# ...
config:
ssl.cipher.suites: TLS_AES_256_GCM_SHA384, TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 # (1)
ssl.enabled.protocols: TLSv1.3, TLSv1.2 # (2)
ssl.protocol: TLSv1.3 # (3)
ssl.endpoint.identification.algorithm: HTTPS # (4)
# ...Configuring Strimzi (1.0.1)
Table of Contents
- 1. Using schema properties to configure custom resources
- 2. Common configuration properties
- 3.
Kafkaschema reference - 4.
KafkaSpecschema reference - 5.
KafkaClusterSpecschema reference - 6.
GenericKafkaListenerschema reference - 7.
KafkaListenerAuthenticationTlsschema reference - 8.
KafkaListenerAuthenticationScramSha512schema reference - 9.
KafkaListenerAuthenticationCustomschema reference - 10.
GenericKafkaListenerConfigurationschema reference- 10.1. Providing your own listener certificates
- 10.2. Avoiding hops to other nodes
- 10.3. Providing CIDR source ranges for a loadbalancer
- 10.4. Specifying a preferred node port address type
- 10.5. Using fully-qualified DNS names
- 10.6. Specifying the hostname
- 10.7. Overriding assigned node ports
- 10.8. Requesting a specific loadbalancer IP address
- 10.9. Adding listener annotations to Kubernetes resources
- 10.10.
GenericKafkaListenerConfigurationschema properties
- 11.
CertAndKeySecretSourceschema reference - 12.
GenericKafkaListenerConfigurationBootstrapschema reference - 13.
GenericKafkaListenerConfigurationBrokerschema reference - 14.
KafkaAuthorizationSimpleschema reference - 15.
KafkaAuthorizationCustomschema reference - 16.
TopologyLabelRackschema reference - 17.
EnvironmentVariableRackschema reference - 18.
Probeschema reference - 19.
JvmOptionsschema reference - 20.
SystemPropertyschema reference - 21.
KafkaJmxOptionsschema reference - 22.
KafkaJmxAuthenticationPasswordschema reference - 23.
JmxPrometheusExporterMetricsschema reference - 24.
ExternalConfigurationReferenceschema reference - 25.
StrimziMetricsReporterschema reference - 26.
StrimziMetricsReporterValuesschema reference - 27.
InlineLoggingschema reference - 28.
ExternalLoggingschema reference - 29.
KafkaClusterTemplateschema reference - 30.
PodTemplateschema reference - 31.
MetadataTemplateschema reference - 32.
AdditionalVolumeschema reference - 33.
EmptyDirVolumeschema reference - 34.
InternalServiceTemplateschema reference - 35.
ResourceTemplateschema reference - 36.
PodDisruptionBudgetTemplateschema reference - 37.
ContainerTemplateschema reference - 38.
ContainerEnvVarschema reference - 39.
ContainerEnvVarSourceschema reference - 40.
TieredStorageCustomschema reference - 41.
RemoteStorageManagerschema reference - 42.
QuotasPluginKafkaschema reference - 43.
QuotasPluginStrimzischema reference - 44.
EntityOperatorSpecschema reference - 45.
EntityTopicOperatorSpecschema reference - 46.
EntityUserOperatorSpecschema reference - 47.
EntityOperatorTemplateschema reference - 48.
DeploymentTemplateschema reference - 49.
CertificateAuthorityschema reference - 50.
CruiseControlSpecschema reference - 51.
CruiseControlTemplateschema reference - 52.
BrokerCapacityschema reference - 53.
BrokerCapacityOverrideschema reference - 54.
HashLoginServiceApiUsersschema reference - 55.
PasswordSourceschema reference - 56.
KafkaAutoRebalanceConfigurationschema reference - 57.
LocalObjectReferenceschema reference - 58.
KafkaExporterSpecschema reference - 59.
KafkaExporterTemplateschema reference - 60.
KafkaStatusschema reference - 61.
Conditionschema reference - 62.
ListenerStatusschema reference - 63.
ListenerAddressschema reference - 64.
UsedNodePoolStatusschema reference - 65.
KafkaAutoRebalanceStatusschema reference - 66.
KafkaAutoRebalanceStatusBrokersschema reference - 67.
KafkaConnectschema reference - 68.
KafkaConnectSpecschema reference - 69.
ClientTlsschema reference - 70.
CertSecretSourceschema reference - 71.
KafkaClientAuthenticationTlsschema reference - 72.
KafkaClientAuthenticationScramSha256schema reference - 73.
PasswordSecretSourceschema reference - 74.
KafkaClientAuthenticationScramSha512schema reference - 75.
KafkaClientAuthenticationPlainschema reference - 76.
KafkaClientAuthenticationCustomschema reference - 77.
OpenTelemetryTracingschema reference - 78.
KafkaConnectTemplateschema reference - 79.
BuildConfigTemplateschema reference - 80.
Buildschema reference - 81.
DockerOutputschema reference - 82.
ImageStreamOutputschema reference - 83.
Pluginschema reference - 84.
JarArtifactschema reference - 85.
TgzArtifactschema reference - 86.
ZipArtifactschema reference - 87.
MavenArtifactschema reference - 88.
OtherArtifactschema reference - 89.
MountedPluginschema reference - 90.
ImageArtifactschema reference - 91.
KafkaConnectStatusschema reference - 92.
ConnectorPluginschema reference - 93.
KafkaTopicschema reference - 94.
KafkaTopicSpecschema reference - 95.
KafkaTopicStatusschema reference - 96.
ReplicasChangeStatusschema reference - 97.
KafkaUserschema reference - 98.
KafkaUserSpecschema reference - 99.
KafkaUserTlsClientAuthenticationschema reference - 100.
KafkaUserTlsExternalClientAuthenticationschema reference - 101.
KafkaUserScramSha512ClientAuthenticationschema reference - 102.
Passwordschema reference - 103.
KafkaUserAuthorizationSimpleschema reference - 104.
AclRuleschema reference - 105.
AclRuleTopicResourceschema reference - 106.
AclRuleGroupResourceschema reference - 107.
AclRuleClusterResourceschema reference - 108.
AclRuleTransactionalIdResourceschema reference - 109.
KafkaUserQuotasschema reference - 110.
KafkaUserTemplateschema reference - 111.
KafkaUserStatusschema reference - 112.
KafkaBridgeschema reference - 113.
KafkaBridgeSpecschema reference - 114.
KafkaBridgeHttpConfigschema reference - 115.
KafkaBridgeHttpTlsschema reference - 116.
KafkaBridgeHttpCorsschema reference - 117.
KafkaBridgeAdminClientSpecschema reference - 118.
KafkaBridgeConsumerSpecschema reference - 119.
KafkaBridgeProducerSpecschema reference - 120.
KafkaBridgeTemplateschema reference - 121.
KafkaBridgeStatusschema reference - 122.
KafkaConnectorschema reference - 123.
KafkaConnectorSpecschema reference - 124.
AutoRestartschema reference - 125.
ListOffsetsschema reference - 126.
AlterOffsetsschema reference - 127.
KafkaConnectorStatusschema reference - 128.
AutoRestartStatusschema reference - 129.
KafkaMirrorMaker2schema reference - 130.
KafkaMirrorMaker2Specschema reference - 131.
KafkaMirrorMaker2TargetClusterSpecschema reference - 132.
KafkaMirrorMaker2MirrorSpecschema reference - 133.
KafkaMirrorMaker2ClusterSpecschema reference - 134.
KafkaMirrorMaker2ConnectorSpecschema reference - 135.
KafkaMirrorMaker2Statusschema reference - 136.
KafkaRebalanceschema reference - 137.
KafkaRebalanceSpecschema reference - 138.
BrokerAndVolumeIdsschema reference - 139.
KafkaRebalanceStatusschema reference - 140.
KafkaRebalanceProgressschema reference - 141.
KafkaNodePoolschema reference - 142.
KafkaNodePoolSpecschema reference - 143.
EphemeralStorageschema reference - 144.
PersistentClaimStorageschema reference - 145.
JbodStorageschema reference - 146.
KafkaNodePoolTemplateschema reference - 147.
KafkaNodePoolStatusschema reference - 148.
StrimziPodSetschema reference - 149.
StrimziPodSetSpecschema reference - 150.
StrimziPodSetStatusschema reference
1. Using schema properties to configure custom resources
Custom resources offer a flexible way to manage and fine-tune the operation of Strimzi components using configuration properties. This reference guide describes common configuration properties that apply to multiple custom resources, as well as the configuration properties available for each custom resource schema available with Strimzi. Where appropriate, expanded descriptions of properties and examples of how they are configured are provided.
The properties defined for each schema provide a structured and organized way to specify configuration for the custom resources.
Whether it’s adjusting resource allocation or specifying access controls, the properties in the schemas allow for a granular level of configuration.
For example, you can use the properties of the KafkaClusterSpec schema to specify the type of storage for a Kafka cluster or add listeners that provide secure access to Kafka brokers.
Some property options within a schema may be constrained, as indicated in the property descriptions. These constraints define specific options or limitations on the values that can be assigned to those properties. Constraints ensure that the custom resources are configured with valid and appropriate values.
2. Common configuration properties
Use Common configuration properties to configure Strimzi custom resources. You add common configuration properties to a custom resource like any other supported configuration for that resource.
2.1. replicas
Use the replicas property to configure replicas.
The type of replication depends on the resource.
-
KafkaTopicuses a replication factor to configure the number of replicas of each partition within a Kafka cluster. -
Kafka components use replicas to configure the number of pods in a deployment to provide better availability and scalability.
|
Note
|
When running a Kafka component on Kubernetes it may not be necessary to run multiple replicas for high availability. When the node where the component is deployed crashes, Kubernetes will automatically reschedule the Kafka component pod to a different node. However, running Kafka components with multiple replicas can provide faster failover times as the other nodes will be up and running. |
2.2. bootstrapServers
Use the bootstrapServers property to configure a list of bootstrap servers.
The bootstrap server lists can refer to Kafka clusters that are not deployed in the same Kubernetes cluster. They can also refer to a Kafka cluster not deployed by Strimzi.
If on the same Kubernetes cluster, each list must ideally contain the Kafka cluster bootstrap service which is named CLUSTER-NAME-kafka-bootstrap and a port number.
If deployed by Strimzi but on different Kubernetes clusters, the list content depends on the approach used for exposing the clusters (routes, ingress, nodeports or loadbalancers).
When using Kafka with a Kafka cluster not managed by Strimzi, you can specify the bootstrap servers list according to the configuration of the given cluster.
2.3. ssl (supported TLS versions and cipher suites)
You can incorporate SSL configuration and cipher suite specifications to further secure TLS-based communication between your client application and a Kafka cluster. In addition to the standard TLS configuration, you can specify a supported TLS version and enable cipher suites in the configuration for the Kafka broker. You can also add the configuration to your clients if you wish to limit the TLS versions and cipher suites they use. The configuration on the client must only use protocols and cipher suites that are enabled on the broker.
A cipher suite is a set of security mechanisms for secure connection and data transfer.
For example, the cipher suite TLS_AES_256_GCM_SHA384 is composed of the following mechanisms, which are used in conjunction with the TLS protocol:
-
AES (Advanced Encryption Standard) encryption (256-bit key)
-
GCM (Galois/Counter Mode) authenticated encryption
-
SHA384 (Secure Hash Algorithm) data integrity protection
The combination is encapsulated in the TLS_AES_256_GCM_SHA384 cipher suite specification.
The ssl.enabled.protocols property specifies the available TLS versions that can be used for secure communication between the cluster and its clients.
The ssl.protocol property sets the default TLS version for all connections, and it must be chosen from the enabled protocols.
Use the ssl.endpoint.identification.algorithm property to enable or disable hostname verification (configurable only in components based on Kafka clients - Kafka Connect, MirrorMaker 2, and HTTP Bridge).
Example SSL configuration
-
Cipher suite specifications enabled.
-
TLS versions supported.
-
Default TLS version is
TLSv1.3. If a client only supports TLSv1.2, it can still connect to the broker and communicate using that supported version, and vice versa if the configuration is on the client and the broker only supports TLSv1.2. -
Hostname verification is enabled by setting to
HTTPS. An empty string disables the verification.
2.4. trustedCertificates
Use the tls and trustedCertificates properties to enable TLS encryption and specify secrets under which TLS certificates are stored in X.509 format.
You can add this configuration to the Kafka Connect, Kafka MirrorMaker, and HTTP Bridge components for TLS connections to the Kafka cluster.
You can use the secrets created by the Cluster Operator for the Kafka cluster,
or you can create your own TLS certificate file, then create a Secret from the file:
Creating a secret
kubectl create secret generic <my_secret> \
--from-file=<my_tls_certificate_file.crt>-
Replace
<my_secret>with your secret name. -
Replace
<my_tls_certificate_file.crt>with the path to your TLS certificate file.
Use the pattern property to include all files in the secret that match the pattern.
Using the pattern property means that the custom resource does not need to be updated if certificate file names change.
However, you can specify a specific file using the certificate property instead of the pattern property.
Example TLS encryption configuration for components
tls:
trustedCertificates:
- secretName: my-cluster-cluster-cert
pattern: "*.crt"
- secretName: my-cluster-cluster-cert
certificate: ca2.crtIf you want to enable TLS encryption, but use the default set of public certification authorities shipped with Java,
you can specify trustedCertificates as an empty array:
Example of enabling TLS with the default Java certificates
tls:
trustedCertificates: []Similarly, you can use the tlsTrustedCertificates property in the configuration for oauth and keycloak authentication and authorization types that integrate with authorization servers.
The configuration sets up encrypted TLS connections to the authorization server.
Example TLS encryption configuration for authentication types
tlsTrustedCertificates:
- secretName: oauth-server-ca
pattern: "*.crt"For information on configuring mTLS authentication, see the KafkaClientAuthenticationTls schema reference.
2.5. resources
Configure resource requests and limits to control resources for Strimzi containers.
You can specify requests and limits for memory and cpu resources.
The requests should be enough to ensure a stable performance of Kafka.
How you configure resources in a production environment depends on a number of factors. For example, applications are likely to be sharing resources in your Kubernetes cluster.
For Kafka, the following aspects of a deployment can impact the resources you need:
-
Throughput and size of messages
-
The number of network threads handling messages
-
The number of producers and consumers
-
The number of topics and partitions
The values specified for resource requests are reserved and always available to the container. Resource limits specify the maximum resources that can be consumed by a given container. The amount between the request and limit is not reserved and might not be always available. A container can use the resources up to the limit only when they are available. Resource limits are temporary and can be reallocated.
Resource requests and limits

If you set limits without requests or vice versa, Kubernetes uses the same value for both. Setting equal requests and limits for resources guarantees quality of service, as Kubernetes will not kill containers unless they exceed their limits.
Configure resource requests and limits for components using resources properties in the spec of following custom resources:
Use the KafkaNodePool custom resource for Kafka nodes (spec.resources)
Use the Kafka custom resource for the following components:
-
Topic Operator (
spec.entityOperator.topicOperator.resources) -
User Operator (
spec.entityOperator.userOperator.resources) -
Cruise Control (
spec.cruiseControl.resources) -
Kafka Exporter (
spec.kafkaExporter.resources)
For other components, resources are configured in the corresponding custom resource. For example:
-
KafkaConnectresource for Kafka Connect (spec.resources) -
KafkaMirrorMaker2resource for MirrorMaker (spec.resources) -
KafkaBridgeresource for HTTP Bridge (spec.resources)
Example resource configuration for a node pool
apiVersion: kafka.strimzi.io/v1
kind: KafkaNodePool
metadata:
name: pool-a
labels:
strimzi.io/cluster: my-cluster
spec:
replicas: 3
roles:
- broker
resources:
requests:
memory: 64Gi
cpu: "8"
limits:
memory: 64Gi
cpu: "12"
# ...Example resource configuration for the Topic Operator
apiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
# ..
entityOperator:
#...
topicOperator:
#...
resources:
requests:
memory: 512Mi
cpu: "1"
limits:
memory: 512Mi
cpu: "1"If the resource request is for more than the available free resources in the Kubernetes cluster, the pod is not scheduled.
|
Note
|
Strimzi uses the Kubernetes syntax for specifying memory and cpu resources.
For more information about managing computing resources on Kubernetes, see Managing Compute Resources for Containers.
|
- Memory resources
-
When configuring memory resources, consider the total requirements of the components.
Kafka runs inside a JVM and uses an operating system page cache to store message data before writing to disk. The memory request for Kafka should fit the JVM heap and page cache. You can configure the
jvmOptionsproperty to control the minimum and maximum heap size.Other components don’t rely on the page cache. You can configure memory resources without configuring the
jvmOptionsto control the heap size.Memory requests and limits are specified in megabytes, gigabytes, mebibytes, and gibibytes. Use the following suffixes in the specification:
-
Mfor megabytes -
Gfor gigabytes -
Mifor mebibytes -
Gifor gibibytes
Example resources using different memory units# ... resources: requests: memory: 512Mi limits: memory: 2Gi # ...For more details about memory specification and additional supported units, see Meaning of memory.
-
- CPU resources
-
A CPU request should be enough to give a reliable performance at any time. CPU requests and limits are specified as cores or millicpus/millicores.
CPU cores are specified as integers (
5CPU core) or decimals (2.5CPU core). 1000 millicores is the same as1CPU core.Example CPU units# ... resources: requests: cpu: 500m limits: cpu: 2.5 # ...The computing power of 1 CPU core may differ depending on the platform where Kubernetes is deployed.
For more information on CPU specification, see Meaning of CPU.
2.5.1. In-place updates of resource requests and limits
The following components support in-place updates of resource requests and limits:
-
Kafka controllers and brokers
-
Kafka Connect nodes
-
Kafka MirrorMaker 2 nodes
|
Note
|
Support for in-place resource updates is currently experimental and might change in the future. |
To enable in-place resource updates, set the strimzi.io/in-place-resizing annotation to "true" in the corresponding custom resource (Kafka, KafkaConnect, or KafkaMirrorMaker2).
Example
Kafka resource with enabled in-place resource updates enabledapiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
annotations:
strimzi.io/in-place-resizing: "true"
spec:
# ...When enabled, Strimzi applies in-place resource updates when you change resource requests and limits in the corresponding custom resources (KafkaNodePool resources for Kafka clusters, or KafkaConnect and KafkaMirrorMaker2 resources for Connect and MirrorMaker 2).
In the following situations, in-place resource updates are not possible. Strimzi uses a rolling update instead:
-
Removing resource limits.
-
Reducing memory requests and limits below current usage.
-
Resource updates that exceed total node capacity.
-
Resource updates that exceed available node capacity (deferred updates).
Use the additional strimzi.io/in-place-resizing-wait-for-deferred annotation to prevent pods rolling when in-place resizing is deferred.
When enabled, Strimzi waits indefinitely for Kubernetes to be able to complete the pod resize.
To force the update, perform a manual rolling update by restarting a pod.
.Example
KafkaConnect resource with in-place resizing and deferred waitingapiVersion: kafka.strimzi.io/v1
kind: KafkaConnect
metadata:
name: my-cluster
annotations:
strimzi.io/in-place-resizing: "true"
strimzi.io/in-place-resizing-wait-for-deferred: "true"
spec:
# ...|
Important
|
Java Virtual Machine (JVM) does not register the in-place memory request and limit updates. When you increase the memory of the Kafka pod, JVM will not use the additional resources for its heap memory. But the additional memory might be used, for example, for the disk page cache. Similarly, when you decrease the memory resources below the maximal Java heap size, you might out-of-memory errors are possible. |
To learn more about in-place pod resizing, see the Kubernetes documentation on resizing CPU and memory resources assigned to containers.
2.6. image
Use the image property to configure the container image used by the component.
Overriding container images is recommended only in special situations where you need to use a different container registry or a custom image.
For example, if your network does not allow access to the container repository used by Strimzi, you can copy the Strimzi images or build them from the source. However, if the configured image is not compatible with Strimzi images, it might not work properly.
A copy of the container image might also be customized and used for debugging.
You can specify which container image to use for a component using the image property in the following resources:
-
Kafka.spec.kafka -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.cruiseControl -
Kafka.spec.kafkaExporter -
Kafka.spec.kafkaBridge -
KafkaConnect.spec -
KafkaMirrorMaker2.spec -
KafkaBridge.spec
|
Note
|
Changing the Kafka image version does not automatically update the image versions for other Kafka components, such as Kafka Exporter. These components are not version dependent, so no additional configuration is necessary when updating the Kafka image version. |
Setting Kafka component images
Strimzi supports multiple Kafka versions across Kafka, Kafka Connect, and Kafka MirrorMaker 2 components. Each component requires a specific container image, which can be configured in two places:
-
Cluster Operator environment variables (Default image mappings)
-
Custom resource configuration
Each environment variable maps Kafka versions to container images. These mappings are used when a custom resource does not explicitly specify an image. You can override the default image by specifying the image and the matching version in the custom resource.
| Component | Environment variable |
|---|---|
Kafka |
|
Kafka Connect |
|
MirrorMaker 2 |
|
| Custom resource | Image property | Version property |
|---|---|---|
|
|
|
|
|
|
|
|
|
The values for the environment variables and those specified for image and version in the component configuration determines the image and Kafka version used:
image set? |
version set? |
Result |
|---|---|---|
✗ |
✗ |
Uses Cluster Operator’s default image and corresponding Kafka version |
✓ |
✗ |
Uses specified image and default Kafka version |
✗ |
✓ |
Uses image from environment variable for specified Kafka version |
✓ |
✓ |
Uses specified image and assumes specified Kafka version matches |
|
Note
|
To avoid Kafka version and image mismatches, set the version property and allow the Cluster Operator to select the matching image from its mappings.
If you need to change the default image mapping for a given Kafka version, configure the Cluster Operator’s environment variables.
|
Even if the configuration is syntactically correct, it can still be invalid if the image and version mismatch. To ensure a valid configuration:
-
The specified
versionmust match the Kafka version that the image is built for. -
The specified
versionmust be one of the versions supported by the operator. -
If you set a custom
image, always setversionto the Kafka version of that image.
Here we can see what happens with versions 4.1.0 and 4.2.0 (the default).
image set? |
version set? |
Image used | Kafka version | Valid? |
|---|---|---|---|---|
✗ |
✗ |
4.2.0 (default) |
4.2.0 |
✓ |
✗ |
4.1.0 |
4.1.0 (from mapping) |
4.1.0 |
✓ |
Custom 4.1.0 |
4.1.0 |
Custom 4.1.0 |
4.1.0 |
✓ |
Custom 4.1.0 |
✗ |
Custom 4.1.0 |
4.2.0 (default) |
✗ |
Custom 4.1.0 |
4.2.0 |
Custom 4.1.0 |
4.2.0 |
✗ |
|
Note
|
Custom 4.1.0 refers to a custom user-provided container image built against Kafka 4.1.0.
Setting a custom image means you set the image property to a user-provided image.
The operator does not automatically change this value during upgrades.
|
Handling upgrades with custom images
When you set a custom image through the image property in a custom resource, you must keep the image and version in sync during upgrades.
The Cluster Operator does not automatically update images defined this way.
(This limitation does not apply when you use Kafka Connect Build or the default image mappings defined in the Cluster Operator environment variables.)
To avoid version mismatches when changing the Kafka version:
-
Pause reconciliation of the custom resource.
-
Upgrade the Cluster Operator to a release that supports a new Kafka version.
-
Update the custom resource:
-
Set
spec.*.versionto the target Kafka version -
Set
spec.*.imageto the custom image built for that version
-
-
Unpause the reconciliation.
If you don’t follow these steps, the operator might attempt to upgrade the resource before the correct image is specified, leading to mismatches.
Configuring the
image property in other resourcesFor the image property in the custom resources for other components, the given value is used during deployment.
If the image property is not set, the container image specified as an environment variable in the Cluster Operator configuration is used.
If an image name is not defined in the Cluster Operator configuration, then a default value is used.
For more information on image environment variables, see Configuring the Cluster Operator.
| Component | Environment variable | Default image |
|---|---|---|
Topic Operator |
|
|
User Operator |
|
|
Kafka Exporter |
|
|
Cruise Control |
|
|
HTTP Bridge |
|
|
Kafka initializer |
|
|
Example container image configuration
apiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
image: my-org/my-image:latest
# ...2.7. livenessProbe and readinessProbe healthchecks
Use the livenessProbe and readinessProbe properties to configure healthcheck probes supported in Strimzi.
Healthchecks are periodical tests which verify the health of an application. When a Healthcheck probe fails, Kubernetes assumes that the application is not healthy and attempts to fix it.
For more details about the probes, see Configure Liveness and Readiness Probes.
Both livenessProbe and readinessProbe support the following options:
-
initialDelaySeconds -
timeoutSeconds -
periodSeconds -
successThreshold -
failureThreshold
Example of liveness and readiness probe configuration
# ...
readinessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
livenessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
# ...For more information about the livenessProbe and readinessProbe options, see the Probe schema reference.
2.8. metricsConfig
Use the metricsConfig property to enable and configure Prometheus metrics.
Strimzi provides support for Prometheus JMX Exporter and Strimzi Metrics Reporter. Only one of these can be selected at any given time.
When metrics are enabled, they are exposed on port 9404.
When the metricsConfig property is not defined in the resource, the Prometheus metrics are not enabled.
For more information about setting up and deploying Prometheus and Grafana, see Introducing Metrics to Kafka.
Using Prometheus JMX Exporter
The metricsConfig property contains a reference to a ConfigMap that has additional configurations for the Prometheus JMX Exporter.
When configured to use Prometheus JMX Exporter, Strimzi converts the JMX metrics provided by Apache Kafka into a Prometheus-compatible format.
To enable Prometheus metrics export without further configuration, you can reference a ConfigMap containing an empty file under metricsConfig.valueFrom.configMapKeyRef.key.
When referencing an empty file, all metrics are exposed as long as they have not been renamed.
Example ConfigMap with metrics configuration for Kafka
kind: ConfigMap
apiVersion: v1
metadata:
name: my-configmap
data:
my-key: |
lowercaseOutputName: true
rules:
# Special cases and very specific rules
- pattern: kafka.server<type=(.+), name=(.+), clientId=(.+), topic=(.+), partition=(.*)><>Value
name: kafka_server_$1_$2
type: GAUGE
labels:
clientId: "$3"
topic: "$4"
partition: "$5"
# further configurationExample metrics configuration for Kafka
apiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
metricsConfig:
type: jmxPrometheusExporter
valueFrom:
configMapKeyRef:
name: my-config-map
key: my-key
# ...Using Strimzi Metrics Reporter
The metricsConfig property contains configurations for the Strimzi Metrics Reporter.
The Strimzi Metrics Reporter offers a lightweight solution for exposing Kafka metrics in Prometheus format, and avoiding complex mapping rules that can introduce latency.
To enable Strimzi Metrics Reporter, set the type to strimziMetricsReporter.
The allowList configuration is a comma-separated list of regex patterns to filter the metrics that are collected. This defaults to .*, which allows all metrics.
Changes to this field will not trigger rolling update, the configuration is dynamically updated for Kafka brokers and controllers.
|
Note
|
Using strimziMetricsReporter is only supported in the Kafka brokers and controllers at the moment.
|
Example metrics configuration for Kafka
apiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
metricsConfig:
type: strimziMetricsReporter
values:
allowList:
key: ".*"
# ...2.9. jvmOptions
The following Strimzi components run inside a Java Virtual Machine (JVM):
-
Apache Kafka
-
Apache Kafka Connect
-
Apache Kafka MirrorMaker
-
HTTP Bridge
To optimize their performance on different platforms and architectures, you configure the jvmOptions property in the following resources:
-
Kafka.spec.kafka -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.cruiseControl -
KafkaNodePool.spec -
KafkaConnect.spec -
KafkaMirrorMaker2.spec -
KafkaBridge.spec
You can specify the following options in your configuration:
-Xms-
Minimum initial allocation heap size when the JVM starts
-Xmx-
Maximum heap size
-XX-
Advanced runtime options for the JVM
javaSystemProperties-
Additional system properties
gcLoggingEnabled
|
Note
|
The units accepted by JVM settings, such as -Xmx and -Xms, are the same units accepted by the JDK java binary in the corresponding image.
Therefore, 1g or 1G means 1,073,741,824 bytes, and Gi is not a valid unit suffix.
This is different from the units used for memory requests and limits, which follow the Kubernetes convention where 1G means 1,000,000,000 bytes, and 1Gi means 1,073,741,824 bytes.
|
-Xms and -Xmx optionsIn addition to setting memory request and limit values for your containers, you can use the -Xms and -Xmx JVM options to set specific heap sizes for your JVM.
Use the -Xms option to set an initial heap size and the -Xmx option to set a maximum heap size.
Specify heap size to have more control over the memory allocated to your JVM. Heap sizes should make the best use of a container’s memory limit (and request) without exceeding it. Heap size and any other memory requirements need to fit within a specified memory limit. If you don’t specify heap size in your configuration, but you configure a memory resource limit (and request), the Cluster Operator imposes default heap sizes automatically. The Cluster Operator sets default maximum and minimum heap values based on a percentage of the memory resource configuration.
The following table shows the default heap values.
| Component | Percent of available memory allocated to the heap | Maximum limit |
|---|---|---|
Kafka |
50% |
5 GB |
Kafka Connect |
75% |
None |
MirrorMaker 2 |
75% |
None |
MirrorMaker |
75% |
None |
Cruise Control |
75% |
None |
HTTP Bridge |
50% |
31 Gi |
If a memory limit (and request) is not specified, a JVM’s minimum heap size is set to 128M.
The JVM’s maximum heap size is not defined to allow the memory to increase as needed.
This is ideal for single node environments in test and development.
Setting an appropriate memory request can prevent the following:
-
Kubernetes killing a container if there is pressure on memory from other pods running on the node.
-
Kubernetes scheduling a container to a node with insufficient memory. If
-Xmsis set to-Xmx, the container will crash immediately; if not, the container will crash at a later time.
In this example, the JVM uses 2 GiB (=2,147,483,648 bytes) for its heap. Total JVM memory usage can be a lot more than the maximum heap size.
Example
-Xmx and -Xms configuration# ...
jvmOptions:
"-Xmx": "2g"
"-Xms": "2g"
# ...Setting the same value for initial (-Xms) and maximum (-Xmx) heap sizes avoids the JVM having to allocate memory after startup, at the cost of possibly allocating more heap than is really needed.
|
Important
|
Containers performing lots of disk I/O, such as Kafka broker containers, require available memory for use as an operating system page cache. For such containers, the requested memory should be significantly higher than the memory used by the JVM. |
-XX option
-XX options are used to configure the KAFKA_JVM_PERFORMANCE_OPTS option of Apache Kafka.
Example
-XX configurationjvmOptions:
"-XX":
"UseG1GC": "true"
"MaxGCPauseMillis": "20"
"InitiatingHeapOccupancyPercent": "35"
"ExplicitGCInvokesConcurrent": "true"JVM options resulting from the
-XX configuration-XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -XX:-UseParNewGC|
Note
|
When no -XX options are specified, the default Apache Kafka configuration of KAFKA_JVM_PERFORMANCE_OPTS is used.
|
javaSystemPropertiesjavaSystemProperties are used to configure additional Java system properties, such as debugging utilities.
Example
javaSystemProperties configurationjvmOptions:
javaSystemProperties:
- name: javax.net.debug
value: sslFor more information about the jvmOptions, see the JvmOptions schema reference.
2.10. Garbage collector logging
The jvmOptions property also allows you to enable and disable garbage collector (GC) logging.
GC logging is disabled by default.
To enable it, set the gcLoggingEnabled property as follows:
Example GC logging configuration
# ...
jvmOptions:
gcLoggingEnabled: true
# ...2.11. Additional volumes
Strimzi supports specifying additional volumes and volume mounts in the following components:
-
Kafka
-
Kafka Connect
-
HTTP Bridge
-
Kafka MirrorMaker2
-
Entity Operator
-
Cruise Control
-
Kafka Exporter
-
User Operator
-
Topic Operator
All additional mounted paths are located inside /mnt to ensure compatibility with future Kafka and Strimzi updates.
Supported Volume Types
-
Secret
-
ConfigMap
-
EmptyDir
-
PersistentVolumeClaims
-
CSI Volumes
-
Image Volumes
Example configuration for additional volumes
kind: Kafka
spec:
kafka:
# ...
template:
pod:
volumes:
- name: example-secret
secret:
secretName: secret-name
- name: example-configmap
configMap:
name: config-map-name
- name: temp
emptyDir: {}
- name: example-pvc-volume
persistentVolumeClaim:
claimName: myclaim
- name: example-csi-volume
csi:
driver: csi.cert-manager.io
readOnly: true
volumeAttributes:
csi.cert-manager.io/issuer-name: my-ca
csi.cert-manager.io/dns-names: ${POD_NAME}.${POD_NAMESPACE}.svc.cluster.local
- name: example-oci-plugin
image:
reference: my-registry.io/oci-artifacts/example-plugin:latest
kafkaContainer:
volumeMounts:
- name: example-secret
mountPath: /mnt/secret-volume
- name: example-configmap
mountPath: /mnt/cm-volume
- name: temp
mountPath: /mnt/temp
- name: example-pvc-volume
mountPath: /mnt/data
- name: example-csi-volume
mountPath: /mnt/certificate
- name: example-oci-plugin
mountPath: /mnt/example-pluginYou can use volumes to store files containing configuration values for a Kafka component and then load those values using a configuration provider. For more information, see Loading configuration values from external sources.
You can also use additional volumes to mount custom plugins:
-
To include custom plugins in the User Operator and Topic Operator, set the
JAVA_CLASSPATHenvironment variable to modify the Java classpath. -
To include custom plugins in the Kafka operands and Cruise Control, set the
CLASSPATHenvironment variable to modify the Java classpath. -
To add Kafka Connect connectors, see Adding Kafka Connect connectors.
-
Some plugins, such as the Tiered Storage plugins, may require their own classpath configuration.
3. Kafka schema reference
| Property | Property type | Description |
|---|---|---|
spec |
The specification of the Kafka cluster. |
|
status |
The status of the Kafka cluster. |
4. KafkaSpec schema reference
Used in: Kafka
| Property | Property type | Description |
|---|---|---|
kafka |
Configuration of the Kafka cluster. |
|
entityOperator |
Configuration of the Entity Operator. |
|
clusterCa |
Configuration of the cluster certificate authority. |
|
clientsCa |
Configuration of the clients certificate authority. |
|
cruiseControl |
Configuration for Cruise Control deployment. Deploys a Cruise Control instance when specified. |
|
kafkaExporter |
Configuration of the Kafka Exporter. Kafka Exporter can provide additional metrics, for example lag of consumer group at topic/partition. |
|
maintenanceTimeWindows |
string array |
A list of time windows for maintenance tasks (that is, certificates renewal). Each time window is defined by a cron expression. |
5. KafkaClusterSpec schema reference
Used in: KafkaSpec
Configures a Kafka cluster using the Kafka custom resource.
The config properties are one part of the overall configuration for the resource.
Use the config properties to configure Kafka broker options as keys.
Example Kafka configuration
apiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
version: 4.2.0
metadataVersion: 4.2
# ...
config:
auto.create.topics.enable: "false"
offsets.topic.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 2
default.replication.factor: 3
min.insync.replicas: 2
# ...The values can be one of the following JSON types:
-
String
-
Number
-
Boolean
Exceptions
You can specify and configure the options listed in the Kafka broker configuration documentation.
However, Strimzi takes care of configuring and managing options related to the following, which cannot be changed:
-
Security (encryption, authentication, and authorization)
-
Listener configuration
-
Broker ID configuration
-
Configuration of log data directories
-
Inter-broker communication
Properties with the following prefixes cannot be set:
-
advertised. -
authorizer. -
broker. -
controller -
cruise.control.metrics.reporter.bootstrap. -
cruise.control.metrics.topic -
host.name -
inter.broker.listener.name -
listener. -
listeners. -
log.dir -
password. -
port -
process.roles -
sasl. -
security. -
servers,node.id -
ssl. -
super.user
|
Note
|
Strimzi supports only KRaft-based Kafka deployments. As a result, ZooKeeper-related configuration options are not supported. |
If the config property contains an option that cannot be changed, it is disregarded, and a warning message is logged to the Cluster Operator log file.
All other supported options are forwarded to Kafka, including the following exceptions to the options configured by Strimzi:
-
Any
sslconfiguration for supported TLS versions and cipher suites -
Cruise Control metrics properties:
-
cruise.control.metrics.topic.num.partitions -
cruise.control.metrics.topic.replication.factor -
cruise.control.metrics.topic.retention.ms -
cruise.control.metrics.topic.auto.create.retries -
cruise.control.metrics.topic.auto.create.timeout.ms -
cruise.control.metrics.topic.min.insync.replicas
-
-
Controller properties:
-
controller.quorum.election.backoff.max.ms -
controller.quorum.election.timeout.ms -
controller.quorum.fetch.timeout.ms
-
-
Listener properties (which are configured in the following format:
listener.name.listener1-9900.connections.max.reauth.mswherelistener1-9900is the listener name and port joined by-):-
connections.max.reauth.ms -
max.connections -
max.connections.per.ip -
max.connections.per.ip.overrides -
max.connection.creation.rate
-
5.1. Configuring topology-label-based rack awareness and init container images
Rack awareness is enabled using the rack property.
When topology-label-based rack awareness is enabled, Kafka broker pods use an init container to collect labels from Kubernetes nodes.
|
Note
|
Environment-variable-based rack awareness does not require an init container, and therefore does not use the brokerRackInitImage image.
|
The container image for this init container can be specified using the brokerRackInitImage property.
If the brokerRackInitImage field is not provided, the images used are prioritized as follows:
-
Container image specified in
STRIMZI_DEFAULT_KAFKA_INIT_IMAGEenvironment variable in the Cluster Operator configuration. -
quay.io/strimzi/operator:1.0.1container image.
Example
brokerRackInitImage configurationapiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
rack:
type: topology-label
topologyKey: topology.kubernetes.io/zone
brokerRackInitImage: my-org/my-image:latest
# ...|
Note
|
Overriding container images is recommended only in special situations, such as when your network does not allow access to the container registry used by Strimzi. In such cases, you should either copy the Strimzi images or build them from the source. Be aware that if the configured image is not compatible with Strimzi images, it might not work properly. |
5.2. Logging
Kafka has its own preconfigured loggers:
| Logger | Description | Default Level |
|---|---|---|
|
Default logger for all classes |
INFO |
|
Logs Kafka node classes |
INFO |
|
Logs Kafka library classes |
INFO |
|
Logs client request details |
WARN |
|
Logs request handling in the broker |
WARN |
|
Logs controller activity, such as leadership changes |
INFO |
|
Logs log compaction and cleanup processes |
INFO |
|
Logs broker and partition state transitions |
INFO |
|
Logs access control decisions |
INFO |
Kafka uses the Apache log4j2 logger implementation.
Use the logging property to configure loggers and logger levels.
You can set log levels using either the inline or external logging configuration types.
Specify loggers and levels directly in the custom resource for inline configuration:
Example inline logging configuration
apiVersion: kafka.strimzi.io/v1
kind: Kafka
spec:
# ...
kafka:
# ...
logging:
type: inline
loggers:
rootLogger.level: INFO
logger.kafka.level: DEBUG
logger.logcleaner.level: DEBUG
logger.authorizer.level: TRACE
# ...You can define additional loggers by specifying the full class or package name using logger.<name>.name.
For example, to configure logging for OAuth components inline:
Example custom inline loggers
# ...
logger.oauth.name: io.strimzi.kafka.oauth # (1)
logger.oauth.level: DEBUG # (2)-
Creates a logger for the
io.strimzi.kafka.oauthpackage. -
Sets the logging level for the OAuth package.
Alternatively, you can reference an external ConfigMap containing a complete log4j2.properties file that defines your own log4j2 configuration, including loggers, appenders, and layout configuration:
Example external logging configuration
apiVersion: kafka.strimzi.io/v1
kind: Kafka
spec:
# ...
logging:
type: external
valueFrom:
configMapKeyRef:
# name and key are mandatory
name: customConfigMap
key: log4j2.properties
# ...Garbage collector (GC)
Garbage collector logging can also be enabled (or disabled) using the jvmOptions property.
5.3. Rack awareness
The rack option configures rack awareness.
A rack can represent an availability zone, data center, or an actual rack in your data center.
The rack can be configured in two different ways:
-
Based on a topology label of the Kubernetes worker node
-
Based on a user-configured environment variable
5.3.1. Spreading partition replicas across racks
When rack awareness is configured, Strimzi will set broker.rack configuration for each Kafka broker.
The broker.rack configuration assigns a rack ID to each broker.
When broker.rack is configured, Kafka brokers will spread partition replicas across as many different racks as possible.
When replicas are spread across multiple racks, the probability that multiple replicas will fail at the same time is lower than if they would be in the same rack.
Spreading replicas improves resiliency, and is important for availability and reliability.
To enable rack awareness in Kafka, add the rack option to the .spec.kafka section of the Kafka custom resource as shown in the example below.
|
Note
|
The rack in which brokers run can change when pods are deleted or restarted.
As a result, replicas that were running in different racks might then share the same rack.
Use Cruise Control and the KafkaRebalance resource and the RackAwareGoal to make sure that replicas remain distributed across different racks.
|
5.3.2. Consuming messages from the closest replicas
Rack awareness can also be used in consumers to fetch data from the closest replica. This is useful for reducing the load on your network when a Kafka cluster spans multiple datacenters and can also reduce costs when running Kafka in public clouds. However, it can lead to increased latency.
In order to be able to consume from the closest replica, rack awareness has to be configured in the Kafka cluster, and the RackAwareReplicaSelector has to be enabled.
The replica selector plugin provides the logic that enables clients to consume from the nearest replica.
The default implementation uses LeaderSelector to always select the leader replica for the client.
Specify RackAwareReplicaSelector for the replica.selector.class to switch from the default implementation.
Example
rack configuration with enabled replica-aware selectorapiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
rack:
type: topology-label
topologyKey: topology.kubernetes.io/zone
config:
# ...
replica.selector.class: org.apache.kafka.common.replica.RackAwareReplicaSelector
# ...In addition to the Kafka broker configuration, you also need to specify the client.rack option in your consumers.
The client.rack option should specify the rack ID in which the consumer is running.
RackAwareReplicaSelector associates matching broker.rack and client.rack IDs, to find the nearest replica and consume from it.
If there are multiple replicas in the same rack, RackAwareReplicaSelector always selects the most up-to-date replica.
If the rack ID is not specified, or if it cannot find a replica with the same rack ID, it will fall back to the leader replica.
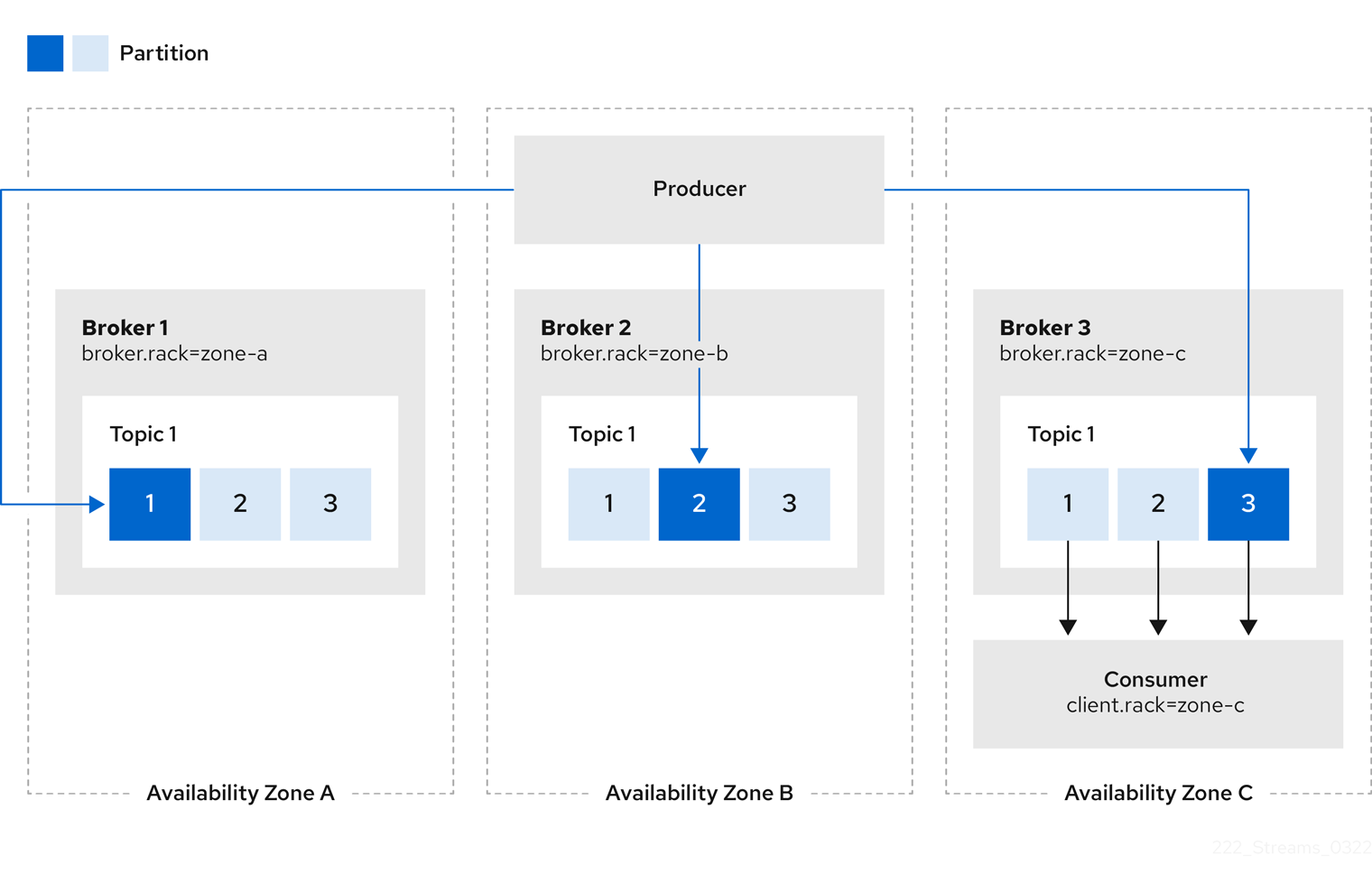
Figure 1. Example showing client consuming from replicas in the same availability zone
You can also configure Kafka Connect, MirrorMaker 2 and HTTP Bridge so that connectors consume messages from the closest replicas.
You enable rack awareness in the KafkaConnect, KafkaMirrorMaker2, and KafkaBridge custom resources.
The configuration does does not set affinity rules, but you can also configure affinity or topologySpreadConstraints.
For more information see Configuring pod scheduling.
When deploying Kafka Connect using Strimzi, you can use the rack section in the KafkaConnect custom resource to automatically configure the client.rack option.
Example
rack configuration for Kafka ConnectapiVersion: kafka.strimzi.io/v1
kind: KafkaConnect
# ...
spec:
# ...
rack:
type: topology-label
topologyKey: topology.kubernetes.io/zone
# ...When deploying MirrorMaker 2 using Strimzi, you can use the rack section in the KafkaMirrorMaker2 custom resource to automatically configure the client.rack option.
Example
rack configuration for MirrorMaker 2apiVersion: kafka.strimzi.io/v1
kind: KafkaMirrorMaker2
# ...
spec:
# ...
rack:
type: topology-label
topologyKey: topology.kubernetes.io/zone
# ...When deploying HTTP Bridge using Strimzi, you can use the rack section in the KafkaBridge custom resource to automatically configure the client.rack option.
Example
rack configuration for HTTP BridgeapiVersion: kafka.strimzi.io/v1
kind: KafkaBridge
# ...
spec:
# ...
rack:
type: topology-label
topologyKey: topology.kubernetes.io/zone
# ...5.4. KafkaClusterSpec schema properties
| Property | Property type | Description |
|---|---|---|
version |
string |
The Kafka broker version. Defaults to the latest version. Consult the user documentation to understand the process required to upgrade or downgrade the version. |
metadataVersion |
string |
Added in Strimzi 0.39.0. The KRaft metadata version used by the Kafka cluster. This property is ignored when running in ZooKeeper mode. If the property is not set, it defaults to the metadata version that corresponds to the |
image |
string |
The container image used for Kafka pods. If the property is not set, the default Kafka image version is determined based on the |
listeners |
|
Configures listeners to provide access to Kafka brokers. |
config |
map |
Kafka broker config properties with certain prefixes cannot be set unless it is in the exception list. Consult the documentation for the list of forbidden prefixes and exceptions. |
authorization |
Authorization configuration for Kafka brokers. |
|
rack |
Configuration of the |
|
brokerRackInitImage |
string |
The image of the init container used for initializing the |
livenessProbe |
Pod liveness checking. |
|
readinessProbe |
Pod readiness checking. |
|
jvmOptions |
JVM Options for pods. |
|
jmxOptions |
JMX Options for Kafka brokers. |
|
metricsConfig |
Metrics configuration. |
|
logging |
Logging configuration for Kafka. |
|
template |
Template for Kafka cluster resources. The template allows users to specify how the Kubernetes resources are generated. |
|
tieredStorage |
Configure the tiered storage feature for Kafka brokers. |
|
quotas |
Quotas plugin configuration for Kafka brokers allows setting quotas for disk usage, produce/fetch rates, and more. Supported plugin types include |
6. GenericKafkaListener schema reference
Used in: KafkaClusterSpec
Configures listeners to connect to Kafka brokers within and outside Kubernetes.
Configure Kafka broker listeners using the listeners property in the Kafka resource.
Listeners are defined as an array.
Example
Kafka resource showing listener configurationapiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
#...
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
authentication:
type: tls
- name: external1
port: 9094
type: route
tls: true
- name: external2
port: 9095
type: ingress
tls: true
authentication:
type: tls
configuration:
bootstrap:
host: bootstrap.myingress.com
brokers:
- broker: 0
host: broker-0.myingress.com
- broker: 1
host: broker-1.myingress.com
- broker: 2
host: broker-2.myingress.com
#...The name and port must be unique within the Kafka cluster. By specifying a unique name and port for each listener, you can configure multiple listeners. The name can be up to 25 characters long, comprising lower-case letters and numbers.
6.1. Specifying a port number
The port number is the port used in the Kafka cluster, which might not be the same port used for access by a client.
-
loadbalancerlisteners use the specified port number, as dointernalandcluster-iplisteners -
ingressandroutelisteners use port 443 for access -
nodeportlisteners use the port number assigned by Kubernetes
For client connection, use the address and port for the bootstrap service of the listener.
You can retrieve this from the status of the Kafka resource.
Example command to retrieve the address and port for client connection
kubectl get kafka <kafka_cluster_name> -o=jsonpath='{.status.listeners[?(@.name=="<listener_name>")].bootstrapServers}{"\n"}'|
Important
|
When configuring listeners for client access to brokers, you can use port 9092 or higher (9093, 9094, and so on), but with a few exceptions. The listeners cannot be configured to use the ports reserved for interbroker communication (9090 and 9091), Prometheus metrics (9404), and JMX (Java Management Extensions) monitoring (9999). |
6.2. Specifying listener types
Set the type to internal for internal listeners.
For external listeners, choose from route, loadbalancer, nodeport, or ingress.
You can also configure a cluster-ip listener, which is an internal type used for building custom access mechanisms.
- internal
-
You can configure internal listeners with or without encryption using the
tlsproperty.Exampleinternallistener configuration#... spec: kafka: #... listeners: #... - name: plain port: 9092 type: internal tls: false - name: tls port: 9093 type: internal tls: true authentication: type: tls #... - route
-
Configures an external listener to expose Kafka using OpenShift
Routesand the HAProxy router.A dedicated
Routeis created for every Kafka broker pod. An additionalRouteis created to serve as a Kafka bootstrap address. Kafka clients can use theseRoutesto connect to Kafka on port 443. The client connects on port 443, the default router port, but traffic is then routed to the port you configure, which is9094in this example.Exampleroutelistener configuration#... spec: kafka: #... listeners: #... - name: external1 port: 9094 type: route tls: true #... - ingress
-
Configures an external listener to expose Kafka using Kubernetes
Ingressand the Ingress NGINX Controller for Kubernetes.ImportantThe ingresslistener type is deprecated because the Ingress NGINX Controller for Kubernetes has been archived since March 2026. Although the related code remains in the Strimzi codebase, it is no longer maintained, and no further enhancements or development are planned.A dedicated
Ingressresource is created for every Kafka broker pod. An additionalIngressresource is created to serve as a Kafka bootstrap address. Kafka clients can use theseIngressresources to connect to Kafka on port 443. The client connects on port 443, the default controller port, but traffic is then routed to the port you configure, which is9095in the following example.You must specify the hostname used by the bootstrap service using
GenericKafkaListenerConfigurationBootstrapproperty. And you must also specify the hostnames used by the per-broker services usingGenericKafkaListenerConfigurationBrokerorhostTemplateproperties. With thehostTemplateproperty, you don’t need to specify the configuration for every broker.Exampleingresslistener configuration#... spec: kafka: #... listeners: #... - name: external2 port: 9095 type: ingress tls: true authentication: type: tls configuration: hostTemplate: broker-{nodeId}.myingress.com bootstrap: host: bootstrap.myingress.com #...NoteExternal listeners using Ingressare currently only tested with the Ingress NGINX Controller for Kubernetes. - loadbalancer
-
Configures an external listener to expose Kafka using a
LoadbalancertypeService.A new loadbalancer service is created for every Kafka broker pod. An additional loadbalancer is created to serve as a Kafka bootstrap address. Loadbalancers listen to the specified port number, which is port
9094in the following example.You can use the
loadBalancerSourceRangesproperty to configure source ranges to restrict access to the specified IP addresses.Exampleloadbalancerlistener configuration#... spec: kafka: #... listeners: - name: external3 port: 9094 type: loadbalancer tls: true configuration: loadBalancerSourceRanges: - 10.0.0.0/8 - 88.208.76.87/32 #... - nodeport
-
Configures an external listener to expose Kafka using a
NodePorttypeService.Kafka clients connect directly to the nodes of Kubernetes. An additional
NodePorttype of service is created to serve as a Kafka bootstrap address.When configuring the advertised addresses for the Kafka broker pods, Strimzi uses the address of the node on which the given pod is running.
You can use
preferredNodePortAddressTypeproperty to configure the first address type checked as the node address.Examplenodeportlistener configuration#... spec: kafka: #... listeners: #... - name: external4 port: 9095 type: nodeport tls: false configuration: preferredNodePortAddressType: InternalDNS #...NoteTLS hostname verification is not currently supported when exposing Kafka clusters using node ports. - cluster-ip
-
Configures an internal listener to expose Kafka using a per-broker
ClusterIPtypeService.The listener does not use a headless service and its DNS names to route traffic to Kafka brokers. You can use this type of listener to expose a Kafka cluster when using the headless service is unsuitable. You might use it with a custom access mechanism, such as one that uses a specific Ingress controller or the Kubernetes Gateway API.
A new
ClusterIPservice is created for each Kafka broker pod. The service is assigned aClusterIPaddress to serve as a Kafka bootstrap address with a per-broker port number. For example, you can configure the listener to expose a Kafka cluster over an Nginx Ingress Controller with TCP port configuration.Examplecluster-iplistener configuration#... spec: kafka: #... listeners: - name: clusterip type: cluster-ip tls: false port: 9096 #...
6.3. Configuring network policies to restrict listener access
Use networkPolicyPeers to configure network policies that restrict access to a listener at the network level.
The following example shows a networkPolicyPeers configuration for a plain and a tls listener.
In the following example:
-
Only application pods matching the labels
app: kafka-sasl-consumerandapp: kafka-sasl-producercan connect to theplainlistener. The application pods must be running in the same namespace as the Kafka broker. -
Only application pods running in namespaces matching the labels
project: myprojectandproject: myproject2can connect to thetlslistener.
The syntax of the networkPolicyPeers property is the same as the from property in NetworkPolicy resources.
Example network policy configuration
listeners:
#...
- name: plain
port: 9092
type: internal
tls: true
authentication:
type: scram-sha-512
networkPolicyPeers:
- podSelector:
matchLabels:
app: kafka-sasl-consumer
- podSelector:
matchLabels:
app: kafka-sasl-producer
- name: tls
port: 9093
type: internal
tls: true
authentication:
type: tls
networkPolicyPeers:
- namespaceSelector:
matchLabels:
project: myproject
- namespaceSelector:
matchLabels:
project: myproject2
# ...6.4. GenericKafkaListener schema properties
| Property | Property type | Description |
|---|---|---|
name |
string |
Name of the listener. The name will be used to identify the listener and the related Kubernetes objects. The name has to be unique within given a Kafka cluster. The name can consist of lowercase characters and numbers and be up to 11 characters long. |
port |
integer |
Port number used by the listener inside Kafka. The port number has to be unique within a given Kafka cluster. Allowed port numbers are 9092 and higher with the exception of ports 9404 and 9999, which are already used for Prometheus and JMX. Depending on the listener type, the port number might not be the same as the port number that connects Kafka clients. |
type |
string (one of [ingress, internal, route, loadbalancer, cluster-ip, nodeport]) |
Type of the listener. The supported types are as follows:
|
tls |
boolean |
Enables TLS encryption on the listener. This is a required property. For |
authentication |
|
Authentication configuration for this listener. |
configuration |
Additional listener configuration. |
|
networkPolicyPeers |
NetworkPolicyPeer array |
List of peers which should be able to connect to this listener. Peers in this list are combined using a logical OR operation. If this field is empty or missing, all connections will be allowed for this listener. If this field is present and contains at least one item, the listener only allows the traffic which matches at least one item in this list. |
7. KafkaListenerAuthenticationTls schema reference
Used in: GenericKafkaListener
The type property is a discriminator that distinguishes use of the KafkaListenerAuthenticationTls type from KafkaListenerAuthenticationScramSha512, KafkaListenerAuthenticationCustom.
It must have the value tls for the type KafkaListenerAuthenticationTls.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
8. KafkaListenerAuthenticationScramSha512 schema reference
Used in: GenericKafkaListener
The type property is a discriminator that distinguishes use of the KafkaListenerAuthenticationScramSha512 type from KafkaListenerAuthenticationTls, KafkaListenerAuthenticationCustom.
It must have the value scram-sha-512 for the type KafkaListenerAuthenticationScramSha512.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
9. KafkaListenerAuthenticationCustom schema reference
Used in: GenericKafkaListener
Configures custom authentication for listeners.
To configure custom authentication, set the type property to custom.
Custom authentication allows for any type of Kafka-supported authentication to be used.
Example custom OAuth authentication configuration
spec:
kafka:
config:
principal.builder.class: SimplePrincipal.class
listeners:
- name: oauth-bespoke
port: 9093
type: internal
tls: true
authentication:
type: custom
sasl: true
listenerConfig:
oauthbearer.sasl.client.callback.handler.class: client.class
oauthbearer.sasl.server.callback.handler.class: server.class
oauthbearer.sasl.login.callback.handler.class: login.class
oauthbearer.connections.max.reauth.ms: 999999999
sasl.enabled.mechanisms: oauthbearer
oauthbearer.sasl.jaas.config: |
org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required ;
template:
pod:
volumes:
- name: example-secret
secret:
secretName: example
kafkaContainer:
volumeMounts:
- name: example-secret
mountPath: /mnt/secret-volumeA protocol map is generated that uses the sasl and tls values to determine which protocol to map to the listener.
-
SASL = True, TLS = True → SASL_SSL
-
SASL = False, TLS = True → SSL
-
SASL = True, TLS = False → SASL_PLAINTEXT
-
SASL = False, TLS = False → PLAINTEXT
Secrets are mounted to the /mnt directory in the Kafka broker nodes' containers.
For example, the mounted secret (example) in the example configuration would be located at /mnt/secret-volume.
9.1. Configuring customized TLS Client Authentication
You can also use the custom authentication to configure customized TLS client authentication.
This allows configuration options that are not permissible with type: tls authentication.
For example, it’s possible to configure a custom truststore with multiple trusted CAs or options such as ssl.principal.mapping.rules.
Example custom TLS Client Authentication configuration
spec:
kafka:
listeners:
- name: tls
port: 9093
tls: true
type: internal
authentication:
type: custom
sasl: false
listenerConfig:
ssl.client.auth: required
ssl.principal.mapping.rules: RULE:^CN=(.*?),(.*)$/$1@my-cluster.com/
ssl.truststore.location: /mnt/my-truststore/ca.crt
ssl.truststore.type: PEM
template:
pod:
volumes:
- name: my-truststore
secret:
secretName: custom-truststore
kafkaContainer:
volumeMounts:
- name: my-truststore
mountPath: /mnt/my-truststore9.2. Setting a custom principal builder
You can set a custom principal builder in the Kafka cluster configuration. However, the principal builder is subject to the following requirements:
-
The specified principal builder class must exist on the image. Before building your own, check if one already exists. You’ll need to rebuild the Strimzi images with the required classes.
-
No other listener is using
oauthtype authentication. This is because an OAuth listener appends its own principle builder to the Kafka configuration. -
The specified principal builder is compatible with Strimzi.
Custom principal builders must support peer certificates for authentication, as Strimzi uses these to manage the Kafka cluster.
A custom OAuth principal builder might be identical or very similar to the Strimzi OAuth principal builder.
|
Note
|
Kafka’s default principal builder class supports the building of principals based on the names of peer certificates.
The custom principal builder should provide a principal of type user using the name of the SSL peer certificate.
|
The following example shows a custom principal builder that satisfies the OAuth requirements of Strimzi.
Example principal builder for custom OAuth configuration
public final class CustomKafkaPrincipalBuilder implements KafkaPrincipalBuilder {
public KafkaPrincipalBuilder() {}
@Override
public KafkaPrincipal build(AuthenticationContext context) {
if (context instanceof SslAuthenticationContext) {
SSLSession sslSession = ((SslAuthenticationContext) context).session();
try {
return new KafkaPrincipal(
KafkaPrincipal.USER_TYPE, sslSession.getPeerPrincipal().getName());
} catch (SSLPeerUnverifiedException e) {
throw new IllegalArgumentException("Cannot use an unverified peer for authentication", e);
}
}
// Create your own KafkaPrincipal here
...
}
}9.3. KafkaListenerAuthenticationCustom schema properties
The type property is a discriminator that distinguishes use of the KafkaListenerAuthenticationCustom type from KafkaListenerAuthenticationTls, KafkaListenerAuthenticationScramSha512.
It must have the value custom for the type KafkaListenerAuthenticationCustom.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
sasl |
boolean |
Enable or disable SASL on this listener. |
listenerConfig |
map |
Configuration to be used for a specific listener. All values are prefixed with |
10. GenericKafkaListenerConfiguration schema reference
Used in: GenericKafkaListener
Configures Kafka listeners.
10.1. Providing your own listener certificates
The brokerCertChainAndKey property is for listeners that have TLS encryption enabled only.
Use this property to provide your own Kafka listener certificates.
Example
loadbalancer listener configuration to provide certificateslisteners:
#...
- name: external3
port: 9094
type: loadbalancer
tls: true
configuration:
brokerCertChainAndKey:
secretName: my-secret
certificate: my-listener-certificate.crt
key: my-listener-key.key
# ...When the certificate or key in the brokerCertChainAndKey secret is updated, the operator automatically detects it in the next reconciliation and triggers a rolling update of the Kafka brokers to reload the certificate.
|
Note
|
The private key referenced in brokerCertChainAndKey must be in an unencrypted PKCS #8 format. If you obtain the certificate is obtained using the cert-manager project, you can set key encoding to use PKCS#8.
|
10.2. Avoiding hops to other nodes
The externalTrafficPolicy property is used with loadbalancer and nodeport listeners.
When exposing Kafka outside of Kubernetes, you can choose Local or Cluster.
Local avoids hops to other nodes and preserves the client IP, whereas Cluster does neither.
The default is Cluster.
Example
loadbalancer listener configuration avoiding hopslisteners:
#...
- name: external3
port: 9094
type: loadbalancer
tls: true
configuration:
externalTrafficPolicy: Local
# ...10.3. Providing CIDR source ranges for a loadbalancer
The loadBalancerSourceRanges property is for loadbalancer listeners only.
When exposing Kafka outside of Kubernetes, use CIDR (Classless Inter-Domain Routing) source ranges in addition to labels and annotations to customize how a service is created.
Example
loadbalancer listener configuration to provide source rangeslisteners:
#...
- name: external3
port: 9094
type: loadbalancer
tls: true
configuration:
loadBalancerSourceRanges:
- 10.0.0.0/8
- 88.208.76.87/32
# ...10.4. Specifying a preferred node port address type
The preferredNodePortAddressType property is for nodeport listeners only.
Use this property in your listener configuration to specify the first address type checked as the node address.
This property is useful, for example, if your deployment does not have DNS support or you only want to expose a broker internally through an internal DNS or IP address.
If an address of this type is found, it is used. If the preferred address type is not found, Strimzi proceeds through the types in the standard order of priority:
-
ExternalDNS
-
ExternalIP
-
Hostname
-
InternalDNS
-
InternalIP
Example
nodeport listener using a preferred node port address typelisteners:
#...
- name: external4
port: 9094
type: nodeport
tls: false
configuration:
preferredNodePortAddressType: InternalDNS
# ...10.5. Using fully-qualified DNS names
The useServiceDnsDomain property is for internal and cluster-ip listeners.
It defines whether the fully-qualified DNS names that include the cluster service suffix (usually .cluster.local) are used.
-
Set to
false(default) to generate advertised addresses without the service suffix; for example,my-cluster-kafka-0.my-cluster-kafka-brokers.myproject.svc. -
Set to
trueto generate advertised addresses with the service suffix; for example,my-cluster-kafka-0.my-cluster-kafka-brokers.myproject.svc.cluster.local.
Example
internal listener using the service DNS domainlisteners:
#...
- name: plain
port: 9092
type: internal
tls: false
configuration:
useServiceDnsDomain: true
# ...10.6. Specifying the hostname
To specify the hostname used for the bootstrap resource or brokers, use the host property.
The host property is for route and ingress listeners only.
A host property value is mandatory for ingress listener configuration, as the Ingress controller does not assign any hostnames automatically.
Make sure that the hostname resolves to the Ingress endpoints.
Strimzi will not perform any validation to ensure that the requested hosts are available and properly routed to the Ingress endpoints.
Example
ingress listener with host configurationlisteners:
#...
- name: external2
port: 9094
type: ingress
tls: true
configuration:
bootstrap:
host: bootstrap.myingress.com
brokers:
- broker: 0
host: broker-0.myingress.com
- broker: 1
host: broker-1.myingress.com
- broker: 2
host: broker-2.myingress.com
# ...By default, route listener hosts are automatically assigned by OpenShift. However, you can override the assigned route hosts by specifying hosts.
Strimzi does not perform any validation to ensure that the requested hosts are available. You must ensure that they are free and can be used.
Example
route listener with host configuration# ...
listeners:
#...
- name: external1
port: 9094
type: route
tls: true
configuration:
bootstrap:
host: bootstrap.myrouter.com
brokers:
- broker: 0
host: broker-0.myrouter.com
- broker: 1
host: broker-1.myrouter.com
- broker: 2
host: broker-2.myrouter.com
# ...Instead of specifying the host property for every broker, you can also use a hostTemplate to generate them automatically.
The hostTemplate supports the following variables:
-
The
{nodeId}variable is replaced with the ID of the Kafka node to which the template is applied. -
The
{nodePodName}variable is replaced with the Kubernetes pod name for the Kafka node where the template is applied.
The hostTemplate property applies only to per-broker values.
The bootstrap host property must always be specified.
Example
ingress listener with hostTemplate configuration#...
spec:
kafka:
#...
listeners:
#...
- name: external2
port: 9095
type: ingress
tls: true
authentication:
type: tls
configuration:
hostTemplate: broker-{nodeId}.myingress.com
bootstrap:
host: bootstrap.myingress.com
#...10.7. Overriding assigned node ports
By default, the port numbers used for the bootstrap and broker services are automatically assigned by Kubernetes.
You can override the assigned node ports for nodeport listeners by specifying the desired port numbers.
Strimzi does not perform any validation on the requested ports. You must ensure that they are free and available for use.
Example
nodeport listener configuration with overrides for node ports# ...
listeners:
#...
- name: external4
port: 9094
type: nodeport
tls: true
configuration:
bootstrap:
nodePort: 32100
brokers:
- broker: 0
nodePort: 32000
- broker: 1
nodePort: 32001
- broker: 2
nodePort: 32002
# ...10.8. Requesting a specific loadbalancer IP address
Use the loadBalancerIP property to request a specific IP address when creating a loadbalancer.
This property is useful when you need to use a loadbalancer with a specific IP address.
The loadBalancerIP property is ignored if the cloud provider does not support this feature.
Example
loadbalancer listener with specific IP addresses# ...
listeners:
#...
- name: external3
port: 9094
type: loadbalancer
tls: true
configuration:
bootstrap:
loadBalancerIP: 172.29.3.10
brokers:
- broker: 0
loadBalancerIP: 172.29.3.1
- broker: 1
loadBalancerIP: 172.29.3.2
- broker: 2
loadBalancerIP: 172.29.3.3
# ...10.9. Adding listener annotations to Kubernetes resources
Use the annotations property to add annotations to Kubernetes resources related to the listeners.
These annotations can be used, for example, to instrument DNS tooling such as External DNS, which automatically assigns DNS names to the loadbalancer services.
Example
loadbalancer listener using annotations# ...
listeners:
#...
- name: external3
port: 9094
type: loadbalancer
tls: true
configuration:
bootstrap:
annotations:
external-dns.alpha.kubernetes.io/hostname: kafka-bootstrap.mydomain.com.
external-dns.alpha.kubernetes.io/ttl: "60"
brokers:
- broker: 0
annotations:
external-dns.alpha.kubernetes.io/hostname: kafka-broker-0.mydomain.com.
external-dns.alpha.kubernetes.io/ttl: "60"
- broker: 1
annotations:
external-dns.alpha.kubernetes.io/hostname: kafka-broker-1.mydomain.com.
external-dns.alpha.kubernetes.io/ttl: "60"
- broker: 2
annotations:
external-dns.alpha.kubernetes.io/hostname: kafka-broker-2.mydomain.com.
external-dns.alpha.kubernetes.io/ttl: "60"
# ...10.10. GenericKafkaListenerConfiguration schema properties
| Property | Property type | Description |
|---|---|---|
brokerCertChainAndKey |
Reference to the |
|
class |
string |
Configures a specific class for
For |
externalTrafficPolicy |
string (one of [Local, Cluster]) |
Specifies whether the service routes external traffic to cluster-wide or node-local endpoints:
If unspecified, Kubernetes uses |
loadBalancerSourceRanges |
string array |
A list of CIDR ranges (for example |
bootstrap |
Bootstrap configuration. |
|
brokers |
Per-broker configurations. |
|
ipFamilyPolicy |
string (one of [RequireDualStack, SingleStack, PreferDualStack]) |
Specifies the IP Family Policy used by the service. Available options are
If unspecified, Kubernetes will choose the default value based on the service type. |
ipFamilies |
string (one or more of [IPv6, IPv4]) array |
Specifies the IP Families used by the service. Available options are |
createBootstrapService |
boolean |
Whether to create the bootstrap service or not. The bootstrap service is created by default (if not specified differently). This field can be used with the |
finalizers |
string array |
A list of finalizers configured for the |
useServiceDnsDomain |
boolean |
Configures whether the Kubernetes service DNS domain should be included in the generated addresses.
The default is |
maxConnections |
integer |
The maximum number of connections we allow for this listener in the broker at any time. New connections are blocked if the limit is reached. |
maxConnectionCreationRate |
integer |
The maximum connection creation rate we allow in this listener at any time. New connections will be throttled if the limit is reached. |
preferredNodePortAddressType |
string (one of [ExternalDNS, ExternalIP, Hostname, InternalIP, InternalDNS]) |
Defines which address type should be used as the node address. Available types are:
This property is used to select the preferred address type, which is checked first. If no address is found for this address type, the other types are checked in the default order. For |
publishNotReadyAddresses |
boolean |
Configures whether the service endpoints are considered "ready" even if the Pods themselves are not. Defaults to |
hostTemplate |
string |
Configures the template for generating the hostnames of the individual brokers. Valid placeholders that you can use in the template are |
advertisedHostTemplate |
string |
Configures the template for generating the advertised hostnames of the individual brokers. Valid placeholders that you can use in the template are |
advertisedPortTemplate |
string |
Configures the template for generating the advertised ports of the individual brokers. It allows to specify a simple mathematics formula that will be used to calculate the port. The only valid placeholder that you can use in the template is |
allocateLoadBalancerNodePorts |
boolean |
Configures whether to allocate NodePort automatically for the |
11. CertAndKeySecretSource schema reference
| Property | Property type | Description |
|---|---|---|
secretName |
string |
The name of the Secret containing the certificate. |
certificate |
string |
The name of the file certificate in the Secret. |
key |
string |
The name of the private key in the secret. The private key must be in unencrypted PKCS #8 format. For more information, see RFC 5208: https://datatracker.ietf.org/doc/html/rfc5208. |
12. GenericKafkaListenerConfigurationBootstrap schema reference
Used in: GenericKafkaListenerConfiguration
Configures bootstrap service settings for listeners.
Example configuration for the host, nodePort, loadBalancerIP, and annotations properties is shown in the GenericKafkaListenerConfiguration schema section.
12.1. Specifying alternative bootstrap addresses
To specify alternative names for the bootstrap address, use the alternativeNames property.
This property is applicable to all types of listeners.
The names are added to the broker certificates and can be used for TLS hostname verification.
Example
route listener configuration with additional bootstrap addresseslisteners:
#...
- name: external1
port: 9094
type: route
tls: true
configuration:
bootstrap:
alternativeNames:
- example.hostname1
- example.hostname2
# ...12.2. GenericKafkaListenerConfigurationBootstrap schema properties
| Property | Property type | Description |
|---|---|---|
alternativeNames |
string array |
Additional alternative names for the bootstrap service. The alternative names will be added to the list of subject alternative names of the TLS certificates. |
host |
string |
Specifies the hostname used for the bootstrap resource. For |
nodePort |
integer |
Node port for the bootstrap service. For |
loadBalancerIP |
string |
The loadbalancer is requested with the IP address specified in this property. This feature depends on whether the underlying cloud provider supports specifying the |
annotations |
map |
Annotations added to |
labels |
map |
Labels added to |
externalIPs |
string array |
External IPs associated to the nodeport service. These IPs are used by clients external to the Kubernetes cluster to access the Kafka brokers. This property is helpful when |
13. GenericKafkaListenerConfigurationBroker schema reference
Used in: GenericKafkaListenerConfiguration
Configures broker settings for listeners.
Example configuration for the host, nodePort, loadBalancerIP, and annotations properties is shown in the GenericKafkaListenerConfiguration schema section.
13.1. Overriding advertised addresses for brokers
By default, Strimzi tries to automatically determine the hostnames and ports that your Kafka cluster advertises to its clients. This is not sufficient in all situations, because the infrastructure on which Strimzi is running might not provide the right hostname or port through which Kafka can be accessed.
You can specify a broker ID and customize the advertised hostname and port in the configuration property of the listener.
Strimzi will then automatically configure the advertised address in the Kafka brokers and add it to the broker certificates so it can be used for TLS hostname verification.
Overriding the advertised host and ports is available for all types of listeners.
Example of an external
route listener configured with overrides for advertised addresseslisteners:
#...
- name: external1
port: 9094
type: route
tls: true
configuration:
brokers:
- broker: 0
advertisedHost: example.hostname.0
advertisedPort: 12340
- broker: 1
advertisedHost: example.hostname.1
advertisedPort: 12341
- broker: 2
advertisedHost: example.hostname.2
advertisedPort: 12342
# ...Instead of specifying the advertisedHost and advertisedPort fields for every broker, you can also use an advertisedHostTemplate and advertisedPortTemplate to generate them automatically.
The advertisedHostTemplate supports the following variables which are replaced with the actual values when the configuration is applied to the Kafka cluster:
-
The
{nodeId}variable is replaced with the ID of the Kafka node to which the template is applied. -
The
{nodePodName}variable is replaced with the Kubernetes pod name for the Kafka node where the template is applied.
The advertisedPortTemplate works as a simple mathematical formula where you can use the {nodeId} variable to calculate the port number for each broker.
The supported operations are addition (+), subtraction (-), multiplication (*), and brackets ((, )).
For example, if you set advertisedPortTemplate to 12340 + {nodeId}, the broker with the node ID 0 will have the advertised port 12340, the broker with node ID 2 will have advertised port 12342, and so on.
You can also set advertisedPortTemplate to a simple number without using the nodeId variable, in which case all brokers will have the same advertised port.
Example
route listener with advertisedHostTemplate configurationlisteners:
#...
- name: external1
port: 9094
type: route
tls: true
configuration:
advertisedHostTemplate: example.hostname.{nodeId}
advertisedPortTemplate: 12340 + {nodeId}
# ...13.2. GenericKafkaListenerConfigurationBroker schema properties
| Property | Property type | Description |
|---|---|---|
broker |
integer |
ID of the kafka broker (broker identifier). Broker IDs start from 0 and correspond to the number of broker replicas. |
advertisedHost |
string |
The host name used in the brokers' |
advertisedPort |
integer |
The port number used in the brokers' |
host |
string |
The broker host. This field will be used in the Ingress resource or in the Route resource to specify the desired hostname. This field can be used only with |
nodePort |
integer |
Node port for the per-broker service. This field can be used only with |
loadBalancerIP |
string |
The loadbalancer is requested with the IP address specified in this field. This feature depends on whether the underlying cloud provider supports specifying the |
annotations |
map |
Annotations that will be added to the |
labels |
map |
Labels that will be added to the |
externalIPs |
string array |
External IPs associated to the nodeport service. These IPs are used by clients external to the Kubernetes cluster to access the Kafka brokers. This field is helpful when |
14. KafkaAuthorizationSimple schema reference
Used in: KafkaClusterSpec
Configures the Kafka custom resource to use simple authorization and define Access Control Lists (ACLs).
ACLs allow you to define which users have access to which resources at a granular level.
Strimzi uses Kafka’s built-in StandardAuthorizer authorization plugin.
Set the type property in the authorization section to the value simple,
and configure a list of super users.
Super users are always allowed without querying ACL rules.
Access rules are configured for the KafkaUser, as described in the ACLRule schema reference.
Example
simple authorization configurationapiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
namespace: myproject
spec:
kafka:
# ...
authorization:
type: simple
superUsers:
- CN=user-1
- user-2
- CN=user-3
# ...|
Note
|
The super.user configuration option in the config property in Kafka.spec.kafka is ignored.
Designate super users in the authorization property instead.
|
14.1. KafkaAuthorizationSimple schema properties
The type property is a discriminator that distinguishes use of the KafkaAuthorizationSimple type from KafkaAuthorizationCustom.
It must have the value simple for the type KafkaAuthorizationSimple.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
superUsers |
string array |
List of super users. Should contain list of user principals which should get unlimited access rights. |
15. KafkaAuthorizationCustom schema reference
Used in: KafkaClusterSpec
Configures the Kafka custom resource to use a custom authorizer and define Access Control Lists (ACLs).
ACLs allow you to define which users have access to which resources at a granular level.
Configure the Kafka custom resource to specify an authorizer class that implements the org.apache.kafka.server.authorizer.Authorizer interface to support custom ACLs.
Set the type property in the authorization section to the value custom, and configure a list of super users.
Super users are always allowed without querying ACL rules.
Add additional configuration for initializing the custom authorizer using Kafka.spec.kafka.config.
Example
custom authorization configurationapiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
namespace: myproject
spec:
kafka:
# ...
authorization:
type: custom
authorizerClass: io.mycompany.CustomAuthorizer
superUsers:
- CN=user-1
- user-2
- CN=user-3
# ...
config:
authorization.custom.property1=value1
authorization.custom.property2=value2
# ...|
Note
|
The super.user configuration option in the config property in Kafka.spec.kafka is ignored.
Designate super users in the authorization property instead.
|
15.1. Adding custom authorizer JAR files to the container image
In addition to the Kafka custom resource configuration, the JAR files containing the custom authorizer class along with its dependencies must be available on the classpath of the Kafka broker.
You can add them by building Strimzi from the source-code.
The Strimzi build process provides a mechanism to add custom third-party libraries to the generated Kafka broker container image by adding them as dependencies in the pom.xml file under the docker-images/artifacts/kafka-thirdparty-libs directory.
The directory contains different folders for different Kafka versions. Choose the appropriate folder.
Before modifying the pom.xml file, the third-party library must be available in a Maven repository, and that Maven repository must be accessible to the Strimzi build process.
Alternatively, you can add the JARs to an existing Strimzi container image:
FROM quay.io/strimzi/kafka:1.0.1-kafka-4.2.0
USER root:root
COPY ./my-authorizer/ /opt/kafka/libs/
USER 100115.2. Using custom authorizers with OAuth authentication
When using oauth authentication with a groupsClaim configuration to extract user group information from JWT tokens, group information can be used in custom authorization calls.
Groups are accessible through the OAuthKafkaPrincipal object during custom authorization calls, as follows:
public List<AuthorizationResult> authorize(AuthorizableRequestContext requestContext, List<Action> actions) {
KafkaPrincipal principal = requestContext.principal();
if (principal instanceof OAuthKafkaPrincipal) {
OAuthKafkaPrincipal p = (OAuthKafkaPrincipal) principal;
for (String group: p.getGroups()) {
System.out.println("Group: " + group);
}
}
}15.3. KafkaAuthorizationCustom schema properties
The type property is a discriminator that distinguishes use of the KafkaAuthorizationCustom type from KafkaAuthorizationSimple.
It must have the value custom for the type KafkaAuthorizationCustom.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
authorizerClass |
string |
Authorization implementation class, which must be available in classpath. |
superUsers |
string array |
List of super users, which are user principals with unlimited access rights. |
supportsAdminApi |
boolean |
Indicates whether the custom authorizer supports the APIs for managing ACLs using the Kafka Admin API. Defaults to |
16. TopologyLabelRack schema reference
16.1. Topology-label-based rack awareness
Topology-label-based rack awareness (type: topology-label) is configured through a topologyKey.
topologyKey identifies a label on Kubernetes worker nodes that contains the name of the topology in its value.
An example of such a label is topology.kubernetes.io/zone (or failure-domain.beta.kubernetes.io/zone on older Kubernetes versions), which contains the name of the availability zone in which the Kubernetes node runs.
You can configure your Kafka cluster to be aware of the rack in which it runs and enable additional features such as spreading partition replicas across different racks or consuming messages from the closest replicas.
For more information about Kubernetes node labels, see Well-Known Labels, Annotations and Taints. Consult your Kubernetes administrator regarding the node label that represents the zone or rack into which the node is deployed.
Example
type: topology-label rack configuration for Kafka custom resourceapiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
rack:
type: topology-label
topologyKey: topology.kubernetes.io/zone
# ...When rack awareness based on a topology label is enabled, Strimzi adds a node affinity rule to ensure Kafka nodes are scheduled on Kubernetes worker nodes that include the specified topologyKey label.
It does not configure additional rules to distribute nodes across racks or zones.
Depending on your exact Kubernetes and Kafka configurations, you should add additional affinity rules or configure topologySpreadConstraints for Kafka to make sure the nodes are properly distributed across as many racks as possible.
For more information see Configuring pod scheduling.
16.2. TopologyLabelRack schema properties
The type property is a discriminator that distinguishes use of the TopologyLabelRack type from EnvironmentVariableRack.
It must have the value topology-label for the type TopologyLabelRack.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
topologyKey |
string |
A key that matches labels assigned to the Kubernetes cluster nodes. The value of the label is used to set a broker’s |
17. EnvironmentVariableRack schema reference
17.1. Environment-variable-based rack awareness
Environment-variable-based rack awareness (type: environment-variable) is configured using envVarName.
envVarName identifies the environment variable that contains the name of the topology in its value.
You must configure this environment variable yourself, for example by setting it in the node pool template configuration or by applying a mutating webhook or similar tooling.
Example
type: environment-variable rack configuration for Kafka custom resource and per-node pool environment variablesapiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
rack:
type: environment-variable
envVarName: MY_RACK_ID
# ...
---
apiVersion: kafka.strimzi.io/v1
kind: KafkaNodePool
metadata:
name: zone-1
labels:
strimzi.io/cluster: my-cluster
spec:
# ...
template:
kafkaContainer:
env:
- name: MY_RACK_ID
value: zone-1
---
apiVersion: kafka.strimzi.io/v1
kind: KafkaNodePool
metadata:
name: zone-2
labels:
strimzi.io/cluster: my-cluster
spec:
# ...
template:
kafkaContainer:
env:
- name: MY_RACK_ID
value: zone-2
---
apiVersion: kafka.strimzi.io/v1
kind: KafkaNodePool
metadata:
name: zone-3
labels:
strimzi.io/cluster: my-cluster
spec:
# ...
template:
kafkaContainer:
env:
- name: MY_RACK_ID
value: zone-3When rack awareness based on an environment variable is enabled, Strimzi does not add affinity rules.
You must configure your own affinity or topologySpreadConstraints rules to make sure that nodes are properly distributed across racks.
For more information see Configuring pod scheduling.
17.2. EnvironmentVariableRack schema properties
The type property is a discriminator that distinguishes use of the EnvironmentVariableRack type from TopologyLabelRack.
It must have the value environment-variable for the type EnvironmentVariableRack.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
envVarName |
string |
The name of the environment variable that defines the rack ID. Its value sets the |
18. Probe schema reference
Used in: CruiseControlSpec, EntityTopicOperatorSpec, EntityUserOperatorSpec, KafkaBridgeSpec, KafkaClusterSpec, KafkaConnectSpec, KafkaExporterSpec, KafkaMirrorMaker2Spec
| Property | Property type | Description |
|---|---|---|
initialDelaySeconds |
integer |
The initial delay before first the health is first checked. Default to 15 seconds. Minimum value is 0. |
timeoutSeconds |
integer |
The timeout for each attempted health check. Default to 5 seconds. Minimum value is 1. |
periodSeconds |
integer |
How often (in seconds) to perform the probe. Default to 10 seconds. Minimum value is 1. |
successThreshold |
integer |
Minimum consecutive successes for the probe to be considered successful after having failed. Defaults to 1. Must be 1 for liveness. Minimum value is 1. |
failureThreshold |
integer |
Minimum consecutive failures for the probe to be considered failed after having succeeded. Defaults to 3. Minimum value is 1. |
19. JvmOptions schema reference
Used in: CruiseControlSpec, EntityTopicOperatorSpec, EntityUserOperatorSpec, KafkaBridgeSpec, KafkaClusterSpec, KafkaConnectSpec, KafkaMirrorMaker2Spec, KafkaNodePoolSpec
| Property | Property type | Description |
|---|---|---|
-XX |
map |
A map of -XX options to the JVM. |
-Xmx |
string |
-Xmx option to to the JVM. |
-Xms |
string |
-Xms option to to the JVM. |
gcLoggingEnabled |
boolean |
Specifies whether the Garbage Collection logging is enabled. The default is false. |
javaSystemProperties |
|
A map of additional system properties which will be passed using the |
20. SystemProperty schema reference
Used in: JvmOptions
| Property | Property type | Description |
|---|---|---|
name |
string |
The system property name. |
value |
string |
The system property value. |
21. KafkaJmxOptions schema reference
Configures JMX connection options.
Get JMX metrics from Kafka brokers, Kafka Connect, and MirrorMaker 2. by connecting to port 9999.
Use the jmxOptions property to configure a password-protected or an unprotected JMX port.
Using password protection prevents unauthorized pods from accessing the port.
You can then obtain metrics about the component.
For example, for each Kafka broker you can obtain bytes-per-second usage data from clients, or the request rate of the network of the broker.
To enable security for the JMX port, set the type parameter in the authentication field to password.
Example password-protected JMX configuration for Kafka brokers
apiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
jmxOptions:
authentication:
type: "password"
# ...You can then deploy a pod into a cluster and obtain JMX metrics using the headless service by specifying which broker you want to address.
For example, to get JMX metrics from broker 0 you specify:
"CLUSTER-NAME-kafka-0.CLUSTER-NAME-kafka-brokers"CLUSTER-NAME-kafka-0 is name of the broker pod, and CLUSTER-NAME-kafka-brokers is the name of the headless service to return the IPs of the broker pods.
If the JMX port is secured, you can get the username and password by referencing them from the JMX Secret in the deployment of your pod.
For an unprotected JMX port, use an empty object {} to open the JMX port on the headless service.
You deploy a pod and obtain metrics in the same way as for the protected port, but in this case any pod can read from the JMX port.
Example open port JMX configuration for Kafka brokers
apiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
jmxOptions: {}
# ...|
Note
|
The jmxOptions configuration enables direct access to Java Management Extensions (JMX) from Kafka components.
It is not required for the Prometheus JMX Exporter, which collects and converts JMX metrics to Prometheus metrics without direct JMX access.
|
Additional resources
-
For more information on the Kafka component metrics exposed using JMX, see the Apache Kafka documentation.
21.1. KafkaJmxOptions schema properties
| Property | Property type | Description |
|---|---|---|
authentication |
Authentication configuration for connecting to the JMX port. |
22. KafkaJmxAuthenticationPassword schema reference
Used in: KafkaJmxOptions
The type property is a discriminator that distinguishes use of the KafkaJmxAuthenticationPassword type from other subtypes that may be added in the future.
It must have the value password for the type KafkaJmxAuthenticationPassword.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
23. JmxPrometheusExporterMetrics schema reference
Used in: CruiseControlSpec, KafkaBridgeSpec, KafkaClusterSpec, KafkaConnectSpec, KafkaMirrorMaker2Spec
The type property is a discriminator that distinguishes use of the JmxPrometheusExporterMetrics type from StrimziMetricsReporter.
It must have the value jmxPrometheusExporter for the type JmxPrometheusExporterMetrics.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
valueFrom |
ConfigMap entry where the Prometheus JMX Exporter configuration is stored. |
24. ExternalConfigurationReference schema reference
Used in: ExternalLogging, JmxPrometheusExporterMetrics
| Property | Property type | Description |
|---|---|---|
configMapKeyRef |
Reference to the key in the ConfigMap containing the configuration. |
25. StrimziMetricsReporter schema reference
Used in: CruiseControlSpec, KafkaBridgeSpec, KafkaClusterSpec, KafkaConnectSpec, KafkaMirrorMaker2Spec
The type property is a discriminator that distinguishes use of the StrimziMetricsReporter type from JmxPrometheusExporterMetrics.
It must have the value strimziMetricsReporter for the type StrimziMetricsReporter.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
values |
Configuration values for the Strimzi Metrics Reporter. |
26. StrimziMetricsReporterValues schema reference
Used in: StrimziMetricsReporter
| Property | Property type | Description |
|---|---|---|
allowList |
string array |
A list of regex patterns to filter the metrics to collect. Should contain at least one element. |
27. InlineLogging schema reference
Used in: CruiseControlSpec, EntityTopicOperatorSpec, EntityUserOperatorSpec, KafkaBridgeSpec, KafkaClusterSpec, KafkaConnectSpec, KafkaMirrorMaker2Spec
The type property is a discriminator that distinguishes use of the InlineLogging type from ExternalLogging.
It must have the value inline for the type InlineLogging.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
loggers |
map |
A Map from logger name to logger level. |
28. ExternalLogging schema reference
Used in: CruiseControlSpec, EntityTopicOperatorSpec, EntityUserOperatorSpec, KafkaBridgeSpec, KafkaClusterSpec, KafkaConnectSpec, KafkaMirrorMaker2Spec
The type property is a discriminator that distinguishes use of the ExternalLogging type from InlineLogging.
It must have the value external for the type ExternalLogging.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
valueFrom |
|
29. KafkaClusterTemplate schema reference
Used in: KafkaClusterSpec
| Property | Property type | Description |
|---|---|---|
pod |
Template for Kafka |
|
bootstrapService |
Template for Kafka bootstrap |
|
brokersService |
Template for Kafka broker |
|
externalBootstrapService |
Template for Kafka external bootstrap |
|
perPodService |
Template for Kafka per-pod |
|
externalBootstrapRoute |
Template for Kafka external bootstrap |
|
perPodRoute |
Template for Kafka per-pod |
|
externalBootstrapIngress |
Template for Kafka external bootstrap |
|
perPodIngress |
Template for Kafka per-pod |
|
persistentVolumeClaim |
Template for all Kafka |
|
podDisruptionBudget |
Template for Kafka |
|
kafkaContainer |
Template for the Kafka broker container. |
|
initContainer |
Template for the Kafka init container. |
|
clusterCaCert |
Template for Secret with Kafka Cluster certificate public key. |
|
serviceAccount |
Template for the Kafka service account. |
|
jmxSecret |
Template for Secret of the Kafka Cluster JMX authentication. |
|
clusterRoleBinding |
Template for the Kafka ClusterRoleBinding. |
|
podSet |
Template for Kafka |
30. PodTemplate schema reference
Used in: CruiseControlTemplate, EntityOperatorTemplate, KafkaBridgeTemplate, KafkaClusterTemplate, KafkaConnectTemplate, KafkaExporterTemplate, KafkaNodePoolTemplate
Configures the template for Kafka pods.
Example
PodTemplate configuration# ...
template:
pod:
metadata:
labels:
label1: value1
annotations:
anno1: value1
imagePullSecrets:
- name: my-docker-credentials
securityContext:
runAsUser: 1000001
fsGroup: 0
terminationGracePeriodSeconds: 120
hostAliases:
- ip: "192.168.1.86"
hostnames:
- "my-host-1"
- "my-host-2"
#...Use the hostAliases property to a specify a list of hosts and IP addresses,
which are injected into the /etc/hosts file of the pod.
This configuration is especially useful for Kafka Connect or MirrorMaker when a connection outside of the cluster is also requested by users.
30.1. PodTemplate schema properties
| Property | Property type | Description |
|---|---|---|
metadata |
Metadata applied to the resource. |
|
imagePullSecrets |
LocalObjectReference array |
List of references to secrets in the same namespace to use for pulling any of the images used by this Pod. When the |
securityContext |
Configures pod-level security attributes and common container settings. |
|
terminationGracePeriodSeconds |
integer |
The grace period is the duration in seconds after the processes running in the pod are sent a termination signal, and the time when the processes are forcibly halted with a kill signal. Set this value to longer than the expected cleanup time for your process. Value must be a non-negative integer. A zero value indicates delete immediately. You might need to increase the grace period for very large Kafka clusters, so that the Kafka brokers have enough time to transfer their work to another broker before they are terminated. Defaults to 30 seconds. |
affinity |
The pod’s affinity rules. |
|
tolerations |
Toleration array |
The pod’s tolerations. |
topologySpreadConstraints |
TopologySpreadConstraint array |
The pod’s topology spread constraints. |
priorityClassName |
string |
The name of the priority class used to assign priority to the pods. |
schedulerName |
string |
The name of the scheduler used to dispatch this |
hostAliases |
HostAlias array |
The pod’s HostAliases. HostAliases is an optional list of hosts and IPs that will be injected into the Pod’s hosts file if specified. |
dnsPolicy |
string (one of [ClusterFirstWithHostNet, ClusterFirst, Default, None]) |
The pod’s DNSPolicy. Defaults to |
dnsConfig |
The pod’s DNSConfig. If specified, it will be merged to the generated DNS configuration based on the DNSPolicy. |
|
enableServiceLinks |
boolean |
Indicates whether information about services should be injected into Pod’s environment variables. |
tmpDirSizeLimit |
string |
Defines the total amount of pod memory allocated for the temporary |
volumes |
|
Additional volumes that can be mounted to the pod. |
hostUsers |
boolean |
Use the host user namespace. Optional. Defaults to |
31. MetadataTemplate schema reference
Used in: BuildConfigTemplate, DeploymentTemplate, InternalServiceTemplate, PodDisruptionBudgetTemplate, PodTemplate, ResourceTemplate
Labels and Annotations are used to identify and organize resources, and are configured in the metadata property.
For example:
# ...
template:
pod:
metadata:
labels:
label1: value1
label2: value2
annotations:
annotation1: value1
annotation2: value2
# ...The labels and annotations fields can contain any labels or annotations that do not contain the reserved string strimzi.io.
Labels and annotations containing strimzi.io are used internally by Strimzi and cannot be configured.
31.1. MetadataTemplate schema properties
| Property | Property type | Description |
|---|---|---|
labels |
map |
Labels added to the Kubernetes resource. |
annotations |
map |
Annotations added to the Kubernetes resource. |
32. AdditionalVolume schema reference
Used in: PodTemplate
| Property | Property type | Description |
|---|---|---|
name |
string |
Name to use for the volume. Required. |
secret |
|
|
configMap |
|
|
emptyDir |
|
|
persistentVolumeClaim |
|
|
csi |
|
|
image |
|
33. EmptyDirVolume schema reference
Used in: AdditionalVolume
| Property | Property type | Description |
|---|---|---|
medium |
string (one of [Memory]) |
Medium represents the type of storage medium should back this volume. Valid values are unset or |
sizeLimit |
string |
The total amount of local storage required for this EmptyDir volume (for example 1Gi). |
34. InternalServiceTemplate schema reference
| Property | Property type | Description |
|---|---|---|
metadata |
Metadata applied to the resource. |
|
ipFamilyPolicy |
string (one of [RequireDualStack, SingleStack, PreferDualStack]) |
Specifies the IP Family Policy used by the service. Available options are |
ipFamilies |
string (one or more of [IPv6, IPv4]) array |
Specifies the IP Families used by the service. Available options are |
35. ResourceTemplate schema reference
Used in: CruiseControlTemplate, EntityOperatorTemplate, KafkaBridgeTemplate, KafkaClusterTemplate, KafkaConnectTemplate, KafkaExporterTemplate, KafkaNodePoolTemplate, KafkaUserTemplate
| Property | Property type | Description |
|---|---|---|
metadata |
Metadata applied to the resource. |
36. PodDisruptionBudgetTemplate schema reference
Used in: CruiseControlTemplate, EntityOperatorTemplate, KafkaBridgeTemplate, KafkaClusterTemplate, KafkaConnectTemplate, KafkaExporterTemplate
A PodDisruptionBudget is a Kubernetes resource that helps maintain high availability during planned maintenance or upgrades.
It defines the minimum number of pods that must remain available at all times.
Strimzi creates one PodDisruptionBudget per component:
-
Kafka cluster
-
Kafka Connect
-
MirrorMaker 2
-
HTTP Bridge
-
Entity Operator
-
Kafka Exporter
-
Cruise Control
Each budget applies across all pods deployed for that component.
A single PodDisruptionBudget applies to all associated node pool pods managed by the Kafka resource.
This is true regardless of how many StrimziPodSet resources are created for that component.
Disruption limits are applied at the component level, not per node pool.
By default, only one pod can be unavailable at a time.
You can modify this limit using the maxUnavailable property.
StrimziPodSet custom resources are managed by a controller that does not use maxUnavailable directly.
Instead, the value is automatically converted to minAvailable, which serves the same purpose.
For example:
-
If there are three broker pods and the
maxUnavailableproperty is set to1in theKafkaresource, theminAvailablesetting is2, allowing one pod to be unavailable. -
If there are three broker pods and the
maxUnavailableproperty is set to0(zero), theminAvailablesetting is3, requiring all three broker pods to be available and allowing zero pods to be unavailable.
The above examples also applies for the EntityOperator, Cruise Control, KafkaExporter deployments.
Example
PodDisruptionBudget template configuration# ...
template:
podDisruptionBudget:
metadata:
labels:
key1: label1
key2: label2
annotations:
key1: label1
key2: label2
maxUnavailable: 1
# ...Custom disruption budget behavior
To define custom disruption budget behavior, disable automatic PodDisruptionBudget generation.
Set the STRIMZI_POD_DISRUPTION_BUDGET_GENERATION environment variable to false in the Cluster Operator.
You can then create your own PodDisruptionBudget resources.
For example, apply separate budgets to specific node pools using label selectors with StrimziPodSet resources.
36.1. PodDisruptionBudgetTemplate schema properties
| Property | Property type | Description |
|---|---|---|
metadata |
Metadata to apply to the |
|
maxUnavailable |
integer |
Maximum number of unavailable pods to allow automatic Pod eviction. A Pod eviction is allowed when the |
37. ContainerTemplate schema reference
Used in: CruiseControlTemplate, EntityOperatorTemplate, KafkaBridgeTemplate, KafkaClusterTemplate, KafkaConnectTemplate, KafkaExporterTemplate, KafkaNodePoolTemplate
You can set custom security context and environment variables for a container.
The environment variables are defined under the env property as a list of objects with name and value fields.
The following example shows two custom environment variables and a custom security context set for the Kafka broker containers:
# ...
template:
kafkaContainer:
env:
- name: EXAMPLE_ENV_1
value: example.env.one
- name: EXAMPLE_ENV_2
value: example.env.two
securityContext:
runAsUser: 2000
# ...Environment variables prefixed with KAFKA_ are internal to Strimzi and should be avoided.
If you set a custom environment variable that is already in use by Strimzi, it is ignored and a warning is recorded in the log.
37.1. ContainerTemplate schema properties
| Property | Property type | Description |
|---|---|---|
env |
|
Environment variables which should be applied to the container. |
securityContext |
Security context for the container. |
|
volumeMounts |
VolumeMount array |
Additional volume mounts which should be applied to the container. |
38. ContainerEnvVar schema reference
Used in: ContainerTemplate
| Property | Property type | Description |
|---|---|---|
name |
string |
The environment variable key. |
value |
string |
The environment variable value. |
valueFrom |
Reference to the secret or config map property to which the environment variable is set. |
39. ContainerEnvVarSource schema reference
Used in: ContainerEnvVar
| Property | Property type | Description |
|---|---|---|
secretKeyRef |
Reference to a key in a secret. |
|
configMapKeyRef |
Reference to a key in a config map. |
40. TieredStorageCustom schema reference
Used in: KafkaClusterSpec
Enables custom tiered storage for Kafka.
If you want to use custom tiered storage, you must first add a tiered storage for Kafka plugin to the Strimzi image by building a custom container image.
Custom tiered storage configuration enables the use of a custom RemoteStorageManager configuration.
RemoteStorageManager is a Kafka interface for managing the interaction between Kafka and remote tiered storage.
If custom tiered storage is enabled, Strimzi uses the TopicBasedRemoteLogMetadataManager for Remote Log Metadata Management (RLMM).
|
Note
|
Tiered storage is a production-ready feature in Kafka since version 3.9.0, and it is also supported in Strimzi. Before introducing tiered storage to your environment, review the known limitations of this feature. |
Example custom tiered storage configuration
kafka:
tieredStorage:
type: custom
remoteStorageManager:
className: com.example.kafka.tiered.storage.s3.S3RemoteStorageManager
classPath: /opt/kafka/plugins/tiered-storage-s3/*
config:
# A map with String keys and String values.
# Key properties are automatically prefixed with `rsm.config.`
# and appended to Kafka broker config.
storage.bucket.name: my-bucket
config:
...
# Additional RLMM configuration can be added through the Kafka config
# under `spec.kafka.config` using the `rlmm.config.` prefix.
rlmm.config.remote.log.metadata.topic.replication.factor: 140.1. TieredStorageCustom schema properties
The type property is a discriminator that distinguishes use of the TieredStorageCustom type from other subtypes that may be added in the future.
It must have the value custom for the type TieredStorageCustom.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
remoteStorageManager |
Configuration for the Remote Storage Manager. |
41. RemoteStorageManager schema reference
Used in: TieredStorageCustom
| Property | Property type | Description |
|---|---|---|
className |
string |
The class name for the |
classPath |
string |
The class path for the |
config |
map |
The additional configuration map for the |
42. QuotasPluginKafka schema reference
Used in: KafkaClusterSpec
The type property is a discriminator that distinguishes use of the QuotasPluginKafka type from QuotasPluginStrimzi.
It must have the value kafka for the type QuotasPluginKafka.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
producerByteRate |
integer |
The default client quota on the maximum bytes per-second that each client can publish to each broker before it is throttled. Applied on a per-broker basis. |
consumerByteRate |
integer |
The default client quota on the maximum bytes per-second that each client can fetch from each broker before it is throttled. Applied on a per-broker basis. |
requestPercentage |
integer |
The default client quota limits the maximum CPU utilization of each client as a percentage of the network and I/O threads of each broker. Applied on a per-broker basis. |
controllerMutationRate |
number |
The default client quota on the rate at which mutations are accepted per second for create topic requests, create partition requests, and delete topic requests, defined for each broker. The mutations rate is measured by the number of partitions created or deleted. Applied on a per-broker basis. |
43. QuotasPluginStrimzi schema reference
Used in: KafkaClusterSpec
The type property is a discriminator that distinguishes use of the QuotasPluginStrimzi type from QuotasPluginKafka.
It must have the value strimzi for the type QuotasPluginStrimzi.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
producerByteRate |
integer |
A per-broker byte-rate quota for clients producing to a broker, independent of their number. If clients produce at maximum speed, the quota is shared equally between all non-excluded producers. Otherwise, the quota is divided based on each client’s production rate. |
consumerByteRate |
integer |
A per-broker byte-rate quota for clients consuming from a broker, independent of their number. If clients consume at maximum speed, the quota is shared equally between all non-excluded consumers. Otherwise, the quota is divided based on each client’s consumption rate. |
minAvailableBytesPerVolume |
integer |
Stop message production if the available size (in bytes) of the storage is lower than or equal to this specified value. This condition is mutually exclusive with |
minAvailableRatioPerVolume |
number |
Stop message production if the percentage of available storage space falls below or equals the specified ratio (set as a decimal representing a percentage). This condition is mutually exclusive with |
excludedPrincipals |
string array |
List of principals that are excluded from the quota. The principals have to be prefixed with |
44. EntityOperatorSpec schema reference
Used in: KafkaSpec
| Property | Property type | Description |
|---|---|---|
topicOperator |
Configuration of the Topic Operator. |
|
userOperator |
Configuration of the User Operator. |
|
template |
Template for Entity Operator resources. The template allows users to specify how a |
45. EntityTopicOperatorSpec schema reference
Used in: EntityOperatorSpec
Configures the Topic Operator.
45.1. Logging
The Topic Operator has its own preconfigured loggers:
| Logger | Description | Default Level |
|---|---|---|
|
Default logger for all classes |
INFO |
|
Logs HTTP server activity |
INFO |
The Topic Operator uses the Apache log4j2 logger implementation.
Use the logging property to configure loggers and logger levels.
You can set log levels using either the inline or external logging configuration types.
Specify loggers and levels directly in the custom resource for inline configuration:
Example inline logging configuration
apiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
entityOperator:
# ...
topicOperator:
watchedNamespace: my-topic-namespace
reconciliationIntervalMs: 60000
logging:
type: inline
loggers:
rootLogger.level: INFO
logger.jetty.level: WARN
# ...You can define additional loggers by specifying the full class or package name using logger.<name>.name.
For example, to configure more detailed logging for the Topic Operator inline:
Example custom inline loggers
# ...
logger.top.name: io.strimzi.operator.topic # (1)
logger.top.level: DEBUG # (2)
logger.toc.name: io.strimzi.operator.topic.TopicOperator # (3)
logger.toc.level: TRACE # (4)-
Creates a logger for the
topicpackage. -
Sets the logging level for the
topicpackage. -
Creates a logger for the
TopicOperatorclass. -
Sets the logging level for the
TopicOperatorclass.
Alternatively, you can reference an external ConfigMap containing a complete log4j2.properties file that defines your own log4j2 configuration, including loggers, appenders, and layout configuration:
Example external logging configuration
apiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
entityOperator:
# ...
topicOperator:
watchedNamespace: my-topic-namespace
reconciliationIntervalMs: 60000
logging:
type: external
valueFrom:
configMapKeyRef:
# name and key are mandatory
name: customConfigMap
key: log4j2.properties
# ...Garbage collector (GC)
Garbage collector logging can also be enabled (or disabled) using the jvmOptions property.
45.2. EntityTopicOperatorSpec schema properties
| Property | Property type | Description |
|---|---|---|
watchedNamespace |
string |
The namespace the Topic Operator should watch. |
image |
string |
The image to use for the Topic Operator. |
reconciliationIntervalMs |
integer |
Interval between periodic reconciliations in milliseconds. |
startupProbe |
Pod startup checking. |
|
livenessProbe |
Pod liveness checking. |
|
readinessProbe |
Pod readiness checking. |
|
resources |
CPU and memory resources to reserve. |
|
logging |
Logging configuration. |
|
jvmOptions |
JVM Options for pods. |
46. EntityUserOperatorSpec schema reference
Used in: EntityOperatorSpec
Configures the User Operator.
46.1. Logging
The User Operator has its own preconfigured loggers:
| Logger | Description | Default Level |
|---|---|---|
|
Default logger for all classes |
INFO |
|
Logs HTTP server activity |
INFO |
The User Operator uses the Apache log4j2 logger implementation.
Use the logging property to configure loggers and logger levels.
You can set log levels using either the inline or external logging configuration types.
Specify loggers and levels directly in the custom resource for inline configuration:
Example inline logging configuration
apiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
entityOperator:
# ...
userOperator:
watchedNamespace: my-topic-namespace
reconciliationIntervalMs: 60000
logging:
type: inline
loggers:
rootLogger.level: INFO
logger.jetty.level: WARN
# ...You can define additional loggers by specifying the full class or package name using logger.<name>.name.
For example, to configure more detailed logging for the User Operator inline:
Example custom inline loggers
# ...
logger.uop.name: io.strimzi.operator.user # (1)
logger.uop.level: DEBUG # (2)
logger.abstractcache.name: io.strimzi.operator.user.operator.cache.AbstractCache # (3)
logger.abstractcache.level: TRACE # (4)-
Creates a logger for the
userpackage. -
Sets the logging level for the
userpackage. -
Creates a logger for the
AbstractCacheclass. -
Sets the logging level for the
AbstractCacheclass.
Alternatively, you can reference an external ConfigMap containing a complete log4j2.properties file that defines your own log4j2 configuration, including loggers, appenders, and layout configuration:
Example external logging configuration
apiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
entityOperator:
# ...
userOperator:
watchedNamespace: my-topic-namespace
reconciliationIntervalMs: 60000
logging:
type: external
valueFrom:
configMapKeyRef:
# name and key are mandatory
name: customConfigMap
key: log4j2.properties
# ...Garbage collector (GC)
Garbage collector logging can also be enabled (or disabled) using the jvmOptions property.
46.2. EntityUserOperatorSpec schema properties
| Property | Property type | Description |
|---|---|---|
watchedNamespace |
string |
The namespace the User Operator should watch. |
image |
string |
The image to use for the User Operator. |
reconciliationIntervalMs |
integer |
Interval between periodic reconciliations in milliseconds. |
secretPrefix |
string |
The prefix that will be added to the KafkaUser name to be used as the Secret name. |
livenessProbe |
Pod liveness checking. |
|
readinessProbe |
Pod readiness checking. |
|
resources |
CPU and memory resources to reserve. |
|
logging |
Logging configuration. |
|
jvmOptions |
JVM Options for pods. |
47. EntityOperatorTemplate schema reference
Used in: EntityOperatorSpec
| Property | Property type | Description |
|---|---|---|
deployment |
Template for Entity Operator |
|
pod |
Template for Entity Operator |
|
topicOperatorContainer |
Template for the Entity Topic Operator container. |
|
userOperatorContainer |
Template for the Entity User Operator container. |
|
serviceAccount |
Template for the Entity Operator service account. |
|
podDisruptionBudget |
Template for the Entity Operator Pod Disruption Budget. |
|
entityOperatorRole |
Template for the Entity Operator Role. |
|
topicOperatorRoleBinding |
Template for the Entity Topic Operator RoleBinding. |
|
userOperatorRoleBinding |
Template for the Entity Topic Operator RoleBinding. |
48. DeploymentTemplate schema reference
Use deploymentStrategy to specify the strategy used to replace old pods with new ones when deployment configuration changes.
Use one of the following values:
-
RollingUpdate: Pods are restarted with zero downtime. -
Recreate: Pods are terminated before new ones are created.
Using the Recreate deployment strategy has the advantage of not requiring spare resources, but the disadvantage is the application downtime.
Example showing the deployment strategy set to
Recreate.# ...
template:
deployment:
deploymentStrategy: Recreate
# ...This configuration change does not cause a rolling update.
48.1. DeploymentTemplate schema properties
| Property | Property type | Description |
|---|---|---|
metadata |
Metadata applied to the resource. |
|
deploymentStrategy |
string (one of [RollingUpdate, Recreate]) |
Pod replacement strategy for deployment configuration changes. Valid values are |
49. CertificateAuthority schema reference
Used in: KafkaSpec
Configuration of how TLS certificates are used within the cluster. This applies to certificates used for both internal communication within the cluster and to certificates used for client access via Kafka.spec.kafka.listeners.tls.
| Property | Property type | Description |
|---|---|---|
generateCertificateAuthority |
boolean |
If true then Certificate Authority certificates will be generated automatically. Otherwise the user will need to provide a Secret with the CA certificate. Default is true. |
generateSecretOwnerReference |
boolean |
If |
validityDays |
integer |
The number of days generated certificates should be valid for. The default is 365. |
renewalDays |
integer |
The number of days in the certificate renewal period. This is the number of days before the a certificate expires during which renewal actions may be performed. When |
certificateExpirationPolicy |
string (one of [replace-key, renew-certificate]) |
How should CA certificate expiration be handled when |
50. CruiseControlSpec schema reference
Used in: KafkaSpec
Configures a Cruise Control cluster.
Configuration options relate to:
-
Goals configuration
-
Capacity limits for resource distribution goals
The config properties are one part of the overall configuration for the resource.
Use the config properties to configure Cruise Control options as keys.
Example Cruise Control configuration
apiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
# ...
cruiseControl:
# ...
config:
# Note that `default.goals` (superset) must also include all `hard.goals` (subset)
default.goals: >
com.linkedin.kafka.cruisecontrol.analyzer.goals.RackAwareGoal,
com.linkedin.kafka.cruisecontrol.analyzer.goals.ReplicaCapacityGoal
hard.goals: >
com.linkedin.kafka.cruisecontrol.analyzer.goals.RackAwareGoal
cpu.balance.threshold: 1.1
metadata.max.age.ms: 300000
send.buffer.bytes: 131072
webserver.http.cors.enabled: true
webserver.http.cors.origin: "*"
webserver.http.cors.exposeheaders: "User-Task-ID,Content-Type"
# ...The values can be one of the following JSON types:
-
String
-
Number
-
Boolean
Exceptions
You can specify and configure the options listed in the Cruise Control documentation.
However, Strimzi takes care of configuring and managing options related to the following, which cannot be changed:
-
Security (encryption, authentication, and authorization)
-
Connection to the Kafka cluster
-
Client ID configuration
-
Web server configuration
-
Self healing
Properties with the following prefixes cannot be set:
-
bootstrap.servers -
capacity.config.file -
client.id -
failed.brokers.zk.path -
kafka.broker.failure.detection.enable -
metric.reporter.sampler.bootstrap.servers -
network. -
request.reason.required -
security. -
self.healing. -
ssl. -
topic.config.provider.class -
two.step. -
webserver.accesslog. -
webserver.api.urlprefix -
webserver.http. -
webserver.session.path -
zookeeper.
If the config property contains an option that cannot be changed, it is disregarded, and a warning message is logged to the Cluster Operator log file.
All other supported options are forwarded to Cruise Control, including the following exceptions to the options configured by Strimzi:
-
Any
sslconfiguration for supported TLS versions and cipher suites -
Configuration for
webserverproperties to enable Cross-Origin Resource Sharing (CORS)
50.1. Cross-Origin Resource Sharing (CORS)
Cross-Origin Resource Sharing (CORS) is a HTTP mechanism for controlling access to REST APIs.
Restrictions can be on access methods or originating URLs of client applications.
You can enable CORS with Cruise Control using the webserver.http.cors.enabled property in the config.
When enabled, CORS permits read access to the Cruise Control REST API from applications that have different originating URLs than Strimzi.
This allows applications from specified origins to use GET requests to fetch information about the Kafka cluster through the Cruise Control API.
For example, applications can fetch information on the current cluster load or the most recent optimization proposal.
POST requests are not permitted.
|
Note
|
For more information on using CORS with Cruise Control, see REST APIs in the Cruise Control Wiki. |
Enabling CORS for Cruise Control
You enable and configure CORS in Kafka.spec.cruiseControl.config.
apiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
# ...
cruiseControl:
# ...
config:
webserver.http.cors.enabled: true # (1)
webserver.http.cors.origin: "*" # (2)
webserver.http.cors.exposeheaders: "User-Task-ID,Content-Type" # (3)
# ...-
Enables CORS.
-
Specifies permitted origins for the
Access-Control-Allow-OriginHTTP response header. You can use a wildcard or specify a single origin as a URL. If you use a wildcard, a response is returned following requests from any origin. -
Exposes specified header names for the
Access-Control-Expose-HeadersHTTP response header. Applications in permitted origins can read responses with the specified headers.
50.2. Cruise Control REST API security
The Cruise Control REST API is secured with HTTP Basic authentication and SSL to protect the cluster against potentially destructive Cruise Control operations, such as decommissioning Kafka brokers. We recommend that Cruise Control in Strimzi is only used with these settings enabled.
However, it is possible to disable these settings by specifying the following Cruise Control configuration:
-
To disable the built-in HTTP Basic authentication, set
webserver.security.enabletofalse. -
To disable the built-in SSL, set
webserver.ssl.enabletofalse.
Cruise Control configuration to disable API authorization, authentication, and SSL
apiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
# ...
cruiseControl:
config:
webserver.security.enable: false
webserver.ssl.enable: false
# ...50.3. API users
With the necessary permissions, create REST API users to safely access a secured Cruise Control REST API directly.
This allows roles and permissions to be defined to allow advanced users and third-party applications to access the Cruise Control REST API without having to disable basic HTTP authentication.
The following use cases would benefit from accessing the Cruise Control API without disabling API security:
-
Monitoring a Strimzi-managed Kafka cluster with the Cruise Control user interface.
-
Gathering Cruise Control-specific statistical information not available through Strimzi or Cruise Control sensor metrics, such as detailed information surrounding cluster and partition load and user tasks.
-
Debugging Cruise Control in a secured environment.
Cruise Control reads authentication credentials for API users in Jetty’s HashLoginService file format.
Standard Cruise Control USER and VIEWER roles are supported.
-
USERhas access to all theGETendpoints exceptbootstrapandtrain. -
VIEWERhas access tokafka_cluster_state,user_tasks, andreview_boardendpoints.
In this example, we define two custom API users in the supported format in a text file called cruise-control-auth.txt:
userOne: passwordOne, USER
userTwo: passwordTwo, VIEWERThen, use this file to create a secret with the following command:
kubectl create secret generic cruise-control-api-users-secret --from-file=cruise-control-auth.txt=cruise-control-auth.txtNext, we reference the secret in the spec.cruiseControl.apiUsers section of the Kafka resource:
Example Cruise Control apiUsers configuration
apiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
# ...
cruiseControl:
# ...
apiUsers:
type: hashLoginService
valueFrom:
secretKeyRef:
name: cruise-control-api-users-secret
key: cruise-control-auth.txt
...Strimzi then decodes and uses the contents of this secret to populate Cruise Control’s API authentication credentials file.
50.4. Configuring capacity limits
Cruise Control uses capacity limits to determine if optimization goals for resource capacity limits are being broken. There are four goals of this type:
-
DiskCapacityGoal- Disk utilization capacity -
CpuCapacityGoal- CPU utilization capacity -
NetworkInboundCapacityGoal- Network inbound utilization capacity -
NetworkOutboundCapacityGoal- Network outbound utilization capacity
You specify capacity limits for Kafka broker resources in the brokerCapacity property in Kafka.spec.cruiseControl .
They are enabled by default and you can change their default values.
Capacity limits can be set for the following broker resources:
-
cpu- CPU resource in millicores or CPU cores (Default: 1) -
inboundNetwork- Inbound network throughput in byte units per second (Default: 10000KiB/s) -
outboundNetwork- Outbound network throughput in byte units per second (Default: 10000KiB/s)
For network throughput, use an integer value with standard Kubernetes byte units (K, M, G) or their bibyte (power of two) equivalents (Ki, Mi, Gi) per second.
|
Note
|
Disk and CPU capacity limits are automatically generated by Strimzi, so you do not need to set them.
In order to guarantee accurate rebalance proposals when using CPU goals, you can set CPU requests equal to CPU limits in KafkaNodePool.spec.resources.
That way, all CPU resources are reserved upfront and are always available.
This configuration allows Cruise Control to properly evaluate the CPU utilization when preparing the rebalance proposals based on CPU goals.
In cases where you cannot set CPU requests equal to CPU limits in KafkaNodePool.spec.resources, you can set the CPU capacity manually for the same accuracy.
|
Example Cruise Control brokerCapacity configuration using bibyte units
apiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
# ...
cruiseControl:
# ...
brokerCapacity:
cpu: "2"
inboundNetwork: 10000KiB/s
outboundNetwork: 10000KiB/s
# ...50.5. Configuring capacity overrides
Brokers might be running on nodes with heterogeneous network or CPU resources.
If that’s the case, specify overrides that set the network capacity and CPU limits for each broker.
The overrides ensure an accurate rebalance between the brokers.
Override capacity limits can be set for the following broker resources:
-
cpu- CPU resource in millicores or CPU cores (Default: 1) -
inboundNetwork- Inbound network throughput in byte units per second (Default: 10000KiB/s) -
outboundNetwork- Outbound network throughput in byte units per second (Default: 10000KiB/s)
An example of Cruise Control capacity overrides configuration using bibyte units
apiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: my-cluster
spec:
# ...
cruiseControl:
# ...
brokerCapacity:
cpu: "1"
inboundNetwork: 10000KiB/s
outboundNetwork: 10000KiB/s
overrides:
- brokers: [0]
cpu: "2.755"
inboundNetwork: 20000KiB/s
outboundNetwork: 20000KiB/s
- brokers: [1, 2]
cpu: 3000m
inboundNetwork: 30000KiB/s
outboundNetwork: 30000KiB/sCPU capacity is determined using configuration values in the following order of precedence, with the highest priority first:
-
Kafka.spec.cruiseControl.brokerCapacity.overrides.cputhat define custom CPU capacity limits for individual brokers -
Kafka.cruiseControl.brokerCapacity.cputhat defines custom CPU capacity limits for all brokers in the kafka cluster -
KafkaNodePool.spec.resources.requests.cputhat defines the CPU resources that are reserved for each broker in the Kafka cluster. -
KafkaNodePool.spec.resources.limits.cputhat defines the maximum CPU resources that can be consumed by each broker in the Kafka cluster.
This order of precedence is the sequence in which different configuration values are considered when determining the actual capacity limit for a Kafka broker. For example, broker-specific overrides take precedence over capacity limits for all brokers. If none of the CPU capacity configurations are specified, the default CPU capacity for a Kafka broker is set to 1 CPU core.
For more information, refer to the BrokerCapacity schema reference.
50.6. Logging
Cruise Control has its own preconfigured logger:
| Logger | Description | Default Level |
|---|---|---|
|
Default logger for all classes |
INFO |
Cruise Control uses the Apache log4j2 logger implementation.
Use the logging property to configure loggers and logger levels.
You can set log levels using either the inline or external logging configuration types.
Specify loggers and levels directly in the custom resource for inline configuration:
Example inline logging configuration
apiVersion: kafka.strimzi.io/v1
kind: Kafka
# ...
spec:
cruiseControl:
# ...
logging:
type: inline
loggers:
rootLogger.level: INFO
# ...You can define additional loggers by specifying the full class or package name using logger.<name>.name.
For example, to configure more detailed logging for Cruise Control inline:
Example custom inline loggers
# ...
logger.exec.name: com.linkedin.kafka.cruisecontrol.executor.Executor # (1)
logger.exec.level: TRACE # (2)
logger.go.name: com.linkedin.kafka.cruisecontrol.analyzer.GoalOptimizer # (3)
logger.go.level: DEBUG # (4)-
Creates a logger for the Cruise Control
Executorclass. -
Sets the logging level for the
Executorclass. -
Creates a logger for the Cruise Control
GoalOptimizerclass. -
Sets the logging level for the
GoalOptimizerclass.
Alternatively, you can reference an external ConfigMap containing a complete log4j2.properties file that defines your own log4j2 configuration, including loggers, appenders, and layout configuration:
Example external logging configuration
apiVersion: kafka.strimzi.io/v1
kind: Kafka
# ...
spec:
cruiseControl:
# ...
logging:
type: external
valueFrom:
configMapKeyRef:
# name and key are mandatory
name: customConfigMap
key: log4j2.properties
# ...Garbage collector (GC)
Garbage collector logging can also be enabled (or disabled) using the jvmOptions property.
50.7. CruiseControlSpec schema properties
| Property | Property type | Description |
|---|---|---|
image |
string |
The container image used for Cruise Control pods. If no image name is explicitly specified, the image name corresponds to the name specified in the Cluster Operator configuration. If an image name is not defined in the Cluster Operator configuration, a default value is used. |
resources |
CPU and memory resources to reserve for the Cruise Control container. |
|
livenessProbe |
Pod liveness checking for the Cruise Control container. |
|
readinessProbe |
Pod readiness checking for the Cruise Control container. |
|
jvmOptions |
JVM Options for the Cruise Control container. |
|
logging |
Logging configuration (Log4j 2) for Cruise Control. |
|
template |
Template to specify how Cruise Control resources, |
|
brokerCapacity |
The Cruise Control |
|
config |
map |
The Cruise Control configuration. For a full list of configuration options refer to https://github.com/linkedin/cruise-control/wiki/Configurations. Note that properties with the following prefixes cannot be set: bootstrap.servers, client.id, zookeeper., network., security., failed.brokers.zk.path,webserver.http., webserver.api.urlprefix, webserver.session.path, webserver.accesslog., two.step., request.reason.required,metric.reporter.sampler.bootstrap.servers, capacity.config.file, self.healing., ssl., kafka.broker.failure.detection.enable, topic.config.provider.class (with the exception of: ssl.cipher.suites, ssl.protocol, ssl.enabled.protocols, webserver.http.cors.enabled, webserver.http.cors.origin, webserver.http.cors.exposeheaders, webserver.security.enable, webserver.ssl.enable). |
metricsConfig |
Metrics configuration. Only |
|
apiUsers |
Configuration of the Cruise Control REST API users. |
|
autoRebalance |
Auto-rebalancing on scaling related configuration listing the modes, when brokers are added or removed, with the corresponding rebalance template configurations.If this field is set, at least one mode has to be defined. |
51. CruiseControlTemplate schema reference
Used in: CruiseControlSpec
| Property | Property type | Description |
|---|---|---|
deployment |
Template for Cruise Control |
|
pod |
Template for Cruise Control |
|
apiService |
Template for Cruise Control API |
|
podDisruptionBudget |
Template for Cruise Control |
|
cruiseControlContainer |
Template for the Cruise Control container. |
|
serviceAccount |
Template for the Cruise Control service account. |
52. BrokerCapacity schema reference
Used in: CruiseControlSpec
| Property | Property type | Description |
|---|---|---|
cpu |
string |
Broker capacity for CPU resource in cores or millicores. For example, 1, 1.500, 1500m. For more information on valid CPU resource units see https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/#meaning-of-cpu. |
inboundNetwork |
string |
Broker capacity for inbound network throughput in bytes per second. Use an integer value with standard Kubernetes byte units (K, M, G) or their bibyte (power of two) equivalents (Ki, Mi, Gi) per second. For example, 10000KiB/s. |
outboundNetwork |
string |
Broker capacity for outbound network throughput in bytes per second. Use an integer value with standard Kubernetes byte units (K, M, G) or their bibyte (power of two) equivalents (Ki, Mi, Gi) per second. For example, 10000KiB/s. |
overrides |
|
Overrides for individual brokers. The |
53. BrokerCapacityOverride schema reference
Used in: BrokerCapacity
| Property | Property type | Description |
|---|---|---|
brokers |
integer array |
List of Kafka brokers (broker identifiers). |
cpu |
string |
Broker capacity for CPU resource in cores or millicores. For example, 1, 1.500, 1500m. For more information on valid CPU resource units see https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/#meaning-of-cpu. |
inboundNetwork |
string |
Broker capacity for inbound network throughput in bytes per second. Use an integer value with standard Kubernetes byte units (K, M, G) or their bibyte (power of two) equivalents (Ki, Mi, Gi) per second. For example, 10000KiB/s. |
outboundNetwork |
string |
Broker capacity for outbound network throughput in bytes per second. Use an integer value with standard Kubernetes byte units (K, M, G) or their bibyte (power of two) equivalents (Ki, Mi, Gi) per second. For example, 10000KiB/s. |
54. HashLoginServiceApiUsers schema reference
Used in: CruiseControlSpec
The type property is a discriminator that distinguishes use of the HashLoginServiceApiUsers type from other subtypes that may be added in the future.
It must have the value hashLoginService for the type HashLoginServiceApiUsers.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
valueFrom |
Secret from which the custom Cruise Control API authentication credentials are read. |
55. PasswordSource schema reference
Used in: HashLoginServiceApiUsers, Password
| Property | Property type | Description |
|---|---|---|
secretKeyRef |
Selects a key of a Secret in the resource’s namespace. |
56. KafkaAutoRebalanceConfiguration schema reference
Used in: CruiseControlSpec
| Property | Property type | Description |
|---|---|---|
mode |
string (one of [remove-brokers, add-brokers]) |
Specifies the mode for automatically rebalancing when brokers are added or removed. Supported modes are |
template |
Reference to the KafkaRebalance custom resource to be used as the configuration template for the auto-rebalancing on scaling when running for the corresponding mode. |
57. LocalObjectReference schema reference
| Property | Property type | Description |
|---|---|---|
name |
string |
58. KafkaExporterSpec schema reference
Used in: KafkaSpec
| Property | Property type | Description |
|---|---|---|
image |
string |
The container image used for the Kafka Exporter pods. If no image name is explicitly specified, the image name corresponds to the version specified in the Cluster Operator configuration. If an image name is not defined in the Cluster Operator configuration, a default value is used. |
groupRegex |
string |
Regular expression to specify which consumer groups to collect. Default value is |
topicRegex |
string |
Regular expression to specify which topics to collect. Default value is |
groupExcludeRegex |
string |
Regular expression to specify which consumer groups to exclude. |
topicExcludeRegex |
string |
Regular expression to specify which topics to exclude. |
resources |
CPU and memory resources to reserve. |
|
logging |
string |
Only log messages with the given severity or above. Valid levels: [ |
livenessProbe |
Pod liveness check. |
|
readinessProbe |
Pod readiness check. |
|
enableSaramaLogging |
boolean |
Enable Sarama logging, a Go client library used by the Kafka Exporter. |
showAllOffsets |
boolean |
Whether show the offset/lag for all consumer group, otherwise, only show connected consumer groups. |
template |
Customization of deployment templates and pods. |
59. KafkaExporterTemplate schema reference
Used in: KafkaExporterSpec
| Property | Property type | Description |
|---|---|---|
deployment |
Template for Kafka Exporter |
|
pod |
Template for Kafka Exporter |
|
container |
Template for the Kafka Exporter container. |
|
serviceAccount |
Template for the Kafka Exporter service account. |
|
podDisruptionBudget |
Template for the Pod Disruption Budget for Kafka Exporter pods. |
60. KafkaStatus schema reference
Used in: Kafka
| Property | Property type | Description |
|---|---|---|
conditions |
|
List of status conditions. |
observedGeneration |
integer |
The generation of the CRD that was last reconciled by the operator. |
listeners |
|
Addresses of the internal and external listeners. |
kafkaNodePools |
|
List of the KafkaNodePools used by this Kafka cluster. |
clusterId |
string |
Kafka cluster Id. |
operatorLastSuccessfulVersion |
string |
The version of the Strimzi Cluster Operator which performed the last successful reconciliation. |
kafkaVersion |
string |
The version of Kafka currently deployed in the cluster. |
kafkaMetadataVersion |
string |
The KRaft metadata.version currently used by the Kafka cluster. |
autoRebalance |
The status of an auto-rebalancing triggered by a cluster scaling request. |
61. Condition schema reference
Used in: KafkaBridgeStatus, KafkaConnectorStatus, KafkaConnectStatus, KafkaMirrorMaker2Status, KafkaNodePoolStatus, KafkaRebalanceStatus, KafkaStatus, KafkaTopicStatus, KafkaUserStatus, StrimziPodSetStatus
| Property | Property type | Description |
|---|---|---|
type |
string |
The unique identifier of a condition, used to distinguish between other conditions in the resource. |
status |
string |
The status of the condition, either True, False or Unknown. |
lastTransitionTime |
string |
Last time the condition of a type changed from one status to another. The required format is 'yyyy-MM-ddTHH:mm:ssZ', in the UTC time zone. |
reason |
string |
The reason for the condition’s last transition (a single word in CamelCase). |
message |
string |
Human-readable message indicating details about the condition’s last transition. |
62. ListenerStatus schema reference
Used in: KafkaStatus
| Property | Property type | Description |
|---|---|---|
name |
string |
The name of the listener. |
addresses |
|
A list of the addresses for this listener. |
bootstrapServers |
string |
A comma-separated list of |
certificates |
string array |
A list of TLS certificates which can be used to verify the identity of the server when connecting to the given listener. Set only for |
63. ListenerAddress schema reference
Used in: ListenerStatus
| Property | Property type | Description |
|---|---|---|
host |
string |
The DNS name or IP address of the Kafka bootstrap service. |
port |
integer |
The port of the Kafka bootstrap service. |
64. UsedNodePoolStatus schema reference
Used in: KafkaStatus
| Property | Property type | Description |
|---|---|---|
name |
string |
The name of the KafkaNodePool used by this Kafka resource. |
65. KafkaAutoRebalanceStatus schema reference
Used in: KafkaStatus
| Property | Property type | Description |
|---|---|---|
state |
string (one of [RebalanceOnScaleUp, Idle, RebalanceOnScaleDown]) |
The current state of an auto-rebalancing operation. Possible values are:
|
lastTransitionTime |
string |
The timestamp of the latest auto-rebalancing state update. |
modes |
List of modes where an auto-rebalancing operation is either running or queued.
Each mode entry (
|
66. KafkaAutoRebalanceStatusBrokers schema reference
Used in: KafkaAutoRebalanceStatus
| Property | Property type | Description |
|---|---|---|
mode |
string (one of [remove-brokers, add-brokers]) |
Mode for which there is an auto-rebalancing operation in progress or queued, when brokers are added or removed. The possible modes are |
brokers |
integer array |
List of broker IDs involved in an auto-rebalancing operation related to the current mode. The list contains one of the following:
|
67. KafkaConnect schema reference
| Property | Property type | Description |
|---|---|---|
spec |
The specification of the Kafka Connect cluster. |
|
status |
The status of the Kafka Connect cluster. |
68. KafkaConnectSpec schema reference
Used in: KafkaConnect
Configures a Kafka Connect cluster.
68.1. Group ID and internal topics
The group ID and the internal topics used by the Kafka Connect cluster are configured in the .spec section of the KafkaConnect resource
Example group ID and internal topics configuration
apiVersion: kafka.strimzi.io/v1
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
groupId: my-connect-group
configStorageTopic: my-config-topic
offsetStorageTopic: my-offset-topic
statusStorageTopic: my-status-topic
# ...These fields are required in the v1 CRD API version.
In the v1beta2 version, these properties are optional.
If you do not set them, the following default values apply:
-
groupIddefaults toconnect-cluster -
configStorageTopicdefaults toconnect-cluster-configs -
offsetStorageTopicdefaults toconnect-cluster-offsets -
statusStorageTopicdefaults toconnect-cluster-status
68.2. Additional configuration
The config properties are one part of the overall configuration for the resource.
Use the config properties to configure additional Kafka Connect options as keys.
Example Kafka Connect configuration
apiVersion: kafka.strimzi.io/v1
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
config:
key.converter: org.apache.kafka.connect.json.JsonConverter
value.converter: org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable: true
value.converter.schemas.enable: true
config.storage.replication.factor: 3
offset.storage.replication.factor: 3
status.storage.replication.factor: 3
# ...The values can be one of the following JSON types:
-
String
-
Number
-
Boolean
Certain options have default values:
-
key.converterwith default valueorg.apache.kafka.connect.json.JsonConverter -
value.converterwith default valueorg.apache.kafka.connect.json.JsonConverter
These options are automatically configured in case they are not present in the KafkaConnect.spec.config properties.
Exceptions
You can specify and configure the options listed in the Kafka Connect configuration documentation.
However, Strimzi takes care of configuring and managing options related to the following, which cannot be changed:
-
Kafka cluster bootstrap address
-
Security (encryption, authentication, and authorization)
-
Listener and REST interface configuration
-
Plugin path configuration
Properties with the following prefixes cannot be set:
-
bootstrap.servers -
consumer.interceptor.classes -
listeners. -
plugin.path -
producer.interceptor.classes -
rest. -
sasl. -
security. -
ssl.
If the config property contains an option that cannot be changed, it is disregarded, and a warning message is logged to the Cluster Operator log file.
All other supported options are forwarded to Kafka Connect, including the following exceptions to the options configured by Strimzi:
-
Any
sslconfiguration for supported TLS versions and cipher suites
|
Important
|
The Cluster Operator does not validate keys or values in the config object provided.
If an invalid configuration is provided, the Kafka Connect cluster might not start or might become unstable.
In this case, fix the configuration so that the Cluster Operator can roll out the new configuration to all Kafka Connect nodes.
|
68.3. Logging
Kafka Connect has its own preconfigured loggers:
| Logger | Description | Default Level |
|---|---|---|
|
Default logger for all classes |
INFO |
|
Logs classpath scanning and metadata discovery used to find plugins |
ERROR |
Further loggers are added depending on the Kafka Connect plugins running.
Use a curl request to get a complete list of Kafka Connect loggers running from any Kafka broker pod:
curl -s http://<connect-cluster-name>-connect-api:8083/admin/loggers/Kafka Connect uses the Apache log4j2 logger implementation.
Use the logging property to configure loggers and logger levels.
You can set log levels using either the inline or external logging configuration types.
Specify loggers and levels directly in the custom resource for inline configuration:
Example inline logging configuration
apiVersion: kafka.strimzi.io/v1
kind: KafkaConnect
spec:
# ...
logging:
type: inline
loggers:
rootLogger.level: INFO
logger.reflections.level: DEBUG
# ...You can define additional loggers by specifying the full class or package name using logger.<name>.name.
For example, to configure logging for Kafka Connect runtime classes inline:
Example custom inline loggers
# ...
logger.sourcetask.name: org.apache.kafka.connect.runtime.WorkerSourceTask # (1)
logger.sourcetask.level: TRACE # (2)
logger.sinktask.name: org.apache.kafka.connect.runtime.WorkerSinkTask # (3)
logger.sinktask.level: DEBUG # (4)-
Creates a logger for the runtime
WorkerSourceTaskclass. -
Sets the logging level for
WorkerSourceTask. -
Creates a logger for the runtime
WorkerSinkTaskclass. -
Sets the logging level for
WorkerSinkTask.
Alternatively, you can reference an external ConfigMap containing a complete log4j2.properties file that defines your own log4j2 configuration, including loggers, appenders, and layout configuration:
Example external logging configuration
apiVersion: kafka.strimzi.io/v1
kind: KafkaConnect
spec:
# ...
logging:
type: external
valueFrom:
configMapKeyRef:
# name and key are mandatory
name: customConfigMap
key: log4j2.properties
# ...Garbage collector (GC)
Garbage collector logging can also be enabled (or disabled) using the jvmOptions property.
68.4. KafkaConnectSpec schema properties
| Property | Property type | Description |
|---|---|---|
version |
string |
The Kafka Connect version. Defaults to the latest version. Consult the user documentation to understand the process required to upgrade or downgrade the version. |
replicas |
integer |
The number of pods in the Kafka Connect group. Required in the |
image |
string |
The container image used for Kafka Connect pods. If no image name is explicitly specified, it is determined based on the |
bootstrapServers |
string |
Bootstrap servers to connect to. This should be given as a comma separated list of <hostname>:_<port>_ pairs. |
groupId |
string |
A unique ID that identifies the Connect cluster group. |
configStorageTopic |
string |
The name of the Kafka topic where connector configurations are stored. |
statusStorageTopic |
string |
The name of the Kafka topic where connector and task status are stored. |
offsetStorageTopic |
string |
The name of the Kafka topic where source connector offsets are stored. |
tls |
TLS configuration. |
|
authentication |
|
Authentication configuration for Kafka Connect. |
config |
map |
The Kafka Connect configuration. Properties with the following prefixes cannot be set: group.id, config.storage.topic, offset.storage.topic, status.storage.topic, ssl., sasl., security., listeners, plugin.path, rest., bootstrap.servers, consumer.interceptor.classes, producer.interceptor.classes, prometheus.metrics.reporter. (with the exception of: ssl.endpoint.identification.algorithm, ssl.cipher.suites, ssl.protocol, ssl.enabled.protocols). |
resources |
The maximum limits for CPU and memory resources and the requested initial resources. |
|
livenessProbe |
Pod liveness checking. |
|
readinessProbe |
Pod readiness checking. |
|
jvmOptions |
JVM Options for pods. |
|
jmxOptions |
JMX Options. |
|
logging |
Logging configuration for Kafka Connect. |
|
clientRackInitImage |
string |
The image of the init container used for initializing the |
rack |
Configuration of the node label which will be used as the |
|
metricsConfig |
Metrics configuration. |
|
tracing |
The configuration of tracing in Kafka Connect. |
|
template |
Template for Kafka Connect and Kafka MirrorMaker 2 resources. The template allows users to specify how the |
|
build |
Configures how the Connect container image should be built. Optional. |
|
plugins |
|
List of connector plugins to mount into the |
69. ClientTls schema reference
Used in: KafkaBridgeSpec, KafkaConnectSpec, KafkaMirrorMaker2ClusterSpec, KafkaMirrorMaker2TargetClusterSpec
Configures TLS trusted certificates for connecting KafkaConnect, KafkaBridge, KafkaMirrorMaker2 to the cluster.
69.1. ClientTls schema properties
| Property | Property type | Description |
|---|---|---|
trustedCertificates |
|
Trusted certificates for TLS connection. |
70. CertSecretSource schema reference
Used in: ClientTls
| Property | Property type | Description |
|---|---|---|
secretName |
string |
The name of the Secret containing the certificate. |
certificate |
string |
The name of the file certificate in the secret. |
pattern |
string |
Pattern for the certificate files in the secret. Use the glob syntax for the pattern. All files in the secret that match the pattern are used. |
71. KafkaClientAuthenticationTls schema reference
Used in: KafkaBridgeSpec, KafkaConnectSpec, KafkaMirrorMaker2ClusterSpec, KafkaMirrorMaker2TargetClusterSpec
To configure mTLS authentication, set the type property to the value tls.
mTLS uses a TLS certificate to authenticate.
The certificate is specified in the certificateAndKey property and is always loaded from a Kubernetes secret.
In the secret, the certificate must be stored in X509 format under two different keys: public and private.
Example mTLS configuration
authentication:
type: tls
certificateAndKey:
secretName: my-secret
certificate: my-public-tls-certificate-file.crt
key: private.keyYou can use the secrets created by the User Operator,
or you can create your own TLS certificate file, with the keys used for authentication, then create a Secret from the file:
kubectl create secret generic <my_tls_secret> \
--from-file=<my_public_tls_certificate>.crt \
--from-file=<my_private_key>.keyExample secret for mTLS client authentication
apiVersion: v1
kind: Secret
metadata:
name: my-tls-secret
type: Opaque
data:
tls.crt: LS0tLS1CRUdJTiBDRVJ...
tls.key: LS0tLS1CRUdJTiBQUkl...|
Note
|
mTLS authentication can only be used with TLS connections. |
71.1. KafkaClientAuthenticationTls schema properties
The type property is a discriminator that distinguishes use of the KafkaClientAuthenticationTls type from KafkaClientAuthenticationScramSha256, KafkaClientAuthenticationScramSha512, KafkaClientAuthenticationPlain, KafkaClientAuthenticationCustom.
It must have the value tls for the type KafkaClientAuthenticationTls.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
certificateAndKey |
Reference to the |
72. KafkaClientAuthenticationScramSha256 schema reference
Used in: KafkaBridgeSpec, KafkaConnectSpec, KafkaMirrorMaker2ClusterSpec, KafkaMirrorMaker2TargetClusterSpec
To configure SASL-based SCRAM-SHA-256 authentication, set the type property to scram-sha-256.
The SCRAM-SHA-256 authentication mechanism requires a username and password.
Example SASL-based SCRAM-SHA-256 client authentication configuration for Kafka Connect
authentication:
type: scram-sha-256
username: my-connect-username
passwordSecret:
secretName: my-connect-secret-name
password: my-connect-password-fieldIn the passwordSecret property, specify a link to a Secret containing the password.
You can use the secrets created by the User Operator.
If required, you can create a text file that contains the password, in cleartext, to use for authentication:
echo -n <password> > <my_password>.txtYou can then create a Secret from the text file, setting your own field name (key) for the password:
kubectl create secret generic <my-connect-secret-name> --from-file=<my_password_field_name>=./<my_password>.txtExample secret for SCRAM-SHA-256 client authentication for Kafka Connect
apiVersion: v1
kind: Secret
metadata:
name: my-connect-secret-name
type: Opaque
data:
my-connect-password-field: LFTIyFRFlMmU2N2TmThe secretName property contains the name of the Secret, and the password property contains the name of the key under which the password is stored inside the Secret.
|
Important
|
Do not specify the actual password in the password property.
|
72.1. KafkaClientAuthenticationScramSha256 schema properties
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
username |
string |
Username used for the authentication. |
passwordSecret |
Reference to the |
73. PasswordSecretSource schema reference
Used in: KafkaClientAuthenticationPlain, KafkaClientAuthenticationScramSha256, KafkaClientAuthenticationScramSha512
| Property | Property type | Description |
|---|---|---|
secretName |
string |
The name of the Secret containing the password. |
password |
string |
The name of the key in the Secret under which the password is stored. |
74. KafkaClientAuthenticationScramSha512 schema reference
Used in: KafkaBridgeSpec, KafkaConnectSpec, KafkaMirrorMaker2ClusterSpec, KafkaMirrorMaker2TargetClusterSpec
To configure SASL-based SCRAM-SHA-512 authentication, set the type property to scram-sha-512.
The SCRAM-SHA-512 authentication mechanism requires a username and password.
Example SASL-based SCRAM-SHA-512 client authentication configuration for Kafka Connect
authentication:
type: scram-sha-512
username: my-connect-username
passwordSecret:
secretName: my-connect-secret-name
password: my-connect-password-fieldIn the passwordSecret property, specify a link to a Secret containing the password.
You can use the secrets created by the User Operator.
If required, you can create a text file that contains the password, in cleartext, to use for authentication:
echo -n <password> > <my_password>.txtYou can then create a Secret from the text file, setting your own field name (key) for the password:
kubectl create secret generic <my-connect-secret-name> --from-file=<my_password_field_name>=./<my_password>.txtExample secret for SCRAM-SHA-512 client authentication for Kafka Connect
apiVersion: v1
kind: Secret
metadata:
name: my-connect-secret-name
type: Opaque
data:
my-connect-password-field: LFTIyFRFlMmU2N2TmThe secretName property contains the name of the Secret, and the password property contains the name of the key under which the password is stored inside the Secret.
|
Important
|
Do not specify the actual password in the password property.
|
74.1. KafkaClientAuthenticationScramSha512 schema properties
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
username |
string |
Username used for the authentication. |
passwordSecret |
Reference to the |
75. KafkaClientAuthenticationPlain schema reference
Used in: KafkaBridgeSpec, KafkaConnectSpec, KafkaMirrorMaker2ClusterSpec, KafkaMirrorMaker2TargetClusterSpec
To configure SASL-based PLAIN authentication, set the type property to plain.
The SASL PLAIN authentication mechanism requires a username and password.
An example SASL-based PLAIN client authentication configuration for Kafka Connect
authentication:
type: plain
username: my-connect-username
passwordSecret:
secretName: my-connect-secret-name
password: my-password-field-name|
Warning
|
The SASL PLAIN mechanism will transfer the username and password across the network in cleartext. Only use SASL PLAIN authentication if TLS encryption is enabled. |
In the passwordSecret property, specify a link to a Secret containing the password.
You can use the secrets created by the User Operator.
If required, create a text file that contains the password, in cleartext, to use for authentication:
echo -n <password> > <my_password>.txtYou can then create a Secret from the text file, setting your own field name (key) for the password:
kubectl create secret generic <my-connect-secret-name> --from-file=<my_password_field_name>=./<my_password>.txtExample secret for PLAIN client authentication for Kafka Connect
apiVersion: v1
kind: Secret
metadata:
name: my-connect-secret-name
type: Opaque
data:
my-password-field-name: LFTIyFRFlMmU2N2TmThe secretName property contains the name of the Secret and the password property contains the name of the key under which the password is stored inside the Secret.
|
Important
|
Do not specify the actual password in the password property.
|
75.1. KafkaClientAuthenticationPlain schema properties
The type property is a discriminator that distinguishes use of the KafkaClientAuthenticationPlain type from KafkaClientAuthenticationTls, KafkaClientAuthenticationScramSha256, KafkaClientAuthenticationScramSha512, KafkaClientAuthenticationCustom.
It must have the value plain for the type KafkaClientAuthenticationPlain.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
username |
string |
Username used for the authentication. |
passwordSecret |
Reference to the |
76. KafkaClientAuthenticationCustom schema reference
Used in: KafkaBridgeSpec, KafkaConnectSpec, KafkaMirrorMaker2ClusterSpec, KafkaMirrorMaker2TargetClusterSpec
To configure custom client authentication, set the type property to custom.
Custom client authentication allows you to use any type of Kafka-supported authentication mechanism.
This authentication option is especially useful with third-party Apache Kafka services, such as Amazon MSK, that require their own authentication mechanisms.
Example custom client authentication configuration using the
AWS_MSK_IAM authentication authentication:
type: custom
sasl: true
config:
sasl.mechanism: AWS_MSK_IAM
sasl.jaas.config: software.amazon.msk.auth.iam.IAMLoginModule required;
sasl.client.callback.handler.class: software.amazon.msk.auth.iam.IAMClientCallbackHandlerThe config section accepts only options that start with the prefixes sasl. and ssl.keystore..
All other options are ignored.
To configure additional options, use the related properties of the Strimzi custom resource, such as .spec.config or .spec.tls.
The security.protocol `setting is generated automatically from the `sasl property (when you use custom authentication) and the tls configuration in the same Strimzi custom resource:
-
SASL = True, TLS = True → SASL_SSL
-
SASL = False, TLS = True → SSL
-
SASL = True, TLS = False → SASL_PLAINTEXT
-
SASL = False, TLS = False → PLAINTEXT
76.1. Using secrets in custom authentication
If your custom authentication mechanism requires additional information from Secret or ConfigMap resources, use the Additional Volumes feature to mount them into the operands.
Kafka configuration providers can be used to load them from the disk.
76.2. Using additional authentication plugins
Custom authentication mechanisms might require additional plugins for the operand. You can add them using the Additional Volumes feature. Alternatively, you can build a custom container image.
76.3. KafkaClientAuthenticationCustom schema properties
The type property is a discriminator that distinguishes use of the KafkaClientAuthenticationCustom type from KafkaClientAuthenticationTls, KafkaClientAuthenticationScramSha256, KafkaClientAuthenticationScramSha512, KafkaClientAuthenticationPlain.
It must have the value custom for the type KafkaClientAuthenticationCustom.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
sasl |
boolean |
Enable or disable SASL on this authentication mechanism. |
config |
map |
Configuration for the custom authentication mechanism. Only properties with the |
77. OpenTelemetryTracing schema reference
Used in: KafkaBridgeSpec, KafkaConnectSpec, KafkaMirrorMaker2Spec
The type property is a discriminator that distinguishes use of the OpenTelemetryTracing type from other subtypes that may be added in the future.
It must have the value opentelemetry for the type OpenTelemetryTracing.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
78. KafkaConnectTemplate schema reference
Used in: KafkaConnectSpec, KafkaMirrorMaker2Spec
| Property | Property type | Description |
|---|---|---|
podSet |
Template for Kafka Connect |
|
pod |
Template for Kafka Connect |
|
apiService |
Template for Kafka Connect API |
|
headlessService |
Template for Kafka Connect headless |
|
connectContainer |
Template for the Kafka Connect container. |
|
initContainer |
Template for the Kafka init container. |
|
podDisruptionBudget |
Template for Kafka Connect |
|
serviceAccount |
Template for the Kafka Connect service account. |
|
clusterRoleBinding |
Template for the Kafka Connect ClusterRoleBinding. |
|
buildPod |
Template for Kafka Connect Build |
|
buildContainer |
Template for the Kafka Connect Build container. The build container is used only on Kubernetes. |
|
buildConfig |
Template for the Kafka Connect BuildConfig used to build new container images. The BuildConfig is used only on OpenShift. |
|
buildServiceAccount |
Template for the Kafka Connect Build service account. |
|
jmxSecret |
Template for Secret of the Kafka Connect Cluster JMX authentication. |
79. BuildConfigTemplate schema reference
Used in: KafkaConnectTemplate
| Property | Property type | Description |
|---|---|---|
metadata |
Metadata to apply to the |
|
pullSecret |
string |
Container Registry Secret with the credentials for pulling the base image. |
80. Build schema reference
Used in: KafkaConnectSpec
Configures additional connectors for Kafka Connect deployments.
80.1. Configuring container registries
To build new container images with additional connector plugins, Strimzi requires a container registry where the images can be pushed to, stored, and pulled from.
Strimzi does not run its own container registry, so a registry must be provided.
Strimzi supports private container registries as well as public registries such as Quay or Docker Hub.
The container registry is configured in the .spec.build.output section of the KafkaConnect custom resource.
The output configuration, which is required, supports two types: docker and imagestream.
Using Docker registry
To use a Docker registry, you have to specify the type as docker, and the image field with the full name of the new container image.
The full name must include:
-
The address of the registry
-
Port number (if listening on a non-standard port)
-
The tag of the new container image
Example valid container image names:
-
docker.io/my-org/my-image/my-tag -
quay.io/my-org/my-image/my-tag -
image-registry.image-registry.svc:5000/myproject/kafka-connect-build:latest
Each Kafka Connect deployment must use a separate image, which can mean different tags at the most basic level.
If the registry requires authentication, use the pushSecret to set a name of the Secret with the registry credentials.
For the Secret, use the kubernetes.io/dockerconfigjson type and a .dockerconfigjson file to contain the Docker credentials.
For more information on pulling an image from a private registry, see Create a Secret based on existing Docker credentials.
Example
output configurationapiVersion: kafka.strimzi.io/v1
kind: KafkaConnect
metadata:
name: my-connect-cluster
spec:
#...
build:
output:
type: docker # (1)
image: my-registry.io/my-org/my-connect-cluster:latest # (2)
pushSecret: my-registry-credentials # (3)
#...-
(Required) Type of output used by Strimzi.
-
(Required) Full name of the image used, including the repository and tag.
-
(Optional) Name of the secret with the container registry credentials.
Using OpenShift ImageStream
Instead of Docker, you can use OpenShift ImageStream to store a new container image.
The ImageStream has to be created manually before deploying Kafka Connect.
To use ImageStream, set the type to imagestream, and use the image property to specify the name of the ImageStream and the tag used.
For example, my-connect-image-stream:latest.
Example
output configurationapiVersion: kafka.strimzi.io/v1
kind: KafkaConnect
metadata:
name: my-connect-cluster
spec:
#...
build:
output:
type: imagestream # (1)
image: my-connect-build:latest # (2)
#...-
(Required) Type of output used by Strimzi.
-
(Required) Name of the ImageStream and tag.
80.2. Configuring connector plugins
Connector plugins are a set of files that define the implementation required to connect to certain types of external system.
The connector plugins required for a container image must be configured using the .spec.build.plugins property of the KafkaConnect custom resource.
Each connector plugin must have a name which is unique within the Kafka Connect deployment.
Additionally, the plugin artifacts must be listed.
These artifacts are downloaded by Strimzi, added to the new container image, and used in the Kafka Connect deployment.
The connector plugin artifacts can also include additional components, such as (de)serializers.
Each connector plugin is downloaded into a separate directory so that the different connectors and their dependencies are properly sandboxed.
Each plugin must be configured with at least one artifact.
Example
plugins configuration with two connector pluginsapiVersion: kafka.strimzi.io/v1
kind: KafkaConnect
metadata:
name: my-connect-cluster
spec:
#...
build:
output:
#...
plugins: # (1)
- name: connector-1
artifacts:
- type: tgz
url: <url_to_download_connector_1_artifact>
sha512sum: <SHA-512_checksum_of_connector_1_artifact>
- name: connector-2
artifacts:
- type: jar
url: <url_to_download_connector_2_artifact>
sha512sum: <SHA-512_checksum_of_connector_2_artifact>
#...-
(Required) List of connector plugins and their artifacts.
Strimzi supports the following types of artifacts:
-
JAR files, which are downloaded and used directly
-
TGZ archives, which are downloaded and unpacked
-
ZIP archives, which are downloaded and unpacked
-
Maven artifacts, which uses Maven coordinates
-
Other artifacts, which are downloaded and used directly
|
Important
|
Strimzi does not perform any security scanning of the downloaded artifacts. For security reasons, you should first verify the artifacts manually, and configure the checksum verification to make sure the same artifact is used in the automated build and in the Kafka Connect deployment. |
Using JAR artifacts
JAR artifacts represent a JAR file that is downloaded and added to a container image.
To use a JAR artifacts, set the type property to jar, and specify the download location using the url property.
Additionally, you can specify a SHA-512 checksum of the artifact. If specified, Strimzi will verify the checksum of the artifact while building the new container image.
Example JAR artifact
apiVersion: kafka.strimzi.io/v1
kind: KafkaConnect
metadata:
name: my-connect-cluster
spec:
#...
build:
output:
#...
plugins:
- name: my-plugin
artifacts:
- type: jar # (1)
url: https://my-domain.tld/my-jar.jar # (2)
sha512sum: 589...ab4 # (3)
- type: jar
url: https://my-domain.tld/my-jar2.jar
#...-
(Required) Type of artifact.
-
(Required) URL from which the artifact is downloaded.
-
(Optional) SHA-512 checksum to verify the artifact.
Using TGZ artifacts
TGZ artifacts are used to download TAR archives that have been compressed using Gzip compression.
The TGZ artifact can contain the whole Kafka Connect connector, even when comprising multiple different files.
The TGZ artifact is automatically downloaded and unpacked by Strimzi while building the new container image.
To use TGZ artifacts, set the type property to tgz, and specify the download location using the url property.
Additionally, you can specify a SHA-512 checksum of the artifact. If specified, Strimzi will verify the checksum before unpacking it and building the new container image.
Example TGZ artifact
apiVersion: kafka.strimzi.io/v1
kind: KafkaConnect
metadata:
name: my-connect-cluster
spec:
#...
build:
output:
#...
plugins:
- name: my-plugin
artifacts:
- type: tgz # (1)
url: https://my-domain.tld/my-connector-archive.tgz # (2)
sha512sum: 158...jg10 # (3)
#...-
(Required) Type of artifact.
-
(Required) URL from which the archive is downloaded.
-
(Optional) SHA-512 checksum to verify the artifact.
Using ZIP artifacts
ZIP artifacts are used to download ZIP compressed archives.
Use ZIP artifacts in the same way as the TGZ artifacts described in the previous section.
The only difference is you specify type: zip instead of type: tgz.
Using Maven artifacts
maven artifacts are used to specify connector plugin artifacts as Maven coordinates.
The Maven coordinates identify plugin artifacts and dependencies so that they can be located and fetched from a Maven repository.
|
Note
|
The Maven repository must be accessible for the connector build process to add the artifacts to the container image. |
Example Maven artifact
apiVersion: kafka.strimzi.io/v1
kind: KafkaConnect
metadata:
name: my-connect-cluster
spec:
#...
build:
output:
#...
plugins:
- name: my-plugin
artifacts:
- type: maven # (1)
repository: https://mvnrepository.com # (2)
group: <maven_group> # (3)
artifact: <maven_artifact> # (4)
version: <maven_version_number> # (5)
#...-
(Required) Type of artifact.
-
(Optional) Maven repository to download the artifacts from. If you do not specify a repository, Maven Central repository is used by default.
-
(Required) Maven group ID.
-
(Required) Maven artifact type.
-
(Required) Maven version number.
Using
other artifactsother artifacts represent any kind of file that is downloaded and added to a container image.
If you want to use a specific name for the artifact in the resulting container image, use the fileName field.
If a file name is not specified, the file is named based on the URL hash.
Additionally, you can specify a SHA-512 checksum of the artifact. If specified, Strimzi will verify the checksum of the artifact while building the new container image.
Example
other artifactapiVersion: kafka.strimzi.io/v1
kind: KafkaConnect
metadata:
name: my-connect-cluster
spec:
#...
build:
output:
#...
plugins:
- name: my-plugin
artifacts:
- type: other # (1)
url: https://my-domain.tld/my-other-file.ext # (2)
sha512sum: 589...ab4 # (3)
fileName: name-the-file.ext # (4)
#...-
(Required) Type of artifact.
-
(Required) URL from which the artifact is downloaded.
-
(Optional) SHA-512 checksum to verify the artifact.
-
(Optional) The name under which the file is stored in the resulting container image.
80.3. Build schema properties
| Property | Property type | Description |
|---|---|---|
output |
Configures where should the newly built image be stored. Required. |
|
plugins |
|
List of connector plugins which should be added to the Kafka Connect. Required. |
resources |
CPU and memory resources to reserve for the build. |
81. DockerOutput schema reference
Used in: Build
The type property is a discriminator that distinguishes use of the DockerOutput type from ImageStreamOutput.
It must have the value docker for the type DockerOutput.
| Property | Property type | Description |
|---|---|---|
image |
string |
The full name which should be used for tagging and pushing the newly built image. For example |
pushSecret |
string |
Container Registry Secret with the credentials for pushing the newly built image. |
additionalBuildOptions |
string array |
Configures additional options to pass to the |
additionalPushOptions |
string array |
Configures additional options to pass to the Buildah |
type |
string |
Must be |
82. ImageStreamOutput schema reference
Used in: Build
The type property is a discriminator that distinguishes use of the ImageStreamOutput type from DockerOutput.
It must have the value imagestream for the type ImageStreamOutput.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
image |
string |
The name and tag of the ImageStream where the newly built image will be pushed. For example |
83. Plugin schema reference
Used in: Build
| Property | Property type | Description |
|---|---|---|
name |
string |
The unique name of the connector plugin. Will be used to generate the path where the connector artifacts will be stored. The name has to be unique within the KafkaConnect resource. The name has to follow the following pattern: |
artifacts |
|
List of artifacts which belong to this connector plugin. Required. |
84. JarArtifact schema reference
Used in: Plugin
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
url |
string |
URL of the artifact which will be downloaded. Strimzi does not do any security scanning of the downloaded artifacts. For security reasons, you should first verify the artifacts manually and configure the checksum verification to make sure the same artifact is used in the automated build. Required for |
sha512sum |
string |
SHA512 checksum of the artifact. Optional. If specified, the checksum will be verified while building the new container. If not specified, the downloaded artifact will not be verified. Not applicable to the |
insecure |
boolean |
By default, connections using TLS are verified to check they are secure. The server certificate used must be valid, trusted, and contain the server name. By setting this option to |
85. TgzArtifact schema reference
Used in: Plugin
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
url |
string |
URL of the artifact which will be downloaded. Strimzi does not do any security scanning of the downloaded artifacts. For security reasons, you should first verify the artifacts manually and configure the checksum verification to make sure the same artifact is used in the automated build. Required for |
sha512sum |
string |
SHA512 checksum of the artifact. Optional. If specified, the checksum will be verified while building the new container. If not specified, the downloaded artifact will not be verified. Not applicable to the |
insecure |
boolean |
By default, connections using TLS are verified to check they are secure. The server certificate used must be valid, trusted, and contain the server name. By setting this option to |
86. ZipArtifact schema reference
Used in: Plugin
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
url |
string |
URL of the artifact which will be downloaded. Strimzi does not do any security scanning of the downloaded artifacts. For security reasons, you should first verify the artifacts manually and configure the checksum verification to make sure the same artifact is used in the automated build. Required for |
sha512sum |
string |
SHA512 checksum of the artifact. Optional. If specified, the checksum will be verified while building the new container. If not specified, the downloaded artifact will not be verified. Not applicable to the |
insecure |
boolean |
By default, connections using TLS are verified to check they are secure. The server certificate used must be valid, trusted, and contain the server name. By setting this option to |
87. MavenArtifact schema reference
Used in: Plugin
The type property is a discriminator that distinguishes use of the MavenArtifact type from JarArtifact, TgzArtifact, ZipArtifact, OtherArtifact.
It must have the value maven for the type MavenArtifact.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
repository |
string |
Maven repository to download the artifact from. Applicable to the |
group |
string |
Maven group id. Applicable to the |
artifact |
string |
Maven artifact id. Applicable to the |
version |
string |
Maven version number. Applicable to the |
insecure |
boolean |
By default, connections using TLS are verified to check they are secure. The server certificate used must be valid, trusted, and contain the server name. By setting this option to |
88. OtherArtifact schema reference
Used in: Plugin
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
url |
string |
URL of the artifact which will be downloaded. Strimzi does not do any security scanning of the downloaded artifacts. For security reasons, you should first verify the artifacts manually and configure the checksum verification to make sure the same artifact is used in the automated build. Required for |
sha512sum |
string |
SHA512 checksum of the artifact. Optional. If specified, the checksum will be verified while building the new container. If not specified, the downloaded artifact will not be verified. Not applicable to the |
fileName |
string |
Name under which the artifact will be stored. |
insecure |
boolean |
By default, connections using TLS are verified to check they are secure. The server certificate used must be valid, trusted, and contain the server name. By setting this option to |
89. MountedPlugin schema reference
Used in: KafkaConnectSpec
|
Important
|
This feature requires Kubernetes support for the Image Volume feature. |
89.1. MountedPlugin schema properties
| Property | Property type | Description |
|---|---|---|
name |
string |
A unique name for the connector plugin. This name is used to generate the mount path for the connector artifacts. The name has to be unique within the KafkaConnect resource. The name must be unique within the |
artifacts |
|
List of artifacts associated with this connector plugin. Required. |
90. ImageArtifact schema reference
Used in: MountedPlugin
The type property is a discriminator that distinguishes use of the ImageArtifact type from other subtypes that may be added in the future.
It must have the value image for the type ImageArtifact.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
reference |
string |
Reference to the container image (OCI artifact) containing the Kafka Connect plugin. The image is mounted as a volume and provides the plugin binary. Required. |
pullPolicy |
string |
Policy that determines when the container image (OCI artifact) is pulled. Possible values are:
Defaults to |
91. KafkaConnectStatus schema reference
Used in: KafkaConnect
| Property | Property type | Description |
|---|---|---|
conditions |
|
List of status conditions. |
observedGeneration |
integer |
The generation of the CRD that was last reconciled by the operator. |
url |
string |
The URL of the REST API endpoint for managing and monitoring Kafka Connect connectors. |
connectorPlugins |
|
The list of connector plugins available in this Kafka Connect deployment. |
replicas |
integer |
The current number of pods being used to provide this resource. |
labelSelector |
string |
Label selector for pods providing this resource. |
92. ConnectorPlugin schema reference
Used in: KafkaConnectStatus, KafkaMirrorMaker2Status
| Property | Property type | Description |
|---|---|---|
class |
string |
The class of the connector plugin. |
type |
string |
The type of the connector plugin. The available types are |
version |
string |
The version of the connector plugin. |
93. KafkaTopic schema reference
| Property | Property type | Description |
|---|---|---|
spec |
The specification of the topic. |
|
status |
The status of the topic. |
94. KafkaTopicSpec schema reference
Used in: KafkaTopic
| Property | Property type | Description |
|---|---|---|
topicName |
string |
The name of the topic. When absent this will default to the metadata.name of the topic. It is recommended to not set this unless the topic name is not a valid Kubernetes resource name. |
partitions |
integer |
The number of partitions the topic should have. This cannot be decreased after topic creation. It can be increased after topic creation, but it is important to understand the consequences that has, especially for topics with semantic partitioning. When absent this will default to the broker configuration for |
replicas |
integer |
The number of replicas the topic should have. When absent this will default to the broker configuration for |
config |
map |
The topic configuration. |
95. KafkaTopicStatus schema reference
Used in: KafkaTopic
| Property | Property type | Description |
|---|---|---|
conditions |
|
List of status conditions. |
observedGeneration |
integer |
The generation of the CRD that was last reconciled by the operator. |
topicName |
string |
Topic name. |
topicId |
string |
The topic’s id. For a KafkaTopic with the ready condition, this will change only if the topic gets deleted and recreated with the same name. |
replicasChange |
Replication factor change status. |
96. ReplicasChangeStatus schema reference
Used in: KafkaTopicStatus
| Property | Property type | Description |
|---|---|---|
targetReplicas |
integer |
The target replicas value requested by the user. This may be different from .spec.replicas when a change is ongoing. |
state |
string (one of [ongoing, pending]) |
Current state of the replicas change operation. This can be |
message |
string |
Message for the user related to the replicas change request. This may contain transient error messages that would disappear on periodic reconciliations. |
sessionId |
string |
The session identifier for replicas change requests pertaining to this KafkaTopic resource. This is used by the Topic Operator to track the status of |
97. KafkaUser schema reference
| Property | Property type | Description |
|---|---|---|
spec |
The specification of the user. |
|
status |
The status of the Kafka User. |
98. KafkaUserSpec schema reference
Used in: KafkaUser
| Property | Property type | Description |
|---|---|---|
authentication |
|
Authentication mechanism enabled for this Kafka user. The supported authentication mechanisms are
Authentication is optional. If authentication is not configured, no credentials are generated. ACLs and quotas set for the user are configured in the |
authorization |
Authorization rules for this Kafka user. |
|
quotas |
Quotas on requests to control the broker resources used by clients. Network bandwidth and request rate quotas can be enforced. For more information, see the Apache Kafka design documentation about quotas. |
|
template |
Template to specify how Kafka User |
99. KafkaUserTlsClientAuthentication schema reference
Used in: KafkaUserSpec
The type property is a discriminator that distinguishes use of the KafkaUserTlsClientAuthentication type from KafkaUserTlsExternalClientAuthentication, KafkaUserScramSha512ClientAuthentication.
It must have the value tls for the type KafkaUserTlsClientAuthentication.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
100. KafkaUserTlsExternalClientAuthentication schema reference
Used in: KafkaUserSpec
The type property is a discriminator that distinguishes use of the KafkaUserTlsExternalClientAuthentication type from KafkaUserTlsClientAuthentication, KafkaUserScramSha512ClientAuthentication.
It must have the value tls-external for the type KafkaUserTlsExternalClientAuthentication.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
101. KafkaUserScramSha512ClientAuthentication schema reference
Used in: KafkaUserSpec
The type property is a discriminator that distinguishes use of the KafkaUserScramSha512ClientAuthentication type from KafkaUserTlsClientAuthentication, KafkaUserTlsExternalClientAuthentication.
It must have the value scram-sha-512 for the type KafkaUserScramSha512ClientAuthentication.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
password |
Specify the password for the user. If not set, a new password is generated by the User Operator. |
102. Password schema reference
| Property | Property type | Description |
|---|---|---|
valueFrom |
Secret from which the password should be read. |
103. KafkaUserAuthorizationSimple schema reference
Used in: KafkaUserSpec
The type property is a discriminator that distinguishes use of the KafkaUserAuthorizationSimple type from other subtypes that may be added in the future.
It must have the value simple for the type KafkaUserAuthorizationSimple.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
acls |
|
List of ACL rules which should be applied to this user. |
104. AclRule schema reference
Used in: KafkaUserAuthorizationSimple
Configures access control rules for a KafkaUser when brokers are using simple authorization.
Example
KafkaUser configuration with simple authorizationapiVersion: kafka.strimzi.io/v1
kind: KafkaUser
metadata:
name: my-user
labels:
strimzi.io/cluster: my-cluster
spec:
# ...
authorization:
type: simple
acls:
- resource:
type: topic
name: "*"
patternType: literal
operations:
- Read
- Describe
- resource:
type: group
name: my-group
patternType: prefix
operations:
- ReadUse the resource property to specify the resource that the rule applies to.
Simple authorization supports four resource types, which are specified in the type property:
-
Topics (
topic) -
Consumer Groups (
group) -
Clusters (
cluster) -
Transactional IDs (
transactionalId)
For Topic, Group, and Transactional ID resources you can specify the name of the resource the rule applies to in the name property.
Cluster type resources have no name.
A name is specified as a literal or a prefix using the patternType property.
-
Literal names are taken exactly as they are specified in the
namefield. -
Prefix names use the
namevalue as a prefix and then apply the rule to all resources with names starting with that value.
When patternType is set as literal, you can set the name to * to indicate that the rule applies to all resources.
For more details about simple authorization, ACLs, and supported combinations of resources and operations, see Authorization and ACLs.
104.1. AclRule schema properties
| Property | Property type | Description |
|---|---|---|
type |
string (one of [allow, deny]) |
The type of the rule. ACL rules with type |
resource |
|
Indicates the resource for which given ACL rule applies. |
host |
string |
The host from which the action described in the ACL rule is allowed or denied. If not set, it defaults to |
operations |
string (one or more of [Read, Write, Delete, Alter, Describe, All, IdempotentWrite, ClusterAction, Create, AlterConfigs, DescribeConfigs]) array |
List of operations to allow or deny. Supported operations are: Read, Write, Create, Delete, Alter, Describe, ClusterAction, AlterConfigs, DescribeConfigs, IdempotentWrite and All. Only certain operations work with the specified resource. |
105. AclRuleTopicResource schema reference
Used in: AclRule
The type property is a discriminator that distinguishes use of the AclRuleTopicResource type from AclRuleGroupResource, AclRuleClusterResource, AclRuleTransactionalIdResource.
It must have the value topic for the type AclRuleTopicResource.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
name |
string |
Name of resource for which given ACL rule applies. Can be combined with |
patternType |
string (one of [prefix, literal]) |
Describes the pattern used in the resource field. The supported types are |
106. AclRuleGroupResource schema reference
Used in: AclRule
The type property is a discriminator that distinguishes use of the AclRuleGroupResource type from AclRuleTopicResource, AclRuleClusterResource, AclRuleTransactionalIdResource.
It must have the value group for the type AclRuleGroupResource.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
name |
string |
Name of resource for which given ACL rule applies. Can be combined with |
patternType |
string (one of [prefix, literal]) |
Describes the pattern used in the resource field. The supported types are |
107. AclRuleClusterResource schema reference
Used in: AclRule
The type property is a discriminator that distinguishes use of the AclRuleClusterResource type from AclRuleTopicResource, AclRuleGroupResource, AclRuleTransactionalIdResource.
It must have the value cluster for the type AclRuleClusterResource.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
108. AclRuleTransactionalIdResource schema reference
Used in: AclRule
The type property is a discriminator that distinguishes use of the AclRuleTransactionalIdResource type from AclRuleTopicResource, AclRuleGroupResource, AclRuleClusterResource.
It must have the value transactionalId for the type AclRuleTransactionalIdResource.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
name |
string |
Name of resource for which given ACL rule applies. Can be combined with |
patternType |
string (one of [prefix, literal]) |
Describes the pattern used in the resource field. The supported types are |
109. KafkaUserQuotas schema reference
Used in: KafkaUserSpec
Configure clients to use quotas so that a user does not overload Kafka brokers.
Example Kafka user quota configuration
spec:
quotas:
producerByteRate: 1048576
consumerByteRate: 2097152
requestPercentage: 55
controllerMutationRate: 10For more information, see the Apache Kafka design documentation.
109.1. KafkaUserQuotas schema properties
| Property | Property type | Description |
|---|---|---|
producerByteRate |
integer |
A quota on the maximum bytes per-second that each client group can publish to a broker before the clients in the group are throttled. Defined on a per-broker basis. |
consumerByteRate |
integer |
A quota on the maximum bytes per-second that each client group can fetch from a broker before the clients in the group are throttled. Defined on a per-broker basis. |
requestPercentage |
integer |
A quota on the maximum CPU utilization of each client group as a percentage of network and I/O threads. |
controllerMutationRate |
number |
A quota on the rate at which mutations are accepted for the create topics request, the create partitions request and the delete topics request. The rate is accumulated by the number of partitions created or deleted. |
110. KafkaUserTemplate schema reference
Used in: KafkaUserSpec
Specify additional labels and annotations for the secret created by the User Operator.
An example showing the
KafkaUserTemplateapiVersion: kafka.strimzi.io/v1
kind: KafkaUser
metadata:
name: my-user
labels:
strimzi.io/cluster: my-cluster
spec:
authentication:
type: tls
template:
secret:
metadata:
labels:
label1: value1
annotations:
anno1: value1
# ...110.1. KafkaUserTemplate schema properties
| Property | Property type | Description |
|---|---|---|
secret |
Template for KafkaUser resources. The template allows users to specify how the |
112. KafkaBridge schema reference
| Property | Property type | Description |
|---|---|---|
spec |
The specification of the HTTP Bridge. |
|
status |
The status of the HTTP Bridge. |
113. KafkaBridgeSpec schema reference
Used in: KafkaBridge
Configures a HTTP Bridge cluster.
Configuration options relate to:
-
Kafka cluster bootstrap address
-
Security (encryption, authentication, and authorization)
-
Consumer configuration
-
Producer configuration
-
HTTP configuration
113.1. Logging
HTTP Bridge has its own preconfigured loggers:
| Logger | Description | Default Level |
|---|---|---|
|
Default logger for all classes |
INFO |
|
All classes in the |
INFO |
|
Uses |
WARN |
|
Uses |
WARN |
You can configure log levels directly for these loggers. For example:
apiVersion: kafka.strimzi.io/v1
kind: KafkaBridge
spec:
# ...
logging:
type: inline
loggers:
rootLogger.level: INFO
logger.ready.level: DEBUG
# ...You can also specify custom loggers for other operations:
-
createConsumer -
deleteConsumer -
subscribe -
unsubscribe -
poll -
assign -
commit -
send -
sendToPartition -
seekToBeginning -
seekToEnd -
seek -
openapi
Each operation maps to an API endpoint, defined according to the OpenAPI specification, and supports fine-grained logging via http.openapi.operation.<operation_id>.
For example, to set the logging level for the send operation logger:
apiVersion: kafka.strimzi.io/v1
kind: KafkaBridge
spec:
# ...
logging:
type: inline
loggers:
logger.send.name: http.openapi.operation.send
logger.send.level: DEBUG
# ...HTTP Bridge uses the Apache log4j2 logger implementation.
Use the logging property to configure loggers and logger levels.
You can set log levels using either the inline or external logging configuration types.
Specify loggers and levels directly in the custom resource for inline configuration:
Example inline logging configuration
apiVersion: kafka.strimzi.io/v1
kind: KafkaBridge
spec:
# ...
logging:
type: inline
loggers:
rootLogger.level: INFO
# enabling DEBUG for send operation
logger.send.name: http.openapi.operation.send
logger.send.level: DEBUG
# ...Alternatively, you can reference an external ConfigMap containing a complete log4j2.properties file that defines your own log4j2 configuration, including loggers, appenders, and layout configuration:
Example external logging configuration
apiVersion: kafka.strimzi.io/v1
kind: KafkaBridge
spec:
# ...
logging:
type: external
valueFrom:
configMapKeyRef:
# name and key are mandatory
name: customConfigMap
key: log4j2.properties
# ...Garbage collector (GC)
Garbage collector logging can also be enabled (or disabled) using the jvmOptions property.
113.2. KafkaBridgeSpec schema properties
| Property | Property type | Description |
|---|---|---|
replicas |
integer |
The number of pods in the |
image |
string |
The container image used for HTTP Bridge pods. If no image name is explicitly specified, the image name corresponds to the image specified in the Cluster Operator configuration. If an image name is not defined in the Cluster Operator configuration, a default value is used. |
bootstrapServers |
string |
A list of host:port pairs for establishing the initial connection to the Kafka cluster. |
tls |
TLS configuration for connecting HTTP Bridge to the cluster. |
|
authentication |
|
Authentication configuration for connecting to the cluster. |
http |
The HTTP related configuration. |
|
adminClient |
Kafka AdminClient related configuration. |
|
consumer |
Kafka consumer related configuration. |
|
producer |
Kafka producer related configuration. |
|
resources |
CPU and memory resources to reserve. |
|
jvmOptions |
JVM Options for pods. |
|
logging |
Logging configuration for HTTP Bridge. |
|
clientRackInitImage |
string |
The image of the init container used for initializing the |
rack |
Configuration of the node label which will be used as the client.rack consumer configuration. |
|
metricsConfig |
Metrics configuration. |
|
livenessProbe |
Pod liveness checking. |
|
readinessProbe |
Pod readiness checking. |
|
template |
Template for HTTP Bridge resources. The template allows users to specify how a |
|
tracing |
The configuration of tracing in HTTP Bridge. |
|
config |
map |
Additional configuration for the HTTP bridge. The following prefixes cannot be set: kafka., http., bridge.metrics. The following options cannot be set: bridge.id, bridge.tracing, bridge.metrics. |
114. KafkaBridgeHttpConfig schema reference
Used in: KafkaBridgeSpec
Configures HTTP access to a Kafka cluster for the HTTP Bridge. The default HTTP configuration is for the HTTP Bridge to listen on port 8080.
Example HTTP Bridge HTTP configuration
apiVersion: kafka.strimzi.io/v1
kind: KafkaBridge
metadata:
name: my-bridge
spec:
# ...
http:
port: 8080
cors:
allowedOrigins: "https://strimzi.io"
allowedMethods: "GET,POST,PUT,DELETE,OPTIONS,PATCH"
# ...As well as enabling HTTP access to a Kafka cluster, HTTP properties provide the capability to enable and define access control for the HTTP Bridge through Cross-Origin Resource Sharing (CORS). CORS is a HTTP mechanism that allows browser access to selected resources from more than one origin. To configure CORS, you define a list of allowed resource origins and HTTP access methods. For the origins, you can use a URL or a Java regular expression.
114.1. KafkaBridgeHttpConfig schema properties
| Property | Property type | Description |
|---|---|---|
port |
integer |
Port the server listens on. |
tls |
TLS configuration for clients connections to the HTTP Bridge. |
|
cors |
CORS configuration for the HTTP Bridge. |
115. KafkaBridgeHttpTls schema reference
Used in: KafkaBridgeHttpConfig
| Property | Property type | Description |
|---|---|---|
certificateAndKey |
Reference to the |
|
config |
map |
Additional configuration for the HTTP server TLS. Properties with the following prefixes cannot be set: ssl. (with the exception of: ssl.enabled.cipher.suites, ssl.enabled.protocols). |
116. KafkaBridgeHttpCors schema reference
Used in: KafkaBridgeHttpConfig
| Property | Property type | Description |
|---|---|---|
allowedOrigins |
string array |
List of allowed origins. Java regular expressions can be used. |
allowedMethods |
string array |
List of allowed HTTP methods. |
117. KafkaBridgeAdminClientSpec schema reference
Used in: KafkaBridgeSpec
| Property | Property type | Description |
|---|---|---|
config |
map |
The Kafka AdminClient configuration used for AdminClient instances created by the bridge. |
118. KafkaBridgeConsumerSpec schema reference
Used in: KafkaBridgeSpec
Configures consumer options for the HTTP Bridge.
Example HTTP Bridge consumer configuration
apiVersion: kafka.strimzi.io/v1
kind: KafkaBridge
metadata:
name: my-bridge
spec:
# ...
consumer:
enabled: true
timeoutSeconds: 60
config:
auto.offset.reset: earliest
enable.auto.commit: true
# ...Use the consumer.config properties to configure Kafka options for the consumer as keys.
The values can be one of the following JSON types:
-
String
-
Number
-
Boolean
Exceptions
You can specify and configure the options listed in the Apache Kafka configuration documentation for consumers.
However, Strimzi takes care of configuring and managing options related to the following, which cannot be changed:
-
Kafka cluster bootstrap address
-
Security (encryption, authentication, and authorization)
-
Consumer group identifier
Properties with the following prefixes cannot be set:
-
bootstrap.servers -
group.id -
sasl. -
security. -
ssl.
If the config property contains an option that cannot be changed, it is disregarded, and a warning message is logged to the Cluster Operator log file.
All other supported options are forwarded to HTTP Bridge, including the following exceptions to the options configured by Strimzi:
-
Any
sslconfiguration for supported TLS versions and cipher suites
|
Important
|
The Cluster Operator does not validate keys or values in the config object.
If an invalid configuration is provided, the HTTP Bridge deployment might not start or might become unstable.
In this case, fix the configuration so that the Cluster Operator can roll out the new configuration to all HTTP Bridge nodes.
|
118.1. KafkaBridgeConsumerSpec schema properties
| Property | Property type | Description |
|---|---|---|
enabled |
boolean |
Whether the HTTP consumer should be enabled or disabled. The default is enabled ( |
timeoutSeconds |
integer |
The timeout in seconds for deleting inactive consumers, default is -1 (disabled). |
config |
map |
The Kafka consumer configuration used for consumer instances created by the bridge. Properties with the following prefixes cannot be set: ssl., bootstrap.servers, group.id, sasl., security. (with the exception of: ssl.endpoint.identification.algorithm, ssl.cipher.suites, ssl.protocol, ssl.enabled.protocols). |
119. KafkaBridgeProducerSpec schema reference
Used in: KafkaBridgeSpec
Configures producer options for the HTTP Bridge.
Example HTTP Bridge producer configuration
apiVersion: kafka.strimzi.io/v1
kind: KafkaBridge
metadata:
name: my-bridge
spec:
# ...
producer:
enabled: true
config:
acks: 1
delivery.timeout.ms: 300000
# ...Use the producer.config properties to configure Kafka options for the producer as keys.
The values can be one of the following JSON types:
-
String
-
Number
-
Boolean
Exceptions
You can specify and configure the options listed in the Apache Kafka configuration documentation for producers.
However, Strimzi takes care of configuring and managing options related to the following, which cannot be changed:
-
Kafka cluster bootstrap address
-
Security (encryption, authentication, and authorization)
-
Consumer group identifier
Properties with the following prefixes cannot be set:
-
bootstrap.servers -
sasl. -
security. -
ssl.
If the config property contains an option that cannot be changed, it is disregarded, and a warning message is logged to the Cluster Operator log file.
All other supported options are forwarded to HTTP Bridge, including the following exceptions to the options configured by Strimzi:
-
Any
sslconfiguration for supported TLS versions and cipher suites
|
Important
|
The Cluster Operator does not validate the keys or values of config properties.
If an invalid configuration is provided, the HTTP Bridge deployment might not start or might become unstable.
In this case, fix the configuration so that the Cluster Operator can roll out the new configuration to all HTTP Bridge nodes.
|
119.1. KafkaBridgeProducerSpec schema properties
| Property | Property type | Description |
|---|---|---|
enabled |
boolean |
Whether the HTTP producer should be enabled or disabled. The default is enabled ( |
config |
map |
The Kafka producer configuration used for producer instances created by the bridge. Properties with the following prefixes cannot be set: ssl., bootstrap.servers, sasl., security. (with the exception of: ssl.endpoint.identification.algorithm, ssl.cipher.suites, ssl.protocol, ssl.enabled.protocols). |
120. KafkaBridgeTemplate schema reference
Used in: KafkaBridgeSpec
| Property | Property type | Description |
|---|---|---|
deployment |
Template for HTTP Bridge |
|
pod |
Template for HTTP Bridge |
|
apiService |
Template for HTTP Bridge API |
|
podDisruptionBudget |
Template for HTTP Bridge |
|
bridgeContainer |
Template for the HTTP Bridge container. |
|
clusterRoleBinding |
Template for the HTTP Bridge ClusterRoleBinding. |
|
serviceAccount |
Template for the HTTP Bridge service account. |
|
initContainer |
Template for the HTTP Bridge init container. |
121. KafkaBridgeStatus schema reference
Used in: KafkaBridge
| Property | Property type | Description |
|---|---|---|
conditions |
|
List of status conditions. |
observedGeneration |
integer |
The generation of the CRD that was last reconciled by the operator. |
url |
string |
The URL at which external client applications can access the HTTP Bridge. |
replicas |
integer |
The current number of pods being used to provide this resource. |
labelSelector |
string |
Label selector for pods providing this resource. |
122. KafkaConnector schema reference
| Property | Property type | Description |
|---|---|---|
spec |
The specification of the Kafka Connector. |
|
status |
The status of the Kafka Connector. |
123. KafkaConnectorSpec schema reference
Used in: KafkaConnector
| Property | Property type | Description |
|---|---|---|
class |
string |
The Class for the Kafka Connector. |
tasksMax |
integer |
The maximum number of tasks for the Kafka Connector. |
autoRestart |
Automatic restart of connector and tasks configuration. |
|
version |
string |
Desired version or version range to respect when starting the Kafka Connector. This is only supported when using Kafka Connect version 4.1.0 and higher. |
config |
map |
The Kafka Connector configuration. The following properties cannot be set: name, connector.class, tasks.max, connector.plugin.version. |
state |
string (one of [running, paused, stopped]) |
The state the connector should be in. Defaults to running. |
listOffsets |
Configuration for listing offsets. |
|
alterOffsets |
Configuration for altering offsets. |
124. AutoRestart schema reference
Configures automatic restarts for connectors and tasks that are in a FAILED state.
When enabled, a back-off algorithm applies the automatic restart to each failed connector and its tasks.
An incremental back-off interval is calculated using the formula n * n + n where n represents the number of previous restarts.
This interval is capped at a maximum of 60 minutes.
Consequently, a restart occurs immediately, followed by restarts after 2, 6, 12, 20, 30, 42, 56 minutes, and then at 60-minute intervals.
The restart counter is automatically reset once the connector has been running continuously for longer than the next backoff interval.
For example, if the connector has restarted 4 times, it must run without errors for 20 minutes before the restart count resets to 0.
By default, Strimzi initiates restarts of the connector and its tasks indefinitely.
However, you can use the maxRestarts property to set a maximum on the number of restarts.
If maxRestarts is configured and the connector still fails even after the final restart attempt, you must then restart the connector manually.
For Kafka Connect connectors, use the autoRestart property of the KafkaConnector resource to enable automatic restarts of failed connectors and tasks.
Enabling automatic restarts of failed connectors for Kafka Connect
apiVersion: kafka.strimzi.io/v1
kind: KafkaConnector
metadata:
name: my-source-connector
spec:
autoRestart:
enabled: trueIf you prefer, you can also set a maximum limit on the number of restarts.
Enabling automatic restarts of failed connectors for Kafka Connect with limited number of restarts
apiVersion: kafka.strimzi.io/v1
kind: KafkaConnector
metadata:
name: my-source-connector
spec:
autoRestart:
enabled: true
maxRestarts: 10For MirrorMaker 2, use the autoRestart property of connectors in the KafkaMirrorMaker2 resource to enable automatic restarts of failed connectors and tasks.
Enabling automatic restarts of failed connectors for MirrorMaker 2
apiVersion: kafka.strimzi.io/v1
kind: KafkaMirrorMaker2
metadata:
name: my-mm2-cluster
spec:
mirrors:
- sourceConnector:
autoRestart:
enabled: true
# ...
checkpointConnector:
autoRestart:
enabled: true
# ...124.1. AutoRestart schema properties
| Property | Property type | Description |
|---|---|---|
enabled |
boolean |
Whether automatic restart for failed connectors and tasks should be enabled or disabled. |
maxRestarts |
integer |
The maximum number of connector restarts that the operator will try. If the connector remains in a failed state after reaching this limit, it must be restarted manually by the user. Defaults to an unlimited number of restarts. |
125. ListOffsets schema reference
| Property | Property type | Description |
|---|---|---|
toConfigMap |
Reference to the ConfigMap where the list of offsets will be written to. |
126. AlterOffsets schema reference
| Property | Property type | Description |
|---|---|---|
fromConfigMap |
Reference to the ConfigMap where the new offsets are stored. |
127. KafkaConnectorStatus schema reference
Used in: KafkaConnector
| Property | Property type | Description |
|---|---|---|
conditions |
|
List of status conditions. |
observedGeneration |
integer |
The generation of the CRD that was last reconciled by the operator. |
autoRestart |
The auto restart status. |
|
connectorStatus |
map |
The connector status, as reported by the Kafka Connect REST API. |
tasksMax |
integer |
The maximum number of tasks for the Kafka Connector. |
topics |
string array |
The list of topics used by the Kafka Connector. |
128. AutoRestartStatus schema reference
Used in: KafkaConnectorStatus, KafkaMirrorMaker2Status
| Property | Property type | Description |
|---|---|---|
count |
integer |
The number of times the connector or task is restarted. |
connectorName |
string |
The name of the connector being restarted. |
lastRestartTimestamp |
string |
The last time the automatic restart was attempted. The required format is 'yyyy-MM-ddTHH:mm:ssZ' in the UTC time zone. |
129. KafkaMirrorMaker2 schema reference
| Property | Property type | Description |
|---|---|---|
spec |
The specification of the Kafka MirrorMaker 2 cluster. |
|
status |
The status of the Kafka MirrorMaker 2 cluster. |
130. KafkaMirrorMaker2Spec schema reference
Used in: KafkaMirrorMaker2
| Property | Property type | Description |
|---|---|---|
version |
string |
The Kafka Connect version. Defaults to the latest version. Consult the user documentation to understand the process required to upgrade or downgrade the version. |
replicas |
integer |
The number of pods in the Kafka Connect group. Required in the |
image |
string |
The container image used for Kafka Connect pods. If no image name is explicitly specified, it is determined based on the |
target |
The target Apache Kafka cluster. The target Kafka cluster is used by the underlying Kafka Connect framework for its internal topics. |
|
mirrors |
Configuration of the MirrorMaker 2 connectors. |
|
resources |
The maximum limits for CPU and memory resources and the requested initial resources. |
|
livenessProbe |
Pod liveness checking. |
|
readinessProbe |
Pod readiness checking. |
|
jvmOptions |
JVM Options for pods. |
|
jmxOptions |
JMX Options. |
|
logging |
Logging configuration for Kafka Connect. |
|
clientRackInitImage |
string |
The image of the init container used for initializing the |
rack |
Configuration of the node label which will be used as the |
|
metricsConfig |
Metrics configuration. |
|
tracing |
The configuration of tracing in Kafka Connect. |
|
template |
Template for Kafka Connect and Kafka MirrorMaker 2 resources. The template allows users to specify how the |
131. KafkaMirrorMaker2TargetClusterSpec schema reference
Used in: KafkaMirrorMaker2Spec
Configures the target Apache Kafka cluster for a MirrorMaker 2 deployment. The target Kafka cluster is used by the underlying Kafka Connect framework for its internal topics.
131.1. Group ID and internal topics
The group ID and the internal topics used by the Kafka Connect cluster are configured in the .spec.target section of the KafkaMirrorMaker2 resource.
These properties are required.
Example group ID and internal topics configuration
apiVersion: kafka.strimzi.io/v1
kind: KafkaMirrorMaker2
metadata:
name: my-mirrormaker-2
spec:
# ...
target:
# ...
groupId: my-connect-group
configStorageTopic: my-config-topic
offsetStorageTopic: my-offset-topic
statusStorageTopic: my-status-topic
# ...131.2. Additional configuration
Use the config properties to configure Kafka options, restricted to those properties not managed directly by Strimzi.
For client connection using a specific cipher suite for a TLS version, you can configure allowed ssl properties.
You can also configure the ssl.endpoint.identification.algorithm property to enable or disable hostname verification.
Example target cluster configuration
apiVersion: kafka.strimzi.io/v1
kind: KafkaMirrorMaker2
metadata:
name: my-mirrormaker-2
spec:
# ...
target:
# ...
config:
config.storage.replication.factor: -1
offset.storage.replication.factor: -1
status.storage.replication.factor: -1
# ...131.3. KafkaMirrorMaker2TargetClusterSpec schema properties
| Property | Property type | Description |
|---|---|---|
alias |
string |
Alias used to reference the Kafka cluster. |
bootstrapServers |
string |
A comma-separated list of |
groupId |
string |
A unique ID that identifies the Connect cluster group. Required. |
configStorageTopic |
string |
The name of the Kafka topic where connector configurations are stored. Required. |
statusStorageTopic |
string |
The name of the Kafka topic where connector and task statuses are stored. Required. |
offsetStorageTopic |
string |
The name of the Kafka topic where source connector offsets are stored. Required. |
tls |
TLS configuration for connecting MirrorMaker 2 connectors to a cluster. |
|
authentication |
|
Authentication configuration for connecting to the cluster. |
config |
map |
The MirrorMaker 2 cluster config. Properties with the following prefixes cannot be set: group.id, config.storage.topic, offset.storage.topic, status.storage.topic, ssl., sasl., security., listeners, plugin.path, rest., bootstrap.servers, consumer.interceptor.classes, producer.interceptor.classes (with the exception of: ssl.endpoint.identification.algorithm, ssl.cipher.suites, ssl.protocol, ssl.enabled.protocols). |
132. KafkaMirrorMaker2MirrorSpec schema reference
Used in: KafkaMirrorMaker2Spec
| Property | Property type | Description |
|---|---|---|
source |
The source Apache Kafka cluster. The source Kafka cluster is used by the Kafka MirrorMaker 2 connectors. |
|
sourceConnector |
The specification of the Kafka MirrorMaker 2 source connector. |
|
checkpointConnector |
The specification of the Kafka MirrorMaker 2 checkpoint connector. |
|
topicsPattern |
string |
A regular expression matching the topics to be mirrored, for example, "topic1|topic2|topic3". Comma-separated lists are also supported. |
topicsExcludePattern |
string |
A regular expression matching the topics to exclude from mirroring. Comma-separated lists are also supported. |
groupsPattern |
string |
A regular expression matching the consumer groups to be mirrored. Comma-separated lists are also supported. |
groupsExcludePattern |
string |
A regular expression matching the consumer groups to exclude from mirroring. Comma-separated lists are also supported. |
133. KafkaMirrorMaker2ClusterSpec schema reference
Used in: KafkaMirrorMaker2MirrorSpec
Configures Kafka clusters for mirroring.
Use the config properties to configure Kafka options, restricted to those properties not managed directly by Strimzi.
For client connection using a specific cipher suite for a TLS version, you can configure allowed ssl properties.
You can also configure the ssl.endpoint.identification.algorithm property to enable or disable hostname verification.
133.1. KafkaMirrorMaker2ClusterSpec schema properties
| Property | Property type | Description |
|---|---|---|
alias |
string |
Alias used to reference the Kafka cluster. |
bootstrapServers |
string |
A comma-separated list of |
tls |
TLS configuration for connecting MirrorMaker 2 connectors to a cluster. |
|
authentication |
|
Authentication configuration for connecting to the cluster. |
config |
map |
The MirrorMaker 2 cluster config. Properties with the following prefixes cannot be set: group.id, config.storage.topic, offset.storage.topic, status.storage.topic, ssl., sasl., security., listeners, plugin.path, rest., bootstrap.servers, consumer.interceptor.classes, producer.interceptor.classes (with the exception of: ssl.endpoint.identification.algorithm, ssl.cipher.suites, ssl.protocol, ssl.enabled.protocols). |
134. KafkaMirrorMaker2ConnectorSpec schema reference
Used in: KafkaMirrorMaker2MirrorSpec
| Property | Property type | Description |
|---|---|---|
tasksMax |
integer |
The maximum number of tasks for the Kafka Connector. |
version |
string |
Desired version or version range to respect when starting the Kafka Connector. This is only supported when using Kafka Connect version 4.1.0 and higher. |
config |
map |
The Kafka Connector configuration. The following properties cannot be set: name, connector.class, tasks.max, connector.plugin.version. |
state |
string (one of [running, paused, stopped]) |
The state the connector should be in. Defaults to running. |
autoRestart |
Automatic restart of connector and tasks configuration. |
|
listOffsets |
Configuration for listing offsets. |
|
alterOffsets |
Configuration for altering offsets. |
135. KafkaMirrorMaker2Status schema reference
Used in: KafkaMirrorMaker2
| Property | Property type | Description |
|---|---|---|
conditions |
|
List of status conditions. |
observedGeneration |
integer |
The generation of the CRD that was last reconciled by the operator. |
url |
string |
The URL of the REST API endpoint for managing and monitoring Kafka Connect connectors. |
connectors |
map array |
List of MirrorMaker 2 connector statuses, as reported by the Kafka Connect REST API. |
autoRestartStatuses |
|
List of MirrorMaker 2 connector auto restart statuses. |
connectorPlugins |
|
The list of connector plugins available in this Kafka Connect deployment. |
labelSelector |
string |
Label selector for pods providing this resource. |
replicas |
integer |
The current number of pods being used to provide this resource. |
136. KafkaRebalance schema reference
| Property | Property type | Description |
|---|---|---|
spec |
The specification of the Kafka rebalance. |
|
status |
The status of the Kafka rebalance. |
137. KafkaRebalanceSpec schema reference
Used in: KafkaRebalance
| Property | Property type | Description |
|---|---|---|
mode |
string (one of [remove-disks, remove-brokers, full, add-brokers]) |
Mode to run the rebalancing. The supported modes are
|
brokers |
integer array |
The list of newly added brokers in case of scaling up or the ones to be removed in case of scaling down to use for rebalancing. This list can be used only with rebalancing mode |
goals |
string array |
A list of goals, ordered by decreasing priority, to use for generating and executing the rebalance proposal. The supported goals are available at https://github.com/linkedin/cruise-control#goals. If an empty goals list is provided, the goals declared in the default.goals Cruise Control configuration parameter are used. |
skipHardGoalCheck |
boolean |
Whether to allow the hard goals specified in the Kafka CR to be skipped in optimization proposal generation. This can be useful when some of those hard goals are preventing a balance solution being found. Default is false. |
rebalanceDisk |
boolean |
Enables intra-broker disk balancing, which balances disk space utilization between disks on the same broker. Only applies to Kafka deployments that use JBOD storage with multiple disks. When enabled, inter-broker balancing is disabled. Default is false. |
excludedTopics |
string |
A regular expression where any matching topics will be excluded from the calculation of optimization proposals. This expression will be parsed by the java.util.regex.Pattern class; for more information on the supported format consult the documentation for that class. |
concurrentPartitionMovementsPerBroker |
integer |
The upper bound of ongoing partition replica movements going into/out of each broker. Default is 5. |
concurrentIntraBrokerPartitionMovements |
integer |
The upper bound of ongoing partition replica movements between disks within each broker. Default is 2. |
concurrentLeaderMovements |
integer |
The upper bound of ongoing partition leadership movements. Default is 1000. |
replicationThrottle |
integer |
The upper bound, in bytes per second, on the bandwidth used to move replicas. There is no limit by default. |
replicaMovementStrategies |
string array |
A list of strategy class names used to determine the execution order for the replica movements in the generated optimization proposal. By default BaseReplicaMovementStrategy is used, which will execute the replica movements in the order that they were generated. |
moveReplicasOffVolumes |
|
List of brokers and their corresponding volumes from which replicas need to be moved. |
138. BrokerAndVolumeIds schema reference
Used in: KafkaRebalanceSpec
| Property | Property type | Description |
|---|---|---|
brokerId |
integer |
ID of the broker that contains the disk from which you want to move the partition replicas. |
volumeIds |
integer array |
IDs of the disks from which the partition replicas need to be moved. |
139. KafkaRebalanceStatus schema reference
Used in: KafkaRebalance
| Property | Property type | Description |
|---|---|---|
conditions |
|
List of status conditions. |
observedGeneration |
integer |
The generation of the CRD that was last reconciled by the operator. |
sessionId |
string |
The session identifier for requests to Cruise Control pertaining to this KafkaRebalance resource. This is used by the Kafka Rebalance operator to track the status of ongoing rebalancing operations. |
progress |
A reference to Config Map with the progress information. |
|
optimizationResult |
map |
A JSON object describing the optimization result. |
140. KafkaRebalanceProgress schema reference
Used in: KafkaRebalanceStatus
| Property | Property type | Description |
|---|---|---|
rebalanceProgressConfigMap |
string |
The name of the |
141. KafkaNodePool schema reference
| Property | Property type | Description |
|---|---|---|
spec |
The specification of the KafkaNodePool. |
|
status |
The status of the KafkaNodePool. |
142. KafkaNodePoolSpec schema reference
Used in: KafkaNodePool
| Property | Property type | Description |
|---|---|---|
replicas |
integer |
The number of pods in the pool. |
storage |
Storage configuration (disk). Cannot be updated. |
|
roles |
string (one or more of [controller, broker]) array |
The roles assigned to the node pool. Supported values are |
resources |
CPU and memory resources to reserve. |
|
jvmOptions |
JVM Options for pods. |
|
template |
Template for pool resources. The template allows users to specify how the resources belonging to this pool are generated. |
143. EphemeralStorage schema reference
Used in: JbodStorage, KafkaNodePoolSpec
The type property is a discriminator that distinguishes use of the EphemeralStorage type from PersistentClaimStorage.
It must have the value ephemeral for the type EphemeralStorage.
| Property | Property type | Description |
|---|---|---|
id |
integer |
Storage identification number. It is mandatory only for storage volumes defined in a storage of type 'jbod'. |
sizeLimit |
string |
When type=ephemeral, defines the total amount of local storage required for this EmptyDir volume (for example 1Gi). |
type |
string |
Must be |
kraftMetadata |
string (one of [shared]) |
Specifies whether this volume should be used for storing KRaft metadata. This property is optional. When set, the only currently supported value is |
144. PersistentClaimStorage schema reference
Used in: JbodStorage, KafkaNodePoolSpec
The type property is a discriminator that distinguishes use of the PersistentClaimStorage type from EphemeralStorage.
It must have the value persistent-claim for the type PersistentClaimStorage.
| Property | Property type | Description |
|---|---|---|
id |
integer |
Storage identification number. It is mandatory only for storage volumes defined in a storage of type 'jbod'. |
type |
string |
Must be |
size |
string |
When |
kraftMetadata |
string (one of [shared]) |
Specifies whether this volume should be used for storing KRaft metadata. This property is optional. When set, the only currently supported value is |
class |
string |
The storage class to use for dynamic volume allocation. |
volumeAttributesClass |
string |
Specifies |
selector |
map |
Specifies a specific persistent volume to use. It contains key:value pairs representing labels for selecting such a volume. |
deleteClaim |
boolean |
Specifies whether the persistent volume claim is deleted when a Kafka node is deleted. Optional. Defaults to |
145. JbodStorage schema reference
Used in: KafkaNodePoolSpec
The type property is a discriminator that distinguishes use of the JbodStorage type from EphemeralStorage, PersistentClaimStorage.
It must have the value jbod for the type JbodStorage.
| Property | Property type | Description |
|---|---|---|
type |
string |
Must be |
volumes |
List of volumes as Storage objects representing the JBOD disks array. |
146. KafkaNodePoolTemplate schema reference
Used in: KafkaNodePoolSpec
| Property | Property type | Description |
|---|---|---|
podSet |
Template for Kafka |
|
pod |
Template for Kafka |
|
perPodService |
Template for Kafka per-pod |
|
perPodRoute |
Template for Kafka per-pod |
|
perPodIngress |
Template for Kafka per-pod |
|
persistentVolumeClaim |
Template for all Kafka |
|
kafkaContainer |
Template for the Kafka broker container. |
|
initContainer |
Template for the Kafka init container. |
147. KafkaNodePoolStatus schema reference
Used in: KafkaNodePool
| Property | Property type | Description |
|---|---|---|
conditions |
|
List of status conditions. |
observedGeneration |
integer |
The generation of the CRD that was last reconciled by the operator. |
nodeIds |
integer array |
Node IDs used by Kafka nodes in this pool. |
clusterId |
string |
Kafka cluster ID. |
roles |
string (one or more of [controller, broker]) array |
Added in Strimzi 0.39.0. The roles currently assigned to this pool. |
replicas |
integer |
The current number of pods being used to provide this resource. |
labelSelector |
string |
Label selector for pods providing this resource. |
148. StrimziPodSet schema reference
|
Important
|
StrimziPodSet is an internal Strimzi resource.
Information is provided for reference only.
Do not create, modify or delete StrimziPodSet resources as this might cause errors.
|
148.1. StrimziPodSet schema properties
| Property | Property type | Description |
|---|---|---|
spec |
The specification of the StrimziPodSet. |
|
status |
The status of the StrimziPodSet. |
149. StrimziPodSetSpec schema reference
Used in: StrimziPodSet
| Property | Property type | Description |
|---|---|---|
selector |
Selector is a label query which matches all the pods managed by this |
|
pods |
Map array |
The Pods managed by this StrimziPodSet. |
150. StrimziPodSetStatus schema reference
Used in: StrimziPodSet
| Property | Property type | Description |
|---|---|---|
conditions |
|
List of status conditions. |
observedGeneration |
integer |
The generation of the CRD that was last reconciled by the operator. |
pods |
integer |
Number of pods managed by this |
readyPods |
integer |
Number of pods managed by this |
currentPods |
integer |
Number of pods managed by this |