The Queues for Kafka feature, introduced in KIP-932, is available as an early access feature in Apache Kafka version 4.0 and supported in Strimzi from version 0.46. In this blog, I’m going to introduce this feature and show how you can try it out with your Strimzi managed cluster.
This feature is only supported with Kafka clusters running in KRaft mode, since ZooKeeper was removed in the Apache Kafka 4.0 release. It is also based on the new consumer rebalance protocol introduced by KIP-848 that enhances stability, scalability and performance.
Traditional message queues based on Competing Consumers pattern and Kafka topics are significantly different in terms of design and use cases. A queue allows a group of consumers to read and process records in parallel to distribute the workload. It does not provide a strong ordering guarantee as records in a queue are consumed and processed independently. However, it allows an exactly-once guarantee as each record is only read once and is deleted from the queue. The state of each record is usually tracked and acknowledged after successful processing to avoid prematurely removing records off the queue or to handle unprocessable records. This also means that records in a queue are not replayable, therefore a queue can only be consumed by one consumer group.
On the other hand, a Kafka topic can be consumed by multiple consumer groups as it is an immutable log and reading of records does not result in removal. However, workload distribution cannot be achieved with consumers alone. A topic has to be partitioned in order to spread the workload across a consumer group. Kafka topics also provide an ordering mechanism by using record keys.
The Queues for Kafka feature combines the strengths of traditional message queues and Kafka topics. It lets you use a Kafka topic similar to a traditional queue, increasing message processing parallelism beyond the number of partitions. Queue-like semantics are provided through a new consumer group type called a share group, which enables traditional queue use cases while giving fine-grained control over message acknowledgment and retries.
The key difference between a share group and a regular consumer group is how partitions get assigned to consumer members. With regular consumer groups, each partition is exclusively assigned to a single member of the consumer group. Users can typically have as many consumer members as the number of partitions to maximize the parallelism in message processing. Moreover, due to this, users tend to over-partition their topics in order to cope with peak loads that may only happen sometimes. However, share groups balance partitions between all members of a share group, allowing multiple consumer members to fetch from the same partition. So users can have more consumers than the number of partitions, further increasing the parallelism and they do not need to over-partition their topics, but can just scale up and down their consumers to cope with the peak loads. When share group members consume from the same partition, each record on that partition is still only read by one consumer in the group.
The share group does not support exactly-once semantics and does not provide ordering guarantee as multiple consumers can fetch records from the same partition. However, these features may potentially be added in the future. The dead letter queue based on Dead Letter Channel pattern is currently not supported either but there is already an open KIP for it.
Now that we’ve covered the concepts, let’s see how share groups differ from regular consumer groups in practice using a Strimzi-managed Kafka cluster.
Comparing share and consumer groups with Strimzi
I have set up a single node cluster on my machine using Strimzi’s Quickstart. Since the Queues for Kafka feature is still in early access, as of Apache Kafka 4.0.0, I explicitly enabled the feature by setting the following:
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
# ...
spec:
kafka:
config:
# ...
group.coordinator.rebalance.protocols: classic,consumer,share
unstable.api.versions.enable: true
share.coordinator.state.topic.replication.factor: 1
# ...
version: 4.0.0
metadataVersion: 4.0-IV3
# ...
The group.coordinator.rebalance.protocols configuration is for the list of enabled rebalance protocols. By default, it is set to classic,consumer therefore I set this to include share.
The unstable.api.versions.enable configuration is technically an internal configuration that should not be used in production. It enables early access features for development and testing purposes.
Since I’m running a single node cluster, I also set share.coordinator.state.topic.replication.factor to 1. I’ll cover more on this topic later.
Then I created a topic called kafka-queue-topic with 2 partitions:
$ cat << EOF | kubectl create -n kafka -f -
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaTopic
metadata:
name: kafka-queue-topic
labels:
strimzi.io/cluster: "my-cluster"
spec:
partitions: 2
replicas: 1
EOF
Using the Kafka command line tools, I produced some records on the topic and consumed them using both consumer and share groups to show how they behave differently.
In this example, I started with 3 share consumers, all joined the same share group called, share-group and then 3 regular consumers, also all joined the same consumer group called, consumer-group.
I ran the following command in different terminal windows with different pod names, e.g. kafka-share-consumer-0, kafka-share-consumer-1, kafka-share-consumer-2:
$ kubectl -n kafka run kafka-share-consumer-0 -ti --image=quay.io/strimzi/kafka:0.47.0-kafka-4.0.0 --rm=true --restart=Never \
-- bin/kafka-console-share-consumer.sh \
--bootstrap-server my-cluster-kafka-bootstrap:9092 \
--topic kafka-queue-topic \
--group share-group \
--property print.offset=true \
--property print.partition=true
I did the same for the regular consumers with pod names, kafka-consumer-0, kafka-consumer-1 and kafka-consumer-3:
$ kubectl -n kafka run kafka-consumer-0 -ti --image=quay.io/strimzi/kafka:0.47.0-kafka-4.0.0 --rm=true --restart=Never \
-- bin/kafka-console-consumer.sh \
--bootstrap-server my-cluster-kafka-bootstrap:9092 \
--topic kafka-queue-topic \
--group consumer-group \
--consumer-property group.protocol=consumer \
--property print.offset=true \
--property print.partition=true
Note that I used the new consumer group protocol, not the classic which is the default group protocol when the configuration is not set. The share groups are based on the new consumer group protocol, therefore does not need this configuration.
I checked the pods started using the following command:
$ kubectl get po -n kafka
NAME READY STATUS RESTARTS AGE
kafka-consumer-0 1/1 Running 0 2m24s
kafka-consumer-1 1/1 Running 0 2m28s
kafka-consumer-2 1/1 Running 0 2m34s
kafka-share-consumer-0 1/1 Running 0 2m9s
kafka-share-consumer-1 1/1 Running 0 2m
kafka-share-consumer-2 1/1 Running 0 110s
my-cluster-dual-role-0 1/1 Running 0 7m44s
my-cluster-entity-operator-78d5b9dfd9-5ktxt 2/2 Running 0 10m
strimzi-cluster-operator-5dd46b9985-dp2wt 1/1 Running 0 10m
And then produced random records to the topic using the kafka-producer-perf-test.sh tool.
$ kubectl -n kafka run kafka-producer -ti --image=quay.io/strimzi/kafka:0.47.0-kafka-4.0.0 --rm=true --restart=Never \
-- bin/kafka-producer-perf-test.sh \
--producer-props bootstrap.servers=my-cluster-kafka-bootstrap:9092 \
--topic kafka-queue-topic \
--num-records 10000 \
--record-size 10 \
--throughput -1
The following screenshot of the terminal windows shows that all 3 share consumers received the records from both partitions:
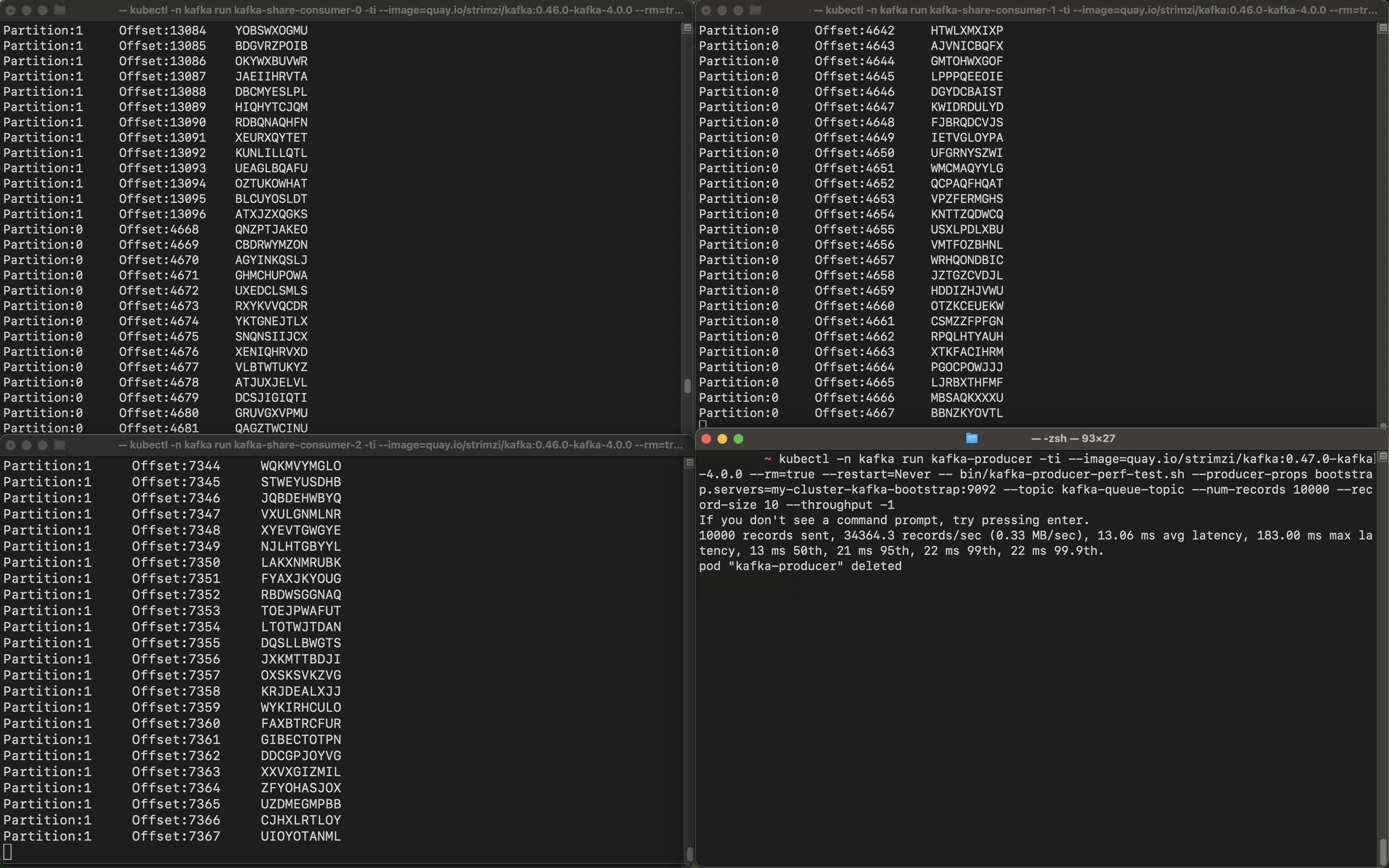 This showed how dynamic partition assignment of the share group is. While kafka-share-consumer-1 consumed from partition 1 and kafka-share-consumer-2 consumed from partition 0, kafka-share-consumer-0 consumed from both partitions.
This showed how dynamic partition assignment of the share group is. While kafka-share-consumer-1 consumed from partition 1 and kafka-share-consumer-2 consumed from partition 0, kafka-share-consumer-0 consumed from both partitions.
The new command line tool, kafka-share-groups.sh can be used to describe share groups and their members. The following shows the topic partitions that the share group is subscribed to and their start offsets:
$ kubectl -n kafka run kafka-tool -ti --image=quay.io/strimzi/kafka:0.47.0-kafka-4.0.0 --rm=true --restart=Never \
-- bin/kafka-share-groups.sh \
--bootstrap-server my-cluster-kafka-bootstrap:9092 \
--describe \
--group share-group
GROUP TOPIC PARTITION START-OFFSET
share-group kafka-queue-topic 0 7903
share-group kafka-queue-topic 1 13097
With the --members flag, I checked the share group members and their assignments. As you can see, all the share consumers are assigned to the same partitions and therefore fetch records in parallel:
$ kubectl -n kafka run kafka-tool -ti --image=quay.io/strimzi/kafka:0.47.0-kafka-4.0.0 --rm=true --restart=Never \
-- bin/kafka-share-groups.sh \
--bootstrap-server my-cluster-kafka-bootstrap:9092 \
--describe \
--group share-group \
--members
GROUP CONSUMER-ID HOST CLIENT-ID ASSIGNMENT
share-group bSURQb3NTfSDGXQmgRrEeQ /10.244.0.131 console-share-consumer kafka-queue-topic:0,kafka-queue-topic:1
share-group HY1kEgMFShaumg8xSEc9sw /10.244.0.133 console-share-consumer kafka-queue-topic:0,kafka-queue-topic:1
share-group cvg5pnSlQ-qzlxocNkTplg /10.244.0.132 console-share-consumer kafka-queue-topic:0,kafka-queue-topic:1
Now let’s look at the regular consumer group.
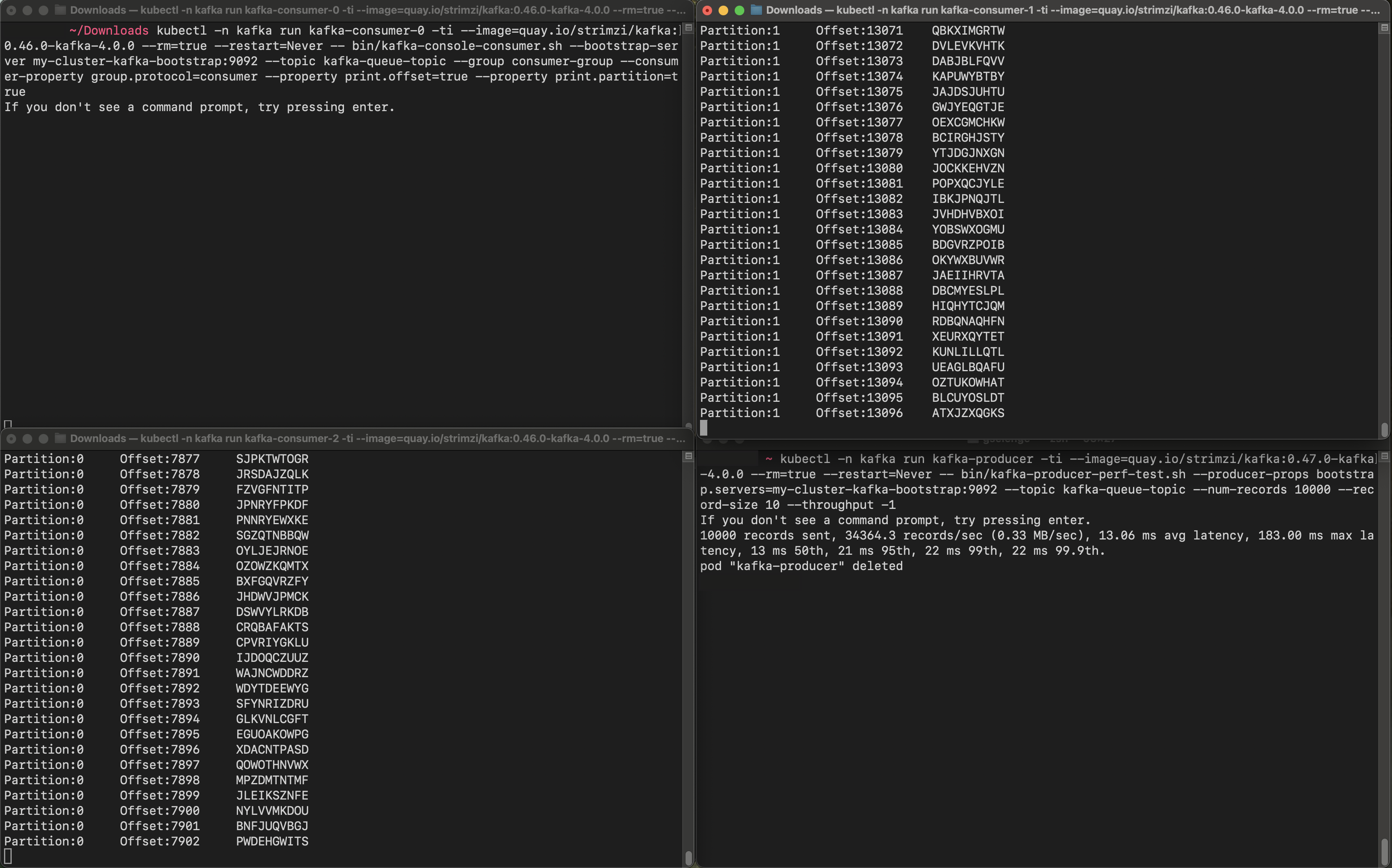
Only kafka-consumer-1 and kafka-consumer-2 actively fetched from one partition each, but kafka-consumer-0 was idle and did not fetch any records. Let’s describe this consumer group:
$ kubectl -n kafka run kafka-tool -ti --image=quay.io/strimzi/kafka:0.47.0-kafka-4.0.0 --rm=true --restart=Never \
-- bin/kafka-consumer-groups.sh \
--bootstrap-server my-cluster-kafka-bootstrap:9092 \
--describe \
--group consumer-group \
--members
GROUP CONSUMER-ID HOST CLIENT-ID PARTITIONS
consumer-group i1lwoDQfSTOrPBZuoueWzQ /10.244.0.134 console-consumer 0
consumer-group CowB2m5kR5WDz_jIIoEDQw /10.244.0.135 console-consumer 1
consumer-group fzNIbX2kTk-Lmxb5SUh-HA /10.244.0.136 console-consumer 1
$ kubectl -n kafka run kafka-tool -ti --image=quay.io/strimzi/kafka:0.47.0-kafka-4.0.0 --rm=true --restart=Never \
-- bin/kafka-consumer-groups.sh \
--bootstrap-server my-cluster-kafka-bootstrap:9092 \
--describe \
--group consumer-group
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
consumer-group kafka-queue-topic 1 13097 13097 0 CowB2m5kR5WDz_jIIoEDQw /10.244.0.135 console-consumer
consumer-group kafka-queue-topic 0 7903 7903 0 fzNIbX2kTk-Lmxb5SUh-HA /10.244.0.136 console-consumer
This group had three members, but only two were assigned partitions because the topic had only two partitions.
Partition Assignments
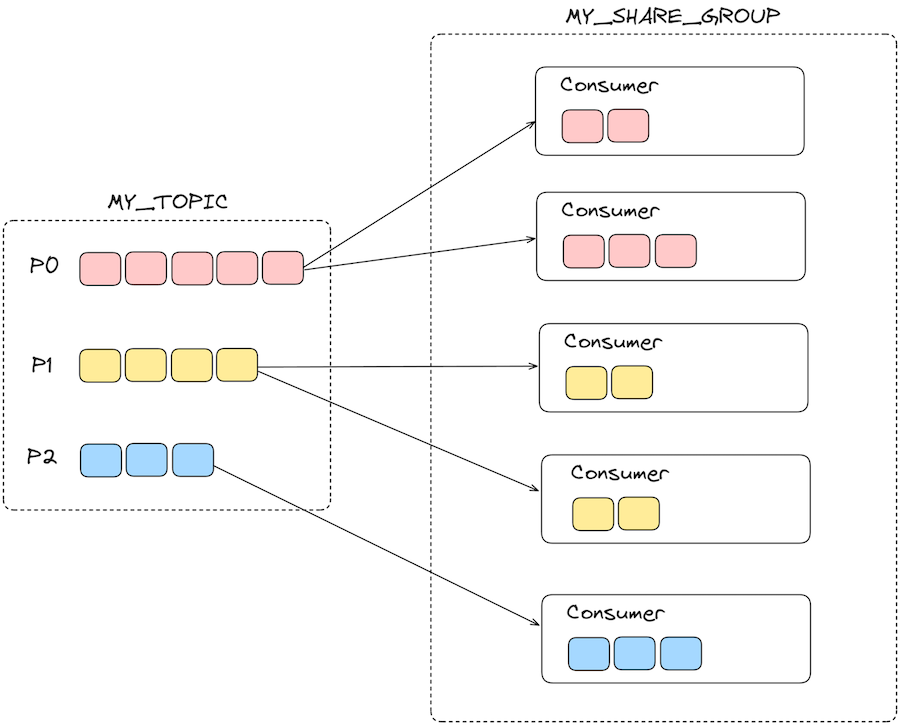
Partitions are assigned to members of a share group in round robin fashion while trying to maintain even balance in the assignment. Assignments in a share group are dynamic, when a consumer leaves or joins or when a partition is added, all the partitions are rebalanced across the members. As long as a consumer member continues to call the poll(), it stays in the group and continues to receive records from its assigned partitions. Similar to a regular consumer group, members of a share group also send periodic heartbeats in the background to the share group coordinator. If a member doesn’t send a heartbeat request within the group.share.session.timeout.ms, it is considered inactive and partitions are reassigned to other members. If it is sending heartbeat requests to the broker, but it does not call the poll() within max.poll.interval.ms, then it leaves the group and the partitions are reassigned as well.
Fetch mechanism
When a consumer in a share group fetches records, it acquires a batch of records with a time-limited acquisition. Batch size is controlled by the existing fetch configurations such as max.poll.records and fetch.max.bytes. While the records are acquired, they are not available for other consumers. The lock is automatically released if a record is not processed and acknowledged before the timeout and the record becomes available again for another delivery attempt. This makes sure delivery progresses even when a consumer fails to process a record. The lock duration can be configured with the group.share.record.lock.duration.ms broker configuration, which is set to 30s by default.
The number of records acquired from a partition by one share group is also limited. Once this limit is reached, fetching of records from the share group temporarily pauses until the number of acquired records reduces. The limit can be configured with the broker configuration, group.share.partition.max.record.locks which is set to 200 by default (but was changed to 2000 in Apache Kafka 4.1).
Records transition through different states when being fetched depending on the actions taken by consumers of a share group. Consumers can:
- Acknowledge once the record is successfully processed
- Release the record, to make it available for another delivery attempt
- Reject the record, if it is unprocessable and the record should not be available for another delivery attempt
If none of the above is done by (e.g., the consumer is still in the middle of processing the record and is taking a long time), the lock will be automatically released once the lock duration has elapsed.
While a share consumer processes records in batches, locking is applied per record even within a fetched batch. Records can be acknowledged both individually or in batches.
Delivery State
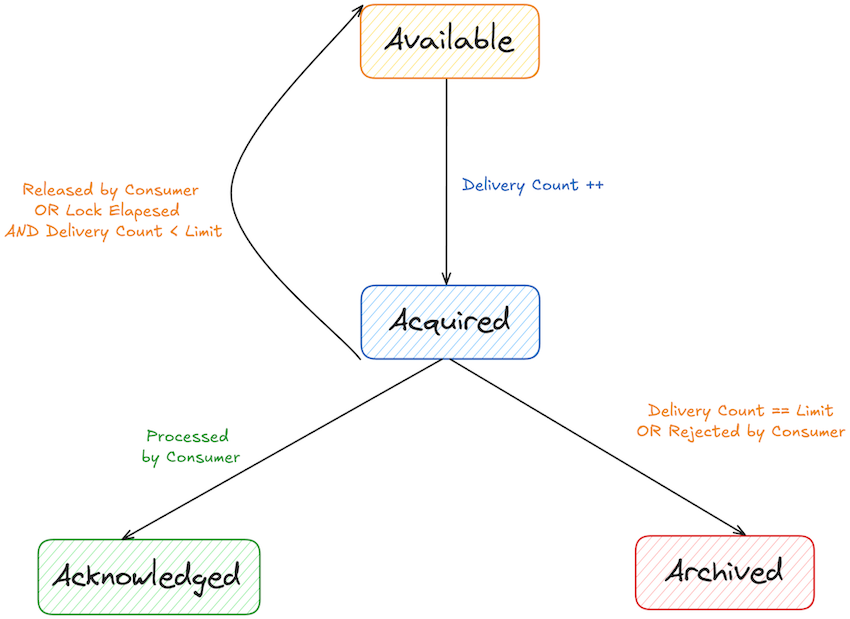
The delivery count for each record is tracked and gets incremented every time a consumer acquires the record. There is a limit on the number of times a record can be retried to avoid getting stuck trying to deliver an unprocessable record indefinitely. This limit also can be reconfigured with broker configuration, group.share.delivery.count.limit with default value of 5.
The delivery count determines which state the record should transition into later on. If the consumer releases the record or the lock duration has lapsed, it will go back into Available state as long as the delivery count has not reached the limit. The record will go into Acknowledged state if it has been successfully processed by the consumer. If the consumer rejects the record or its delivery count has reached the limit, the record will go into Archived state.
Share Group State
The share group manages state using an internal topic called, __share_group_state. This topic stores state of share groups including the partitions they are subscribed to and the state of those partitions such as the Share Partition Start Offset (SPSO) and the Share Partition End Offset (SPEO) as well as the delivery state and delivery count of the records in the partitions. As SPSO and SPEO naturally move forward as records get processed, the records before the SPSO move into Archived. The Archived state represents a record that is removed from the queue.
Normally users won’t need to look at the internal topic, but for the purpose of this blog, we can check the records in this topic using the console consumer tool:
$ kubectl -n kafka run share-group-state -ti --image=quay.io/strimzi/kafka:0.47.0-kafka-4.0.0 --rm=true --restart=Never -- bin/kafka-console-consumer.sh --bootstrap-server my-cluster-kafka-bootstrap:9092 --topic __share_group_state --from-beginning --formatter=org.apache.kafka.tools.consumer.group.share.ShareGroupStateMessageFormatter
The following is an example of the records produced to this topic which is in JSON format:
{
"key": {
"version": 0,
"data": {
"groupId": "my-share-group",
"topicId": "9fagJTJNTaa-FwT6umvvCA",
"partition": 0
}
},
"value": {
"version": 0,
"data": {
"snapshotEpoch": 2,
"stateEpoch": 0,
"leaderEpoch": 0,
"startOffset": 560,
"stateBatches": [
{
"firstOffset": 560,
"lastOffset": 560,
"deliveryState": 0,
"deliveryCount": 1
},
{
"firstOffset": 561,
"lastOffset": 564,
"deliveryState": 2,
"deliveryCount": 1
},
{
"firstOffset": 565,
"lastOffset": 565,
"deliveryState": 4,
"deliveryCount": 1
}
]
}
}
}
Subscribed partition states are stored in batches, as records are consumed and acknowledged in batches too. In the example above, you can see the state batches, one of which is for offsets between 561 and 564. These offsets have the same delivery state and count therefore share the same state. In comparison, the offset 560 and 565 have different delivery states therefore listed in individual states.
Map of states and enums:
| Enum | State |
|---|---|
| 0 | Available |
| 1 | Acquired |
| 2 | Acknowledged |
| 4 | Archived |
Let’s take a look at an example of a partition that a share group is subscribed to, which is called Share Partition:
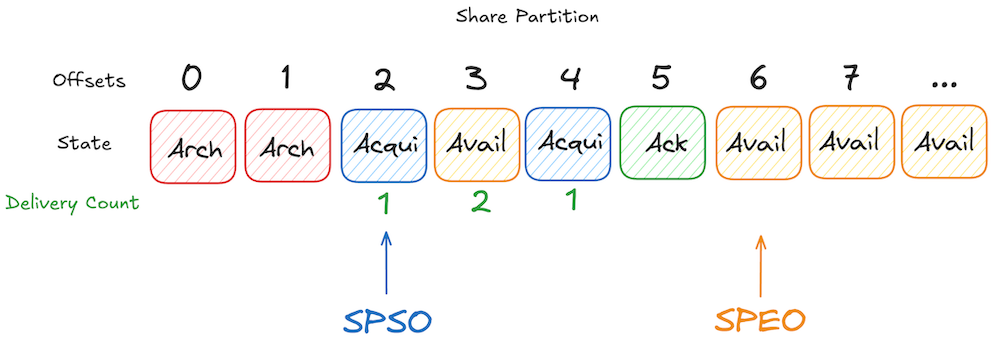
In this example, offset 2 is the start offset of the share group consuming from the partition. Records at offset 2 and 4 are currently Acquired for the first time, therefore delivery count is incremented to 1. However, the record at offset 3 is in an Available state with a delivery count of 2, which means a consumer of the share group has attempted to deliver this record twice so far and it will be retried until the maximum delivery count is reached. The record at offset 5 has been processed successfully and Acknowledged and the record at offset 6 is the next available record to be acquired by the share group, therefore it is the end offset for this share partition.
KafkaShareConsumer API
Let’s look at the new KafkaShareConsumer Java API added for share group consumers. It looks very similar to the KafkaConsumer API which makes it easier to use the new API if you are already familiar with it. With the KafkaShareConsumer API, users can do more fine-grained acknowledgements of the records that are consumed and processed. There are 2 different mechanisms to acknowledge records:
Acknowledging records in batches
When acknowledging a batch of records, the implicit acknowledgment is used by calling the poll(). In the following example, I created a simple share consumer client that implicitly acknowledges batches of records:
public class ShareGroupDemoImplicitAck {
private static final ObjectMapper OBJECT_MAPPER = new ObjectMapper();
@SuppressWarnings("InfiniteLoopStatement")
public static void main(final String[] args) {
Properties consumerProps = new Properties();
consumerProps.setProperty("bootstrap.servers", "localhost:9092");
// join the share group
consumerProps.setProperty("group.id", "my-share-group");
consumerProps.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumerProps.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaShareConsumer<String, String> consumer = new KafkaShareConsumer<>(consumerProps);
consumer.subscribe(List.of("kafka-queue-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); // #1
for (ConsumerRecord<String, String> record : records) {
try {
processRecord(record);
} catch (JsonProcessingException e) { // #2
System.out.println("Failed to process the record- Offset: " + record.offset() + " Value: " + record.value());
}
}
}
}
private static void processRecord(ConsumerRecord<String, String> record) throws JsonProcessingException {
JsonNode json = OBJECT_MAPPER.readTree(record.value());
System.out.println("Processed record with offset " + record.offset() + ": " + json.toPrettyString());
}
}
#1. When fetching another batch of records by calling poll(), the batch of records delivered in the previous poll are marked as successfully processed and acknowledged. This is the simplest and most efficient way to acknowledge records.
#2. In this example, no exception is thrown if it fails to process a record. It just catches the JsonProcessingException and prints a log message. In this case, the record still is implicitly acknowledged in the next poll().
Acknowledging individual records
This allows users to acknowledge an individual record depending on the outcome of processing the record. Each record is acknowledged using a call to acknowledge(), which takes different types of acknowledgement as an argument: ACCEPT, RELEASE and REJECT. This aligns with the actions that can be taken by share group consumers mentioned previously.
I created another share consumer client that explicitly acknowledges batches of records:
public class ShareGroupDemoExplicitAck {
private static final ObjectMapper OBJECT_MAPPER = new ObjectMapper();
@SuppressWarnings("InfiniteLoopStatement")
public static void main(final String[] args) {
Properties producerProps = new Properties();
producerProps.setProperty("bootstrap.servers", "localhost:9092");
producerProps.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
producerProps.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(producerProps);
Properties consumerProps = new Properties();
consumerProps.setProperty("bootstrap.servers", "localhost:9092");
// join the share group
consumerProps.setProperty("group.id", "my-share-group");
consumerProps.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumerProps.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumerProps.setProperty("share.acknowledgement.mode", "explicit"); // #1
KafkaShareConsumer<String, String> consumer = new KafkaShareConsumer<>(consumerProps);
consumer.subscribe(List.of("kafka-queue-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
if (record.key() != null && "skip".equals(record.key())) { // #2
System.out.println("Skipping the record - Offset: " + record.offset() +
" Key: " + record.key() +
" Value: " + record.value() +
" Delivery count: " + record.deliveryCount().get());
consumer.acknowledge(record, AcknowledgeType.RELEASE);
break; // #3
} else {
try {
processRecord(record);
} catch (JsonProcessingException e) {
System.out.println("Failed to process the record- Offset: " + record.offset() + " Value: " + record.value());
handlePoisonRecord(record, producer); // #4
consumer.acknowledge(record, AcknowledgeType.REJECT); // #5
} catch (Exception e ) {
System.out.println("Failed to process the record- Offset: " + record.offset() + " Value: " + record.value());
consumer.acknowledge(record, AcknowledgeType.RELEASE); // #6
}
}
consumer.acknowledge(record, AcknowledgeType.ACCEPT); // #7
}
consumer.commitSync(); // #8
}
}
private static void processRecord(ConsumerRecord<String, String> record) throws JsonProcessingException {
JsonNode json = OBJECT_MAPPER.readTree(record.value());
System.out.println("Processed record with offset " + record.offset() + ": " + json.toPrettyString());
}
private static void handlePoisonRecord(ConsumerRecord<String, String> record, KafkaProducer<String, String> producer) {
producer.send(new ProducerRecord<>("dead-letter-queue-topic", record.key(), record.value()));
}
}
#1. In this example, I used the new consumer configuration added for this feature, share.acknowledgement.mode, and set it to explicit. This configuration is set to implicit by default, which is why I didn’t need to set this configuration for the previous example.
#2. The consumer immediately releases a record if its key is set to skip, just to demonstrate the retry of delivery attempts. The record is fetched again in the next call to poll() and eventually hits the maximum delivery attempts. Then it is transitioned into an Archived state because the client never processes it. Once archived, this record is no longer available for another delivery.
#3. If the record’s key is skip, the consumer exits the loop. This demonstrates how delivery retries work and what happens when some records remain unacknowledged during a poll() cycle.
#4. When a record value cannot be mapped to a valid JSON object, the processing method throws a JsonProcessingException and the client handles it as a poison record. Since the dead letter queue is not supported yet, users have to implement this themselves. In this example, we send the records that cannot be processed to another topic dead-letter-queue-topic.
#5. Once a poison record is sent to the dead letter queue topic, the consumer client rejects it so that it gets archived immediately.
#6. If the client encounters an error not caused by the JSON mapping, it releases the record for another attempt because it could be a transient failure.
#7. When no exception occurred during the processing, the consumer client accepts the record. Once all the records in the batch are processed and acknowledged individually, these states are stored locally in the consumer.
#8. The client calls commitSync() or commitAsync() to commit the state to the internal topic, __share_group_state. In #2, it exits the loop for processing each record, and commits the state by calling commitSync(). The records in the batch that were not processed or acknowledged yet, are presented to the consumer client again as part of the same acquisition and their delivery count is not incremented. Also share groups do not support auto-commit.
Here is an example of a client application using KafkaProducer to send records in valid and invalid formats to the kafka-queue-topic used for this demonstration:
public class ShareGroupDemoProducer {
public static void main(final String[] args) throws InterruptedException, ExecutionException {
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092");
props.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
System.out.println("Shutdown hook triggered. Cleaning up...");
producer.close();
}));
int recordNum = 1;
while (true) {
String recordKey = null;
String recordValue;
if (recordNum % 10 == 0) {
// Send every 10th record with in a non-processable format
recordValue = "Poison message: this record is not in JSON format (recordNumber: " + recordNum + ")";
} else if(recordNum % 5 == 0) {
// Send every 5th record with key "skip"
recordKey = "skip";
recordValue = "Record to skip processing";
} else {
recordValue = "{ \"isJson\": \"true\", \"recordNumber\": " + recordNum + ", \"recordValue\": \"This is a test message\" }";
}
ProducerRecord record = new ProducerRecord<>("kafka-queue-topic", recordKey, recordValue);
RecordMetadata metadata = (RecordMetadata) producer.send(record).get();
System.out.println("Produced record at offset " + metadata.offset() + ": " + record.value());
recordNum++;
Thread.sleep(Long.valueOf(2000));
}
}
}
Inspecting __share_group_state topic
Let’s now take a look at the output from ShareGroupDemoExplicitAck while running ShareGroupDemoProducer at the same time:
Failed to process the record- Offset: 361 Value: Poison message: this record is not in JSON format (recordNumber: 10)
Processed record with offset 362: {
"isJson" : "true",
"recordNumber" : 11,
"recordValue" : "This is a test message"
}
Processed record with offset 363: {
"isJson" : "true",
"recordNumber" : 12,
"recordValue" : "This is a test message"
}
Processed record with offset 364: {
"isJson" : "true",
"recordNumber" : 13,
"recordValue" : "This is a test message"
}
Processed record with offset 365: {
"isJson" : "true",
"recordNumber" : 14,
"recordValue" : "This is a test message"
}
Skipping the record - Offset: 366 Key: skip Value: Record to skip processing Delivery count: 1
Skipping the record - Offset: 366 Key: skip Value: Record to skip processing Delivery count: 2
Skipping the record - Offset: 366 Key: skip Value: Record to skip processing Delivery count: 3
Skipping the record - Offset: 366 Key: skip Value: Record to skip processing Delivery count: 4
Skipping the record - Offset: 366 Key: skip Value: Record to skip processing Delivery count: 5
Processed record with offset 367: {
"isJson" : "true",
"recordNumber" : 16,
"recordValue" : "This is a test message"
}
The record at offset 361 was rejected because it hit an error mapping the record value into JSON and was considered a poison message. The records at offset 362, 363, 364 and 365 were successfully processed and accepted. The record at offset 366 was released without being processed. It was retried five times before being archived and was not retried again. The consumer then continued to the next record at offset 367.
Let’s inspect the state of these records from the internal topic, __share_group_state just to understand the different states the records transitioned through:
$ kubectl -n kafka run consumer -ti --image=quay.io/strimzi/kafka:0.47.0-kafka-4.0.0 --rm=true --restart=Never \
-- bin/kafka-console-consumer.sh \
--bootstrap-server my-cluster-kafka-bootstrap:9092 \
--topic __share_group_state \
--formatter=org.apache.kafka.tools.consumer.group.share.ShareGroupStateMessageFormatter
{
"key": {
"version": 1,
"data": {
"groupId": "my-share-group",
"topicId": "9fagJTJNTaa-FwT6umvvCA",
"partition": 0
}
},
"value": {
"version": 0,
"data": {
"snapshotEpoch": 1,
"leaderEpoch": 0,
"startOffset": 361,
"stateBatches": [
{
"firstOffset": 361,
"lastOffset": 361,
"deliveryState": 4,
"deliveryCount": 1
}
]
}
}
}
The record at offset 361 was placed in the Archived (enum 4) state after the first delivery attempt, so it was not retried.
{
"key": {
"version": 1,
"data": {
"groupId": "my-share-group",
"topicId": "9fagJTJNTaa-FwT6umvvCA",
"partition": 0
}
},
"value": {
"version": 0,
"data": {
"snapshotEpoch": 1,
"leaderEpoch": 0,
"startOffset": 364,
"stateBatches": [
{
"firstOffset": 364,
"lastOffset": 364,
"deliveryState": 2,
"deliveryCount": 1
}
]
}
}
}
{
"key": {
"version": 1,
"data": {
"groupId": "my-share-group",
"topicId": "9fagJTJNTaa-FwT6umvvCA",
"partition": 0
}
},
"value": {
"version": 0,
"data": {
"snapshotEpoch": 1,
"leaderEpoch": 0,
"startOffset": 365,
"stateBatches": [
{
"firstOffset": 365,
"lastOffset": 365,
"deliveryState": 2,
"deliveryCount": 1
}
]
}
}
}
The records at offsets 364 and 365 were in the Acknowledged (enum 2) state after the first delivery attempt, as they had been processed and acknowledged successfully. (Offsets 362 and 363 were in the same state but are not shown in the output.)
{
"key": {
"version": 1,
"data": {
"groupId": "my-share-group",
"topicId": "9fagJTJNTaa-FwT6umvvCA",
"partition": 0
}
},
"value": {
"version": 0,
"data": {
"snapshotEpoch": 1,
"leaderEpoch": 0,
"startOffset": 366,
"stateBatches": [
{
"firstOffset": 366,
"lastOffset": 366,
"deliveryState": 0,
"deliveryCount": 1
}
]
}
}
}
The record at offset 366 was in the Available (enum 0) state after the first delivery attempt. This is the record the consumer skipped from processing and simply released. However in the following output, we see that delivery attempts have increased.
{
"key": {
"version": 1,
"data": {
"groupId": "my-share-group",
"topicId": "9fagJTJNTaa-FwT6umvvCA",
"partition": 0
}
},
"value": {
"version": 0,
"data": {
"snapshotEpoch": 1,
"leaderEpoch": 0,
"startOffset": 366,
"stateBatches": [
{
"firstOffset": 366,
"lastOffset": 366,
"deliveryState": 0,
"deliveryCount": 4
}
]
}
}
}
{
"key": {
"version": 1,
"data": {
"groupId": "my-share-group",
"topicId": "9fagJTJNTaa-FwT6umvvCA",
"partition": 0
}
},
"value": {
"version": 0,
"data": {
"snapshotEpoch": 1,
"leaderEpoch": 0,
"startOffset": 366,
"stateBatches": [
{
"firstOffset": 366,
"lastOffset": 366,
"deliveryState": 4,
"deliveryCount": 5
}
]
}
}
}
After 4 attempts of delivery, the record was still in the Available (enum 0) state but after the 5th attempt, it went into the Archived (enum 4) state, which is why it was not retried again.
Configurations
The broker configurations mentioned in this blog:
These can be set in your Kafka CR, as shown in the example above.
The consumer configurations mentioned in this blog:
These can be set in your client application as demonstrated in the Java API example.
The current limitations of the feature
This feature is currently not recommended for production clusters as of Apache Kafka 4.0.0 but can be tried out with a test cluster as demonstrated above. If you are trying out this feature on your existing development/test cluster, note that you will not be able to upgrade to Apache Kafka 4.1 or later. You would have to disable this feature first and delete the state topic, in order to upgrade to a later version.
Summary
This blog post explored how to configure a Kafka cluster managed by Strimzi to behave like a traditional queue. It introduced the concept of share groups, which enables queue-like consumption of records, and compares them to regular consumer groups, highlighting their benefits. Through hands-on examples, it demonstrated how to consume and acknowledge records using the new KafkaShareConsumer API to achieve queue-style processing.
Share this:
![]()
![]()
![]()
![]()
![]()