs both roles with the corresponding responsibilities.
Using the “combined” mode allows reduction in the number of nodes within the cluster compared to a ZooKeeper configuration.
It is not recommended for critical use cases as this offers less isolation in case of failures.
This mode is useful for small use cases, for example it allows setting up a Kafka development environment by starting a single node.
How to migrate from ZooKeeper to KRaft
While KRaft has been production ready for a few releases already, with features being added in each release, most existing Kafka clusters are still ZooKeeper-based. However, users are interested in migrating to KRaft mode in order to overcome all the ZooKeeper limitations we have talked about.
Furthermore, ZooKeeper is already considered as deprecated and, with the Kafka project expecting to remove ZooKeeper support in an upcoming 4.0 release, expected in 2024, it is now time to consider migrating clusters from ZooKeeper to KRaft.
To migrate a cluster without any downtime, there is a manual procedure to follow that consists of several phases. The following content aims to provide an overview of how the migration procedure is supposed to work, rather than offering an exhaustive description. For more details, please refer to the official ZooKeeper to KRaft Migration documentation.
Deploying the KRaft controller quorum
Before starting the migration, we have Kafka brokers running in ZooKeeper-mode and connected to the ZooKeeper ensemble used to store metadata.
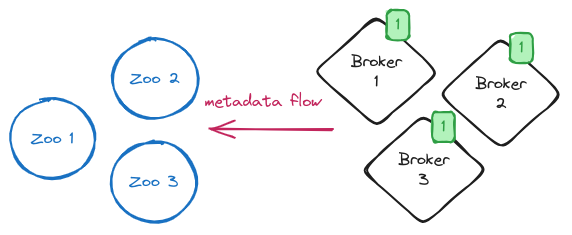
NOTE: The green square boxed number highlights the “generation” of the nodes that will be rolled several times during the process.
The first step is to deploy the KRaft controller quorum which will be in charge of maintaining the metadata in KRaft mode.
In general, the number of KRaft controller nodes will be the same as the number of the ZooKeeper nodes currently running.
It is also important to highlight that the migration process doesn’t support migrating to nodes running in “combined” mode.
The nodes forming the KRaft controller quorum are all configured with the connection to ZooKeeper together with the additional zookeeper.metadata.migration.enable=true flag which states the intention to run the migration.
When the KRaft controllers start, they form a quorum, elect the leader and move in a state where they are waiting for the brokers to register.
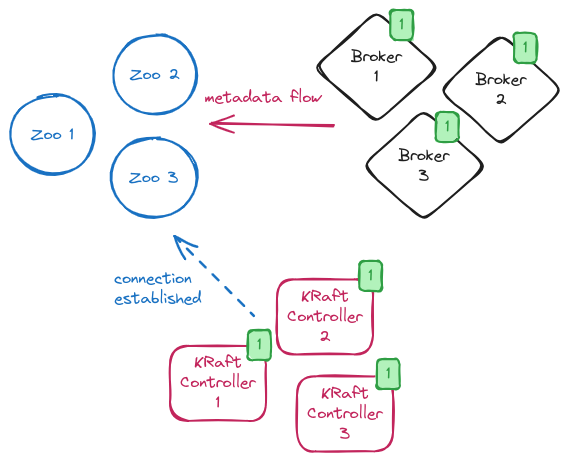
Enabling brokers to run the migration
The next step is to move the brokers to migration mode.
In order to do so, the brokers’ configuration needs to be updated by adding connection details for all nodes of the KRaft controller quorum and enabling the migration with the zookeeper.metadata.migration.enable=true flag.
After the update, the brokers need to be rolled one by one to make such configuration changes effective.
On restart, the brokers register to the KRaft controller quorum and the migration begins.
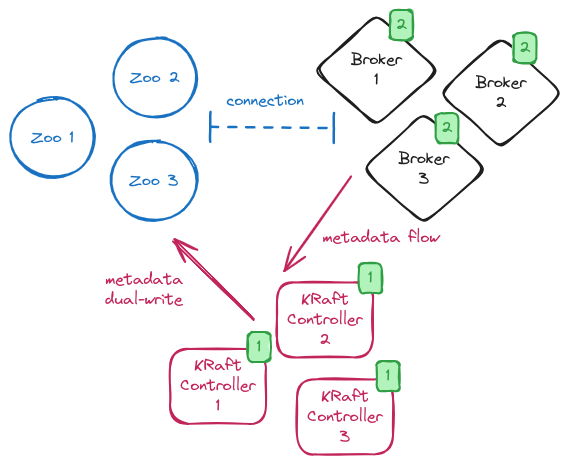
During the brokers rolling, the system is in a so-called “hybrid phase” with some brokers in ZooKeeper mode but there is a KRaft controller quorum running.
The KRaft controller leader copies all metadata from ZooKeeper to the __cluster_metadata topic.
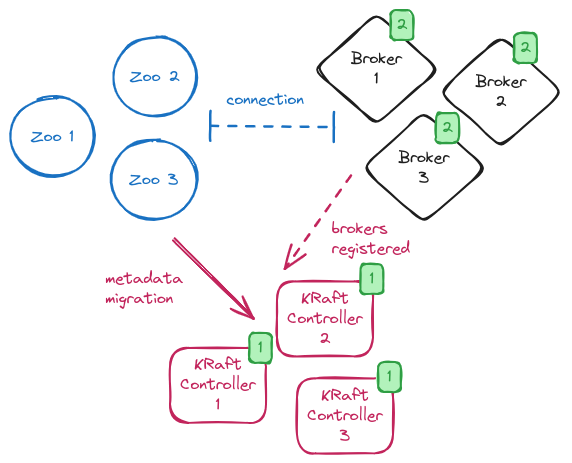
While the migration is running, you can verify its status by looking at the log on the KRaft controller leader or by checking the kafka.controller:type=KafkaController,name=ZkMigrationState metric.
When the migration is completed, and the metric value changes to MIGRATION, the brokers are still running in ZooKeeper mode.
The KRaft controllers are in charge of handling any requests related to metadata changes within the cluster but they keep sending RPCs to the brokers for metadata updates.
Metadata updates are still copied to ZooKeeper and the cluster is working in a so called “dual-write” mode.
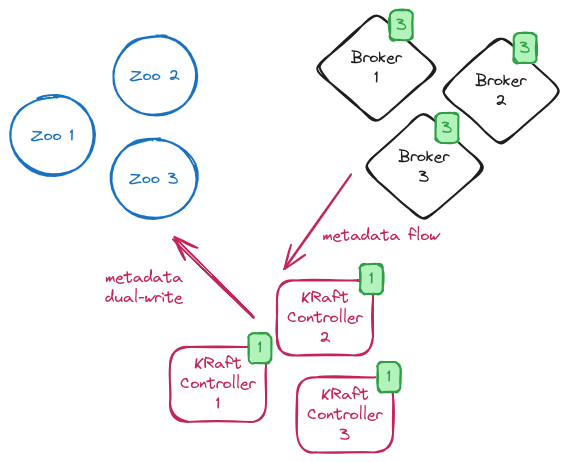
Restarting the brokers in KRaft mode
The next step is to restart the brokers in KRaft mode and not use ZooKeeper anymore. In order to do so, the brokers configuration is updated by removing the connection to ZooKeeper and disabling the migration flag. All the brokers are rolled again and, on restart, they are now in full KRaft mode without any connection or usage of ZooKeeper. The system is now in a so-called “dual-write phase” with all brokers in KRaft mode but controllers still copying metadata changes to ZooKeeper. This is the last chance to rollback and keep using ZooKeeper to store metadata.
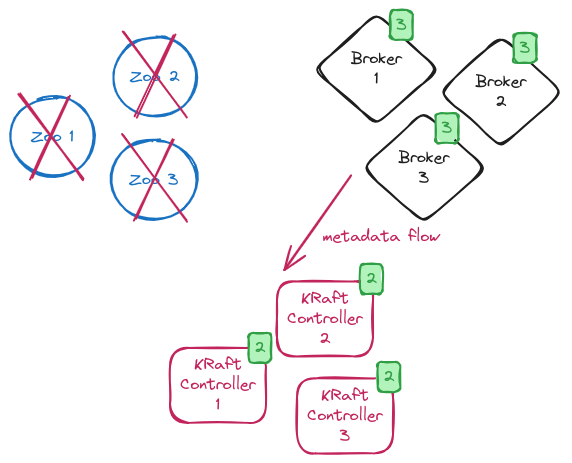
Migration finalization
The final step is to reconfigure the KRaft controllers without the connection to ZooKeeper and disable the migration flag. When all the KRaft controllers are rolled, the cluster is working in full KRaft mode and the ZooKeeper ensemble is not used anymore. From now on, you should deprovision the ZooKeeper nodes from your environment.
Rollback support
During the migration process, it is also possible to execute a rollback procedure to revert the cluster to use the ZooKeeper ensemble again. The rollback is allowed until the KRaft controllers are still connected to ZooKeeper because they are working in “dual-write” mode by effectively copying metadata to ZooKeeper. When the migration is finalized and the KRaft controllers are not connected to ZooKeeper, the rollback is not possible anymore.
Conclusion
The Apache Kafka community has deprecated the usage of ZooKeeper to store the cluster metadata and it will be completely removed in the version 4.0 release. This means that users should soon consider moving to using KRaft-based clusters. Of course, there are a lot of ZooKeeper-based clusters already running in production out there which need to be migrated. The migration process is not trivial and needs a lot of manual intervention, with configuration updates and nodes to be rolled. But if you are running your cluster on Kubernetes, you can read this blog post about how the Strimzi operator provides a semi-automated approach making the migration a lot easier!
Share this:
![]()
![]()
![]()
![]()
![]()